
大規模言語モデル(LLM)は、生成AIの中核技術として急速に進化しており、GPT・Gemini・Claude・DeepSeek・Qwenなど、選択肢は年々増えています。
しかし、実際のLLM選定では、「どのモデルが一番高性能か」だけでなく、用途・コスト・提供形態(API/ローカル)・日本語性能まで含めて比較することが大切です。
本記事では、2026年最新のLLM性能比較表をもとに、主要モデルの特徴や性能ランキング、信頼できるLLM比較サイト、ローカルLLMとクラウドLLMの違いまでを網羅的に解説します。LLM導入や比較検討の判断材料として、ぜひ参考にしてください。
LLM性能比較表
LM性能比較表では、主要な大規模言語モデルを同一の評価指標で横断的に比較しています。
ただし、スコアが高い=すべての用途で最適、とは限りません。
モデルごとに得意分野や運用条件(速度・コスト・提供形態)が異なるため、数値の順位だけでなく「どの用途に向くか」を意識し、LLM比較時の参考にしてください。
| LLMモデル名 | サイズ・カテゴリー | 性能総合スコア |
| openai/gpt-5.2-2025-12-11: xhigh-effort | API | 0.829 |
| google/gemini-3-flash-preview | API | 0.816 |
| google/gemini-3-pro-preview | API | 0.813 |
| openai/gpt-5.1-2025-11-13: high-effort | API | 0.808 |
| anthropic/claude-opus-4.5-20251125: extended-thinking | API | 0.806 |
| anthropic/claude-opus-4-1-20250805: extended-thinking | API | 0.799 |
| openai/gpt-5-2025-08-07: high-effort | API | 0.797 |
| anthropic/claude-sonnet-4-5-20250929: extended-thinking | API | 0.795 |
| anthropic/claude-sonnet-4-20250514: extended-thinking | API | 0.792 |
| deepseek/DeepSeek-V3.2 (Thinking Mode) | API | 0.79 |
| deepseek-ai/DeepSeek-V3.2: reasoning-enabled | 大規模モデル(30B+) | 0.789 |
| anthropic/claude-haiku-4-5-20251001: extended-thinking | API | 0.788 |
| openai/o3-2025-04-16: high-effort | API | 0.788 |
| grok-4 | API | 0.781 |
| anthropic/claude-opus-4-20250514: no-thinking | API | 0.78 |
| Qwen/Qwen3-235B-A22B-Thinking-2507: reasoning-enabled | 大規模モデル(30B+) | 0.778 |
| zai-org/GLM-4.7: reasoning-enabled | 大規模モデル(30B+) | 0.777 |
| openai/o1-2024-12-17: high-effort | API | 0.775 |
| anthropic/claude-3.7-sonnet-20250219: extended-thinking | API | 0.773 |
| google/gemini-2.5-pro | API | 0.77 |
| x-ai/grok-4-1-fast-reasoning | API | 0.765 |
| openai/o4-mini-2025-04-16 | API | 0.761 |
| Qwen/Qwen3-Next-80B-A3B-Thinking | 大規模モデル(30B+) | 0.756 |
| deepseek-ai/DeepSeek-R1-0528: reasoning-enabled | 大規模モデル(30B+) | 0.743 |
| openai/o3-mini-2025-01-31 | API | 0.743 |
