機械学習を学びはじめると、「転移学習(Transfer Learning)」という言葉をよく目にします。しかし、「ファインチューニングと何が違うのか」「そもそもどういう仕組みなのか」が分かりにくい、と感じる方も多いのではないでしょうか。
この記事では、転移学習の基本的な考え方から、ファインチューニングとの違い、メリット・デメリット、具体的な活用例までを、初心者にもわかりやすく解説します。すでに機械学習に触れたことがある方にとっても、知識を整理するきっかけになる内容です。
転移学習(Transfer Learning)とは?
転移学習とは、あるタスクで学習済みのモデルを、別のタスクに応用する手法です。なぜこの手法が重要かというと、モデルを一から学習させるには、大量のデータと計算コストが必要になるからです。転移学習では、すでに学習が終わったモデル(事前学習済みモデル/pre-trained model)を再利用します。そのため、手元のデータが少なくても、高い精度を出しやすくなります。
例えば、ImageNet という大規模な画像データセットで学習したモデルがあります。このモデルは、「画像から特徴を抽出する力」をすでに身につけています。その力を、犬種の分類や医療画像の判定といった別のタスクに「転用」するのが、転移学習です。
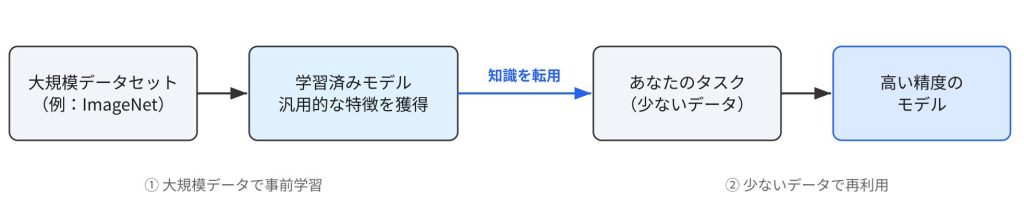
転移学習の仕組み
転移学習は、大きく2つのステップで考えると理解しやすいです
①学習済みモデルを用意する
まず、すでに大規模なデータで学習されたモデルを用意します。このモデルは、画像やテキストの「汎用的な特徴」をとらえる力を持っています。具体的には、画像であれば「輪郭」や「色の変化」、テキストであれば「単語のつながり」などです。
②自分のタスクに合わせて調整する
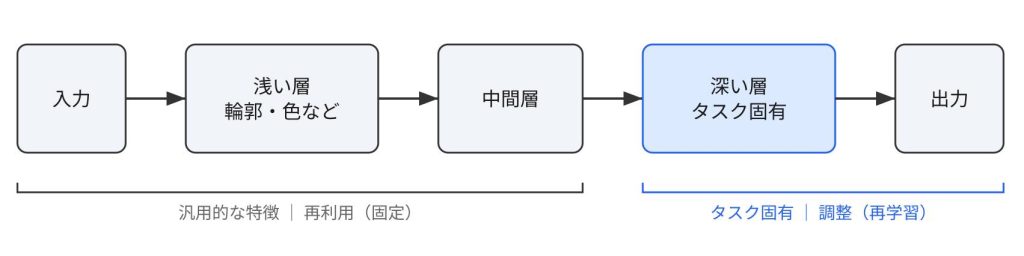
次に、用意したモデルを、自分が解きたいタスクに合わせて調整します。ここでポイントになるのが、ニューラルネットワークの「層(レイヤー)」の役割です。
一般的に、入力に近い浅い層ほど汎用的な特徴を、出力に近い深い層ほどタスク固有の特徴をとらえると言われています。そのため、汎用的な浅い層はそのまま再利用し、タスク固有の深い層だけを作り直す、という考え方が基本になります。
転移学習とファインチューニングの違い
ここがいちばん混同されやすいポイントです。結論から言うと、ファインチューニングは「転移学習の手法の一つ」です。つまり、転移学習という大きな考え方の中に、いくつかのやり方が含まれているイメージです。
代表的なやり方は、次の2つです。
- 特徴抽出(Feature Extraction):学習済みモデルの重みを固定し、最後の分類層だけを付け替えて学習する
- ファインチューニング(Fine-tuning):学習済みモデルの重みも一部(または全部)再学習させ、新しいタスクに最適化する
両者の違いを表にまとめると、次のようになります。
| 項目 | 特徴抽出 | ファインチューニング |
|---|---|---|
| 学習済みモデルの重み | 固定する | 更新する |
| 必要なデータ量 | 少なめ | やや多め |
| 計算コスト | 低い | 高い |
| 精度の伸びしろ | 中くらい | 高くなりやすい |
