こんにちは。
Databricks Data + AI Summit 2026(DAIS2026)現地レポート第5弾は、データ基盤の「分析」側ではなく「トランザクション処理(OLTP)」側の主役として登場した 「Lakebase」 を取り上げます。一言で表すなら フルマネージドのサーバーレス Postgres。基調講演ではこのアーキテクチャを、Nikita Shamgunov 氏がデータベース内部の仕組みにまで踏み込みながら、丁寧に解き明かしてくれました。
近年のデータ基盤の議論は、レイクハウスを中心とした分析(OLAP)の話題に偏りがちです。しかし、実際のプロダクトを動かしているのは、ユーザーのクリックや注文、エージェントの状態更新といった「書き込み」を受け止めるトランザクションDBです。Lakebase が面白いのは、この古くからある OLTP の世界を、レイクハウスの設計思想で丸ごと作り直そうとしている点にあります。そして、その再設計の通奏低音として一貫して語られていたのが「AIエージェントが安心して使えるDB」というコンセプトでした。このコンセプトの解像度の高さこそ、今回のセッションでもっとも印象に残ったポイントです。
「次の100億のアプリとエージェントに必要なDBとは?」
Reynold Xin 氏によるリアルタイム分析パートに続き、Ali Ghodsi 氏のハンドオフを経てステージに登壇したのが、Nikita Shamgunov 氏でした。彼が観客に投げかけた問いは、極めてシンプルなものでした。
“What do the next 10 billion apps and agents need in a database?”
(次の100億のアプリとエージェントは、DBに何を求めるか?)