| Qwen/Qwen3-Max-Preview | API | 0.742 |
| openai/gpt-5.1-2025-11-13: none-effort | API | 0.741 |
| Qwen/Qwen3-VL-32B-Thinking | 大規模モデル(30B+) | 0.741 |
| grok-3-mini | API | 0.737 |
| moonshotai/kimi-k2-thinking | API | 0.733 |
| Qwen/Qwen3-30B-A3B-Thinking-2507: reasoning-enabled | 大規模モデル(30B+) | 0.733 |
| anthropic/claude-opus-4.5-20251125: no-thinking | API | 0.732 |
| upstage-karakuri/syn-pro reasoning | API | 0.727 |
| openai/gpt-4-1-2025-04-14 | API | 0.726 |
| grok-3 | API | 0.725 |
| Qwen/Qwen3-14B: reasoning-enabled | 中規模モデル (10–30B) | 0.723 |
| openai/gpt-4o-2024-11-20 | API | 0.722 |
| Qwen/Qwen3-235B-A22B: reasoning-enabled | 大規模モデル(30B+) | 0.721 |
| LGAI-EXAONE/K-EXAONE-236B-A23B: reasoning-enabled | 大規模モデル(30B+) | 0.719 |
| anthropic/claude-3.7-sonnet-20250219: no-thinking | API | 0.718 |
| openai/gpt-5-nano-2025-08-07: high-effort | API | 0.717 |
| anthropic/claude-sonnet-4-20250514: no-thinking | API | 0.715 |
| Qwen/Qwen3-Next-80B-A3B-Instruct | 大規模モデル(30B+) | 0.713 |
| MiniMaxAI/MiniMax-M2: reasoning-enabled | 大規模モデル(30B+) | 0.713 |
| Qwen/Qwen3-32B: reasoning-enabled | 大規模モデル(30B+) | 0.709 |
| anthropic/claude-3.5-sonnet-20241022 | API | 0.706 |
| zai-org/GLM-4.5-Air | 大規模モデル(30B+) | 0.704 |
| Qwen/Qwen3-30B-A3B: reasoning-enabled | 大規模モデル(30B+) | 0.703 |
| Qwen/QwQ-32B: reasoning-enabled | 大規模モデル(30B+) | 0.703 |
| Qwen/Qwen3-VL-8B-Thinking | 小規模モデル (<10B) | 0.702 |
| openai/gpt-oss-120b: reasoning-enabled | 大規模モデル(30B+) | 0.701 |
| openai/gpt-4-1-mini-2025-04-14 | API | 0.699 |
| google/gemini-2.5-flash | API | 0.697 |
| Qwen/Qwen3-4B-Thinking-2507 | 小規模モデル (<10B) | 0.696 |
| rinna/qwq-bakeneko-32b: reasoning-enabled | 大規模モデル(30B+) | 0.691 |
| Qwen/Qwen3-8B: reasoning-enabled | 小規模モデル (<10B) | 0.69 |
| abeja/ABEJA-Qwen2.5-32b-Japanese-v1.0 | 大規模モデル(30B+) | 0.687 |
| Qwen/Qwen3-VL-4B-Thinking | 小規模モデル (<10B) | 0.677 |
| deepseek-ai/DeepSeek-V3-0324 | 大規模モデル(30B+) | 0.676 |