| 向いている場面 | データが少ない / 元タスクと近い | データがある / 高精度を狙いたい |
データが少ない場合や、元のタスクと近い内容を解きたい場合は、特徴抽出が向いています。一方、ある程度のデータがあり、より高い精度を狙いたい場合は、ファインチューニングが選ばれます。

なお、ファインチューニングの具体的な手順については、〔内部リンク:ファインチューニングのやり方を解説した記事〕でくわしく説明しています。
転移学習のメリット
転移学習には、主に3つのメリットがあります。
少ないデータで学習できる:ゼロから学習する場合と比べて、必要なデータ量を大きく減らせます。 データ収集が難しい医療や製造の分野でも使いやすいのが特徴です。
学習時間・計算コストを削減できる:すでに学習済みの部分を再利用するため、学習にかかる時間とコストを抑えられます。 高価なGPUを長時間使わずに済む点も実務では重要です。
高い精度を出しやすい:大規模データで鍛えられた特徴抽出の力を引き継げるため、少ないデータでも精度が安定しやすくなります。
転移学習のデメリット・注意点
便利な手法ですが、注意すべき点もあります。
元タスクと対象タスクが離れすぎると効果が薄い:学習済みモデルの知識と、解きたいタスクの内容がかけ離れていると、かえって精度が下がることがあります。 これは「負の転移(Negative Transfer)」と呼ばれます。
入力形式やライセンスの制約がある:学習済みモデルには、想定している入力サイズやデータ形式が決まっている場合があります。 また、商用利用が制限されているモデルもあるため、ライセンスの確認は欠かせません。
前処理を合わせる必要がある:元のモデルが学習したときと同じ前処理(正規化など)を、自分のデータにも適用する必要があります。
転移学習の活用例
転移学習は、さまざまな分野で使われています。
- 画像分類:医療画像の診断補助、製造業での外観検査(不良品の検出)など
- 物体検出・多物体追跡:学習済みの検出モデルをベースに、特定の対象を追跡するタスクへ応用
- 自然言語処理:BERT や GPT 系のような大規模な事前学習モデルを、文章分類や要約などに応用
- 音声認識:汎用的な音声モデルを、特定の話者や用途に合わせて調整
このように、「データを集めにくい」「精度をすぐに出したい」という場面で、転移学習は特に力を発揮します。
まとめ
最後に、この記事のポイントを整理します。
- 転移学習とは、学習済みモデルの知識を別のタスクに応用する手法
- 仕組みは「①学習済みモデルを用意する → ②自分のタスクに合わせて調整する」の2ステップ
- ファインチューニングは、転移学習の手法の一つ(重みも再学習させるやり方)
- メリットは「少ないデータ・低コスト・高精度」、注意点は「負の転移」や「ライセンス」
- 画像・自然言語・音声など、幅広い分野で活用されている
転移学習を理解しておくと、限られたデータでも実用的なモデルを作りやすくなります。まずは、公式チュートリアルなどで、学習済みモデルを実際に動かしてみることをおすすめします。
参考:
- PyTorch公式|Transfer Learning for Computer Vision Tutorial
https://docs.pytorch.org/tutorials/beginner/transfer_learning_tutorial.html