この問いの設計が巧みなのは、「アプリ」と並べて「エージェント」を主語に据えている点です。これまでDBの利用者は人間が書いたアプリケーションでした。しかしこれからは、自律的に動くAIエージェントが大量にDBへアクセスし、データを読み書きするようになる。あらゆるアプリには依然としてDBが必要であり、そこにエージェントという新しい桁違いのワークロードが上乗せされていく――。その前提のもとで、これからのDBに求められる条件として、Shamgunov 氏は3つのキーワードを提示しました。
- Familiar(馴染みがある):オープンソースで、人気があり、拡張可能であること
- Nimble(俊敏):サーバーレスで、ブランチでき、コスト効率が良いこと
- Mission critical(ミッションクリティカル):無限のスケール、高速、高信頼であること
この3つは、それぞれ「採用のしやすさ」「開発・運用の機動力」「本番に耐える堅牢性」に対応しており、どれか1つでも欠けると100億のワークロードは支えられない、という整理です。とりわけ2つ目の Nimble は、後述するアーキテクチャの肝に直結する概念でした。
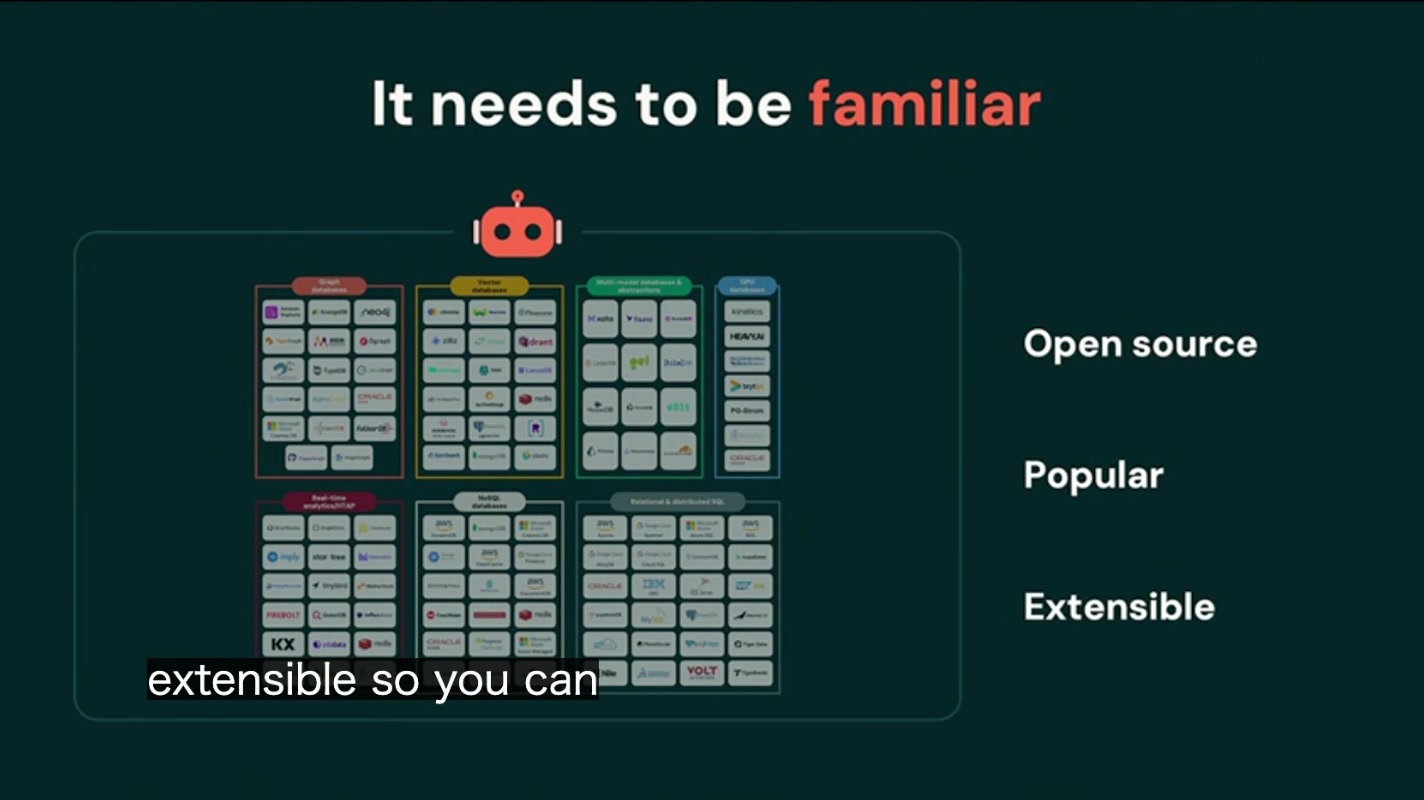
サーバーレスであること、ブランチ(分岐)できること、そしてコスト効率が良いこと。スライドに並んだこの3つの要素は、いずれも従来のマネージドDBが苦手としてきた領域です。常時起動のインスタンスを抱え、本番データの複製にはストレージのフルコピーと時間を要し、使っていない時間帯もコストが垂れ流される――。この「俊敏さの欠如」をどう克服するかが、Lakebase の設計テーマだと言えます。
だから「Postgres から始めた」
3条件のうち「Familiar(馴染みがある)」に対する Databricks の答えは、明快でした。Postgres です。
“We started with Postgres”
(私たちは Postgres から始めた)
その根拠として示されたのが、開発者コミュニティで広く参照される Stack Overflow の年次調査でした。Stack Overflow 2025 の人気調査において、PostgreSQL は 59.50% という数字でトップに立っています。Shamgunov 氏は Postgres を「世界最大のDBエコシステム」「あらゆるニーズに対応する拡張機能を備える」「そして、すべてのエージェントが理解できるオープンソース」と位置づけました。