| elyza/ELYZA-Shortcut-1.0-Qwen-32B | 大規模モデル(30B+) | 0.671 |
| Qwen/Qwen3-4B: reasoning-enabled | 小規模モデル (<10B) | 0.661 |
| rinna/deepseek-r1-distill-qwen2.5-bakeneko-32b: reasoning-enabled | 大規模モデル(30B+) | 0.659 |
| cyberagent/DeepSeek-R1-Distill-Qwen-32B-Japanese | 大規模モデル(30B+) | 0.658 |
| tokyotech-llm/Llama-3.3-Swallow-70B-Instruct-v0.4 | 大規模モデル(30B+) | 0.652 |
| meta-llama/Llama-3.1-405B-Instruct-FP8 | 大規模モデル(30B+) | 0.651 |
| rinna/qwen2.5-bakeneko-32b-instruct-v2 | 大規模モデル(30B+) | 0.649 |
| meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8 | 大規模モデル(30B+) | 0.646 |
| upstage-karakuri/syn-pro | API | 0.646 |
| shisa-ai/shisa-v2-llama3.1-405b | 大規模モデル(30B+) | 0.646 |
| mistralai/Mistral-Large-3-675B-Instruct-2512 | 大規模モデル(30B+) | 0.635 |
| anthropic/claude-3.5-haiku-20241022 | API | 0.63 |
| google/gemma-3-27b-it | 中規模モデル (10–30B) | 0.628 |
| tokyotech-llm/Gemma-2-Llama-Swallow-27b-it-v0.1 | 中規模モデル (10–30B) | 0.621 |
| shisa-ai/shisa-v2-llama3.3-70b | 大規模モデル(30B+) | 0.62 |
| mistral/mistral-large-2411 | API | 0.62 |
| openai/gpt-4-1-nano-2025-04-14 | API | 0.616 |
| openai/gpt-4o-mini-2024-07-18 | API | 0.615 |
| pfn/plamo-2.0-prime | API | 0.613 |
| meta-llama/Llama-4-Scout-17B-16E-Instruct | 大規模モデル(30B+) | 0.61 |
| meta-llama/Llama-3.3-70B-Instruct | 大規模モデル(30B+) | 0.608 |
| google/gemma-3-12b-it | 中規模モデル (10–30B) | 0.599 |
| tokyotech-llm/Gemma-2-Llama-Swallow-9b-it-v0.1 | 小規模モデル (<10B) | 0.598 |
| us.amazon.nova-pro-v1:0 | API | 0.589 |
| mistral/mistral-small-2503 | API | 0.578 |
| Qwen/Qwen3-VL-2B-Thinking | 小規模モデル (<10B) | 0.576 |
| cyberagent/calm3-22b-chat-selfimprove-experimental | 中規模モデル (10–30B) | 0.57 |
| tokyotech-llm/Llama-3.1-Swallow-8B-Instruct-v0.5 | 小規模モデル (<10B) | 0.561 |
| mistralai/Ministral-3-14B-Reasoning-2512 | 中規模モデル (10–30B) | 0.561 |
| us.amazon.nova-lite-v1:0 | API | 0.554 |
| Qwen/Qwen3-1.7B: reasoning-enabled | 小規模モデル (<10B) | 0.553 |
| us.amazon.nova-micro-v1:0 | API | 0.548 |
| google/gemini-2.5-flash-lite | API | 0.548 |
| baidu/ERNIE-4.5-21B-A3B-Thinking | 中規模モデル (10–30B) | 0.547 |
| mistralai/Ministral-3-8B-Reasoning-2512 | 小規模モデル (<10B) | 0.544 |
| google/gemma-3-4b-it | 中規模モデル (10–30B) | 0.533 |
| tokyotech-llm/Gemma-2-Llama-Swallow-2b-it-v0.1 | 小規模モデル (<10B) | 0.491 |
| mistralai/Ministral-3-3B-Reasoning-2512 | 小規模モデル (<10B) | 0.457 |
| Qwen/Qwen3-0.6B: reasoning-enabled | 小規模モデル (<10B) | 0.409 |
| meta-llama/Llama-3.2-3B-Instruct | 小規模モデル (<10B) | 0.404 |
※上記のLLM比較表は、2026年1月27日時点での、Nejumi Leaderboard 4(Weights & Biases Japan社)による総合スコアです。母体は海外法人で、日本法人のWeights & Biases Japan 株式会社は、PRTIMES等のニュースサイトで大手企業との提携なども発信しております。
LLMの性能スコアはあくまで目安であり、実際の業務では用途との相性が重要です。具体的な活用イメージについては、以下の記事も参考になります。
▶関連記事

それでは、主要なLLMについて、それぞれ紹介します。
GPT-5(OpenAI)
GPT-5は「迷ったらまず候補に入る」タイプのLLMです。文章生成だけでなく、推論(筋道立てて考える)・コード生成・タスク分解まで幅広く対応しやすく、業務の汎用モデルとして採用されやすい傾向があります。
また、API経由で既存システムに組み込みやすいため、チャットUIだけでなく「社内ツールの裏側のエンジン」としても使われます。
一方で、同じGPTでもモデルや設定(例:高精度/高速)で挙動が変わるため、速度・コスト・精度の優先順位を決めて使い分ける設計が大切です。
▶関連記事
ChatGPTエージェントとは?ChatGPTのAIエージェントを使ってみた
AIエージェントとは?生成AIとの違い・仕組み・できることをわかりやすく解説
Gemini(Google)
参考:Google Cloud|Gemini 3 を使ってみる: Gemini 3 Flash での Hello World
Geminiは、速度と実務での扱いやすさを重視した運用に向きやすいLLMです。特に、問い合わせ対応や要約など「大量に処理する」「レスポンスを速く返したい」用途で強みが出やすいモデル群です。
また、Google系の環境と相性が良く、組織での導入では「既存のワークフローに自然に組み込む」選定がされやすいです。
モデルの種類(Pro/Flashなど)によって得意領域が変わるため、高精度モデルは重要タスク、軽量モデルは大量処理のように役割分担すると運用しやすくなります。
関連記事:AIエージェントフレームワークとは?【2026年】人気のフレームワークを比較
Claude(Anthropic)
参考:Anthropic|Introducing Claude Opus 4.5
Claudeは、長い文章を読ませて整理する用途で選ばれやすいLLMです。規程・契約・仕様書・議事録など、文書量が多い業務で「読みやすい要約」「丁寧な言い回し」「抜け漏れの少ない整理」に強みが出やすい傾向があります。
また、出力のトーンが落ち着いていて、社内向け文書(社内通知、FAQ、説明資料)の文章品質を整える用途とも相性が良いです。
注意点として、精度や安全性を重視する設計の分、設定やモードによっては処理時間・コストが増えることがあるため、重要度で使い分けると現実的です。
DeepSeek
DeepSeekは、推論(Reasoning)に寄せたモデルが多く、論理性が求められるタスクで候補になりやすいブランドです。たとえば、根拠を踏まえた回答、計算・分析、コードの修正など「考える工程」がある仕事で強みが出やすいです。
また、クラウドAPIだけでなくモデルによってはローカル運用の検討余地もあり、要件によっては「自社環境で動かしたい」「コストを最適化したい」といったニーズに合うことがあります。