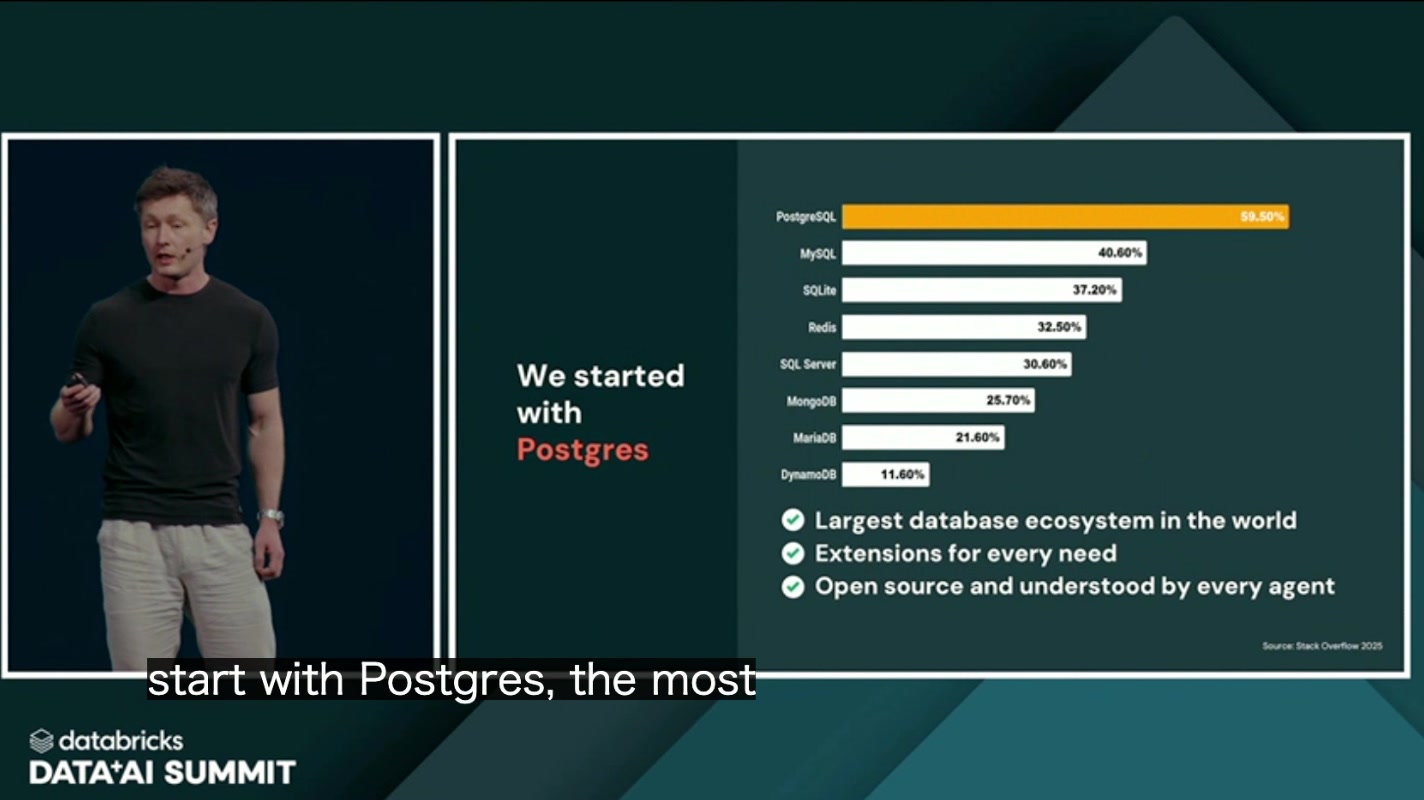
最後の「すべてのエージェントが理解できる」という点は、AIエージェント時代ならではの論点として見逃せません。LLM は、世の中に大量に存在する Postgres のスキーマ・SQL・拡張機能のコードを学習しています。つまり、もっとも普及したオープンソースDBを選ぶこと自体が、エージェントが正しくクエリを組み立て、運用できる確率を高めることに直結する――。「人気がある」という事実が、AI時代には「エージェント互換性が高い」という技術的優位に転化する、という洞察です。ゼロから独自のDBを発明するのではなく、すでに勝者となっているエコシステムの上に立つ。これが Lakebase の出発点でした。
アーキテクチャ:コンピュートとストレージを分離し、ストレージをレイクへ
ここからがセッションの核心、Lakebase のアーキテクチャです。Shamgunov 氏が掲げた再設計の方針は、大胆なものでした。コンピュートとストレージを分離し、ストレージをデータレイクへ移すというものです。

コンピュートとストレージの分離(decoupling)自体は、レイクハウスやクラウドDWHの世界ではすでに常識となった考え方です。しかし、それを Postgres のようなトランザクションDBに持ち込むのは、決して簡単ではありません。なぜなら OLTP は、低レイテンシでの読み書きとトランザクション整合性が生命線だからです。
なぜOLTPでコンピュート/ストレージ分離が効くのか
従来の Postgres は、コンピュート(クエリを実行するプロセス)とストレージ(ディスク上のデータファイル)が密結合しています。サーバーが一体である以上、スケールアップ/ダウンは丸ごとのインスタンス入れ替えになり、データの複製は物理コピーを伴います。この「一体構造」こそが、前述の Nimble(俊敏さ)を阻む最大の足かせでした。