ただし、派生モデルやバージョン差が大きいので、ランキングだけで決めず、自社データで小さく検証してから選ぶのが安全です。
Grok(xAI)
参考:xAI|Grok 4
Grokは、会話のテンポと発想支援に寄ったLLMとして使われることが多いです。きっちり正解を出すというより、「案をたくさん出す」「たたき台を早く作る」「壁打ちして方向性を固める」といった探索型タスクで価値が出やすいタイプです。
たとえば、企画の切り口出し、キャッチコピー案、文章トーンの調整、SNS向けの短文案など、スピード優先のアウトプットで使われやすい傾向があります。
一方、業務利用ではセキュリティや管理要件(ログ管理、権限、データの扱い)を満たせるかを先に確認し、適用範囲を決めて使うのが現実的です。
Qwen(アリババ)
参考:Hugging Face|Qwen3-VL-Embedding – a Qwen Collection
Qwenは、ラインナップの広さ(大規模〜小規模、推論対応、派生モデル)が大きな特徴です。用途に応じてサイズを選べるため、「高精度が必要な処理は大きめ」「大量処理は軽量モデル」といったモデルの役割分担を設計しやすいシリーズです。
また、モデルの選択肢が多いことで、コストや速度、実装難易度に合わせて「最適な落としどころ」を作りやすいのも強みです。
注意点として、同じQwenでも世代や派生モデルで得意・不得意が変わるため、比較表のスコアに加えて、自社での実タスク評価(短いPoC)を行うと選定ミスが減ります。
Qwen3は、Hugging Face、GitHub、ModelScopeで無料公開されており、専用チャットサイト(chat.qwen.ai)でも試用可能です。
LLM比較サイト
LLMを比較・検討する際には、単一の性能スコアだけで判断しないようにしましょう。
実際には、評価に使われているベンチマークや指標、測定方法によって、モデルの順位や評価は大きく変わります。
以下、LLMの性能比較に使われるサイトの一覧です。
| 比較サイト名 | 評価の軸(指標/手法) | 強い領域 | 向くユーザー | 向く用途(選定シーン) |
| Nejumi LLM Leaderboard | 複数タスクで総合評価(日本語・実運用観点も重視) | 日本語LLM/日本語性能の横断比較 | 日本語圏の開発者・導入担当 | 日本語でのモデル候補絞り込み |
| Hugging Face Open LLM Leaderboard | 主要ベンチマークを統一フレームワークで評価 | OSS/公開モデルのベンチ比較 | OSS利用者・研究/開発 | オープンモデルの性能比較・選定 |
| ELYZA-tasks-100 | 日本語の指示追従タスク100問(評価観点付き) | 日本語の指示追従/実務的回答 | 日本語LLM開発者 | 日本語instructionモデルの品質チェック |
| Artificial Analysis | 知能/速度/価格など複数指標で比較 | 運用目線(コスト・速度込み) | 導入担当・意思決定者 | 本番運用のモデル選定(費用対効果) |
| AlpacaEval Leaderboard | 指示追従の相対評価(勝率など) | Instruction-followingの比較 | 研究/開発・チューニング担当 | 指示追従モデルの改善/比較 |
| LiveBench | 汚染(contamination)対策を重視したベンチ | “新しめ”で客観評価を狙う | 研究/開発・評価担当 | ベンチ汚染を避けて実力比較 |
それぞれの比較サイトについて、紹介します。
実運用での使われ方については「AIエージェントの事例15選」もあわせて確認すると理解が深まります。
▶関連記事
- AIエージェントの種類とは?複数の種類を役割で組み合わせる階層型・マルチエージェントと企業事例
- AIエージェントの事例15選!日本国内企業の活用例と成功事例
Nejumi LLM Leaderboard

日本語を含む観点でLLMを評価し、モデル選定に使える形でランキング化しているリーダーボードです。日本語圏の開発・導入で「まず日本語性能を横断比較したい」場合に便利です。
Hugging Face Open LLM Leaderboard
出典:Hugging Face Open LLM Leaderboard
オープン(公開)LLMを対象に、複数ベンチマークを統一手法で計測して比較できる定番のリーダーボードです。OSSモデル同士を公平に見たいときの基準になります。
ELYZA-tasks-100
出典:Hugging Face|ELYZA-tasks-100
日本語の指示追従モデルを評価するための100問データセットで、採点観点が付いているのが強みです。日本語instructionモデルの品質チェックや改善に使われます。
Artificial Analysis
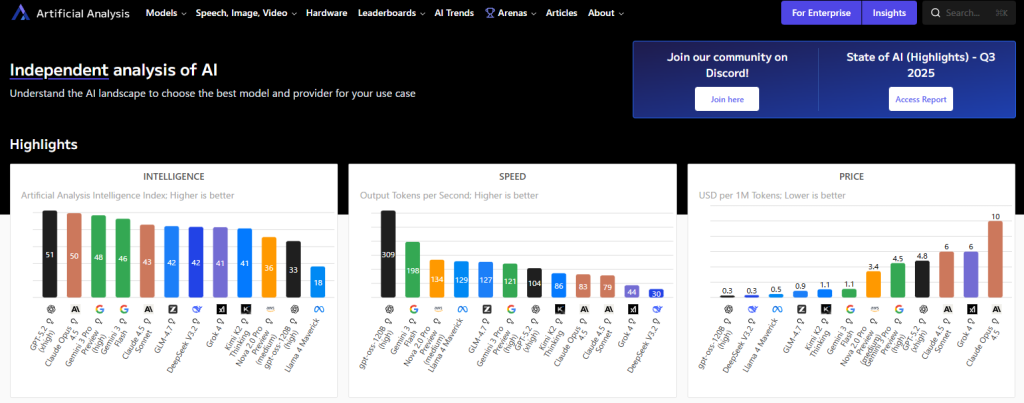
多数のモデルを、知能(能力)だけでなく速度や価格も含めて比較できるサイトです。「精度が高いけど高い」など、運用の現実を含めて判断したいときに向きます。
AlpacaEval Leaderboard
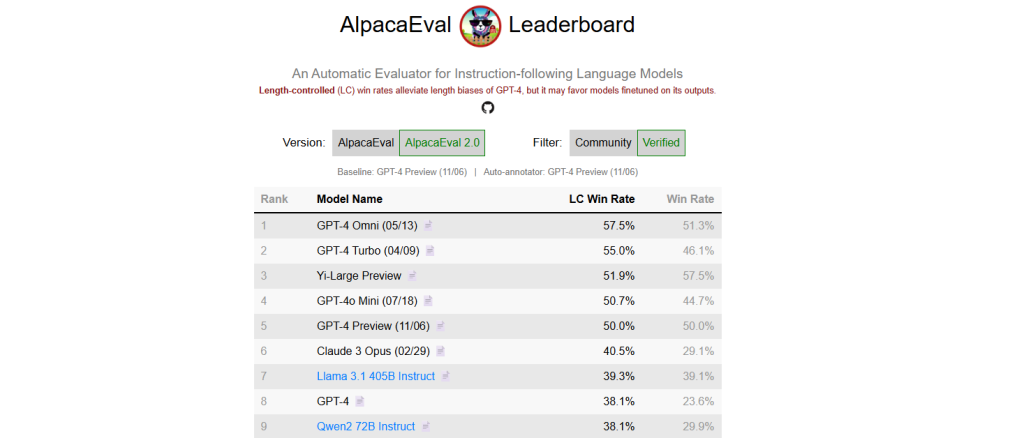
指示追従(instruction-following)に焦点を当て、相対評価(勝率など)でモデルを比較する仕組みです。チューニングやモデル改善の比較指標として使われやすいです。
LiveBench
出典:LiveBench
テスト汚染(学習済みでスコアが上がる問題)を避けることを重視して設計されたベンチマークです。「より客観的に、最新モデルの実力を測りたい」方向けの指標になります。
ローカルLLMとクラウドLLMの比較
LLMは、どこでモデルを実行するか(実行環境)によって「ローカルLLM」と「クラウドLLM」に大きく分けられます。
クラウドLLMはインターネットを介して外部のクラウドサーバ上で実行される一方で、ローカルLLMは企業内サーバや個別デバイス上で直接実行されます。
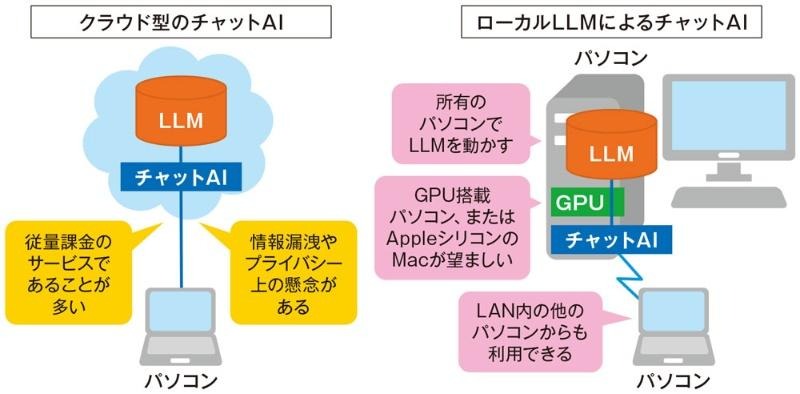
出典:日経クロステック|驚くほど簡単に使えるローカルLLM、ChatGPT風Webサイトも簡単
それぞれの違いについて、紹介します。
| 比較項目 | ローカルLLM | クラウドLLM |
|---|---|---|
| 実行環境 | 自社サーバ・オンプレミス・ローカル端末 | 外部クラウドサーバ |
| インターネット接続 | 不要(オフライン可) | 必須 |
| データの送信先 | 自社ネットワーク内で完結 | 外部クラウド(インターネット経由) |
| セキュリティ | 物理的・ネットワーク的に隔離可能 | 暗号化通信・ベンダー管理が前提 |
| カスタマイズ性 | モデル選定・調整の自由度が高い | プロンプト調整が中心 |
| 導入の手軽さ | 環境構築が必要 | 非常に高い(すぐ利用可能) |
| コスト構造 | 初期投資は高いが長期利用で抑えやすい | 従量課金・月額課金が中心 |
| 向いている業界 | 金融・医療・官公庁・研究機関 | 一般企業・スタートアップ・SaaS |
▶関連記事
- RPAとAIの違いは?向いている業務・活用例・ツール選びと注意点
- 【事例あり】自動化AIツール比較20選!AIで自動化できる業務とは?【2026年最新】
ローカルLLMとは?
ローカルLLMとは、クラウドサービスを使わず、自社が管理する環境で直接実行する大規模言語モデルのことです。
企業内サーバやオンプレミス環境、場合によっては個別のデバイス上で動作します。
最大の特徴は、データを外部に送信せず、処理をすべて社内で完結できる点です。
そのため、顧客情報・医療データ・社内文書など、機密性の高い情報を扱う業務で採用が進んでいます。
- インターネット接続が不要で、オフライン環境でも利用可能
- データが外部に出ないため、情報漏えいリスクを大幅に低減できる
- モデルや設定を自社要件に合わせて細かく制御できる
一方で、GPUなどの計算資源や運用体制が必要になるため、導入・運用の難易度は高めという点が判断ポイントになります。
クラウドLLMとは?
クラウドLLMとは、外部ベンダーが提供するクラウドサーバ上のLLMを、APIやWeb経由で利用する方式です。
代表的な例として、ChatGPT や Claude などが挙げられます。
最大の強みは、高性能なモデルをすぐに使い始められる手軽さです。
インフラ構築は不要で、APIを呼び出すだけで業務に組み込むことができます。
- 初期コストが低く、PoCや試験導入がしやすい
- 常に最新・高性能なモデルを利用できる
- 運用やスケールを意識せずに使える
ただし、入力データはインターネット経由で外部に送信されるため、
データの取り扱いポリシーやセキュリティ要件の確認が不可欠です。
LLMを比較するときによくある質問
LLMを比較するときによくある質問をまとめています。
ファインチューニングとは何ですか?