両者を切り離すと何が嬉しいのか。ストレージを共有の永続層として外に出してしまえば、コンピュートは「状態を持たない、いつでも捨てられる存在」になります。必要なときに素早く立ち上げ、不要なときには消し、データそのものには一切触れずに環境を増やしたり巻き戻したりできる。後述する「500ms未満の起動」「瞬時のブランチ」「scale-to-zero」といった特性は、すべてこの分離から自然に導かれるものです。OLTPでこの分離を成立させられれば、トランザクションDBの運用は質的に変わる――それがこの再設計の狙いです。
ただし、ストレージをレイクへ移すことには明確なトレードオフが伴います。レイクストレージは「安価でスケールしやすい」反面、「遅く、トランザクション的に不整合になりがち」という弱点を抱えているからです。
安くてスケールするが、遅くて整合性が弱い。これをそのままOLTPに使えば、トランザクションDBとして致命的です。そこで Lakebase は、この弱点を内部の2つの専用コンポーネントで埋めるという設計を採りました。
- Safekeepers(セーフキーパー):WAL(Write-Ahead Log)レコードをレイクストレージに書き込み、耐久性とトランザクション整合性を担保する
- Page servers(ページサーバー):読み取りのレイテンシに対処する

ポイントは、Postgres のトランザクションの根幹である WAL(先行書き込みログ)を、Safekeepers がレイクストレージへ確実に永続化するという点です。WAL を信頼できる形で書き切ることで、レイクの「整合性が弱い」という弱点をカバーし、トランザクションの耐久性を保証します。一方、読み取り性能の弱点は Page servers が引き受け、ページ単位のデータ提供を最適化することでレイテンシを抑え込みます。