ファインチューニングとは、既存のLLMを特定の用途や業務データに合わせて追加学習させることです。あらかじめ学習済みのモデルに、社内文書や業務特有のデータを与えることで、専門用語への理解や回答精度を高められます。
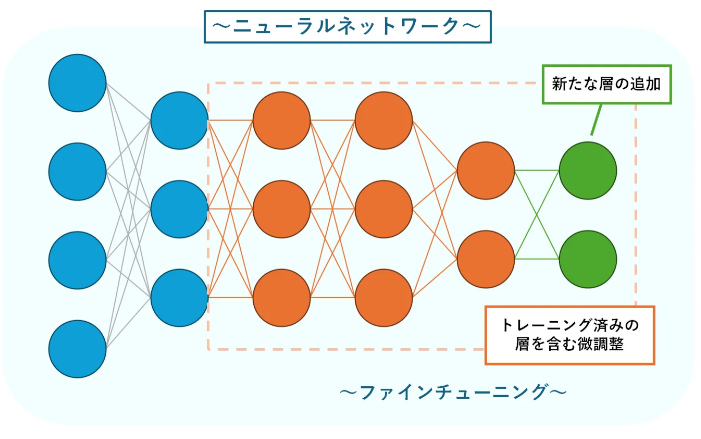
出典:Sky株式会社|ファインチューニングとは? 仕組みや実施手順をわかりやすく解説
カスタマーサポートや業界特化AIなど、汎用モデルを実務向けに最適化したい場合によく使われます。
ハルシネーションとは何ですか?
ハルシネーションとは、LLMが事実ではない内容を、あたかも正しい情報のように生成してしまう現象です。
モデルは文章の確からしさを重視して出力するため、知識が不十分な場合でも自信のある表現で誤情報を出すことがあります。
業務利用では、根拠確認・RAGの併用・重要情報の人手チェックなどの対策が重要です。
▶関連記事
RAGとAIエージェントの違いは?生成AI×RAGの活用事例や組み合わせてできること
MCPとは?生成AI・AIエージェントの連携に必要な共通プロトコルをわかりやすく解説
オープンソースLLM(OSS)とは何ですか?
オープンソースLLM(OSS)とは、モデルの重みやコードが公開され、自由に利用・改変できるLLMのことです。
自社環境での実行やカスタマイズが可能なため、コスト最適化やデータ管理を重視する企業で利用が進んでいる一方で、運用やチューニングは自社責任となるため、技術力や検証体制が必要です。
LLMとNLP(自然言語処理)の違いは何ですか?
NLP(自然言語処理)は、コンピュータで人の言葉を扱うための技術分野全体を指します。
一方、LLMはNLP技術を基盤として、大量のテキストデータを学習した大規模な言語モデルのことです。
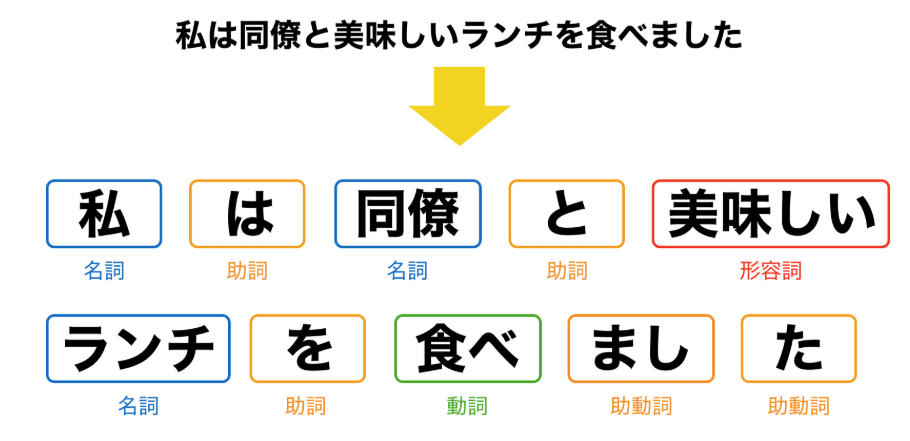
出典:VNext JAPAN|自然言語処理(NLP)とは?意味や仕組み
つまり、NLPは分野の名称、LLMはその中で使われる具体的な技術・モデルという関係になります。