書き込みの整合性は Safekeepers が、読み取りの速さは Page servers が、それぞれ専門に担う。レイクの「安い・スケールする」という長所を活かしつつ、「遅い・不整合」という短所を専用コンポーネントで打ち消す――この役割分担の妙によって、Lakebase = フルマネージドのサーバーレス Postgres という構図が初めて成立します。利用者から見れば、相手はあくまで普通の Postgres。しかしその裏側では、レイクハウスの経済性とトランザクションDBの堅牢性を両立させる仕掛けが動いている、というわけです。
エージェントに効く4つの特徴
アーキテクチャの説明を踏まえると、Lakebase の本当の嬉しさが見えてきます。それは、コンピュートとストレージを分離したからこそ実現できる、4つの運用特性に凝縮されています。いずれも「AIエージェントが安心して大量に使う」というシナリオに、見事に刺さるものでした。
① 500ms未満で起動
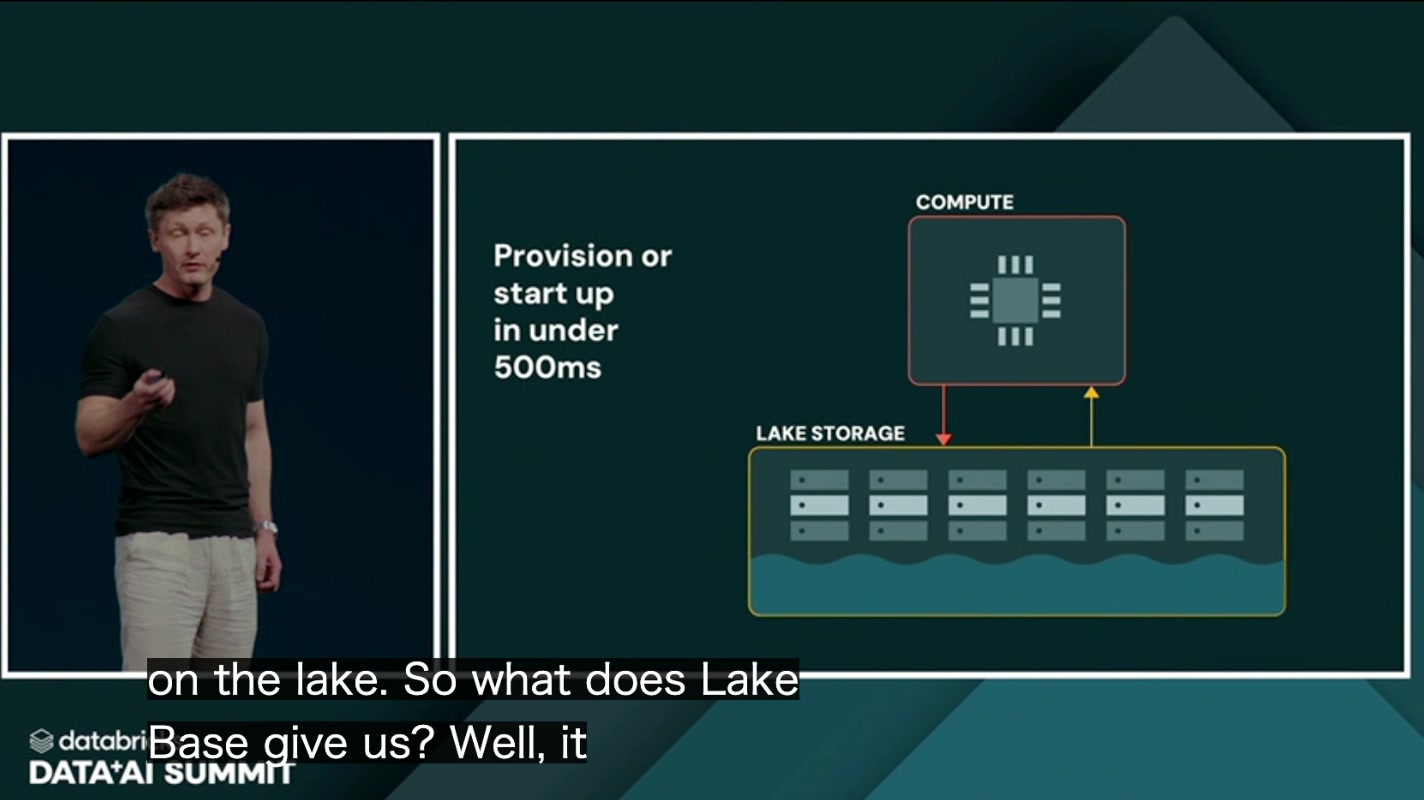
まず、プロビジョニングや起動が 500ms未満 という速さ。コンピュートが状態を持たないからこそ、必要になった瞬間にインスタンスを立ち上げられます。エージェントが「いまDBが要る」と判断してから利用可能になるまでが半秒以下、という体験は、無数のエージェントが断続的にDBへアクセスする世界では決定的な意味を持ちます。
② 一瞬でブランチ(安全な実験)
本番データのコピーを瞬時に作り、E2Eテストやスキーマ移行、dev/test/staging 環境を安全に用意できます。ストレージがレイク上に共有されているため、ブランチはデータの物理コピーではなく、コピーオンライト的な「軽い分岐」として成立します。AIエージェントが「本番を壊さずに試行錯誤する」ための仕組みとして、まさに最適です。
#### 「瞬時のブランチ」がエージェントにとってのゲームチェンジャーである理由
この「瞬時のブランチ」こそ、Lakebase が掲げる「エージェント時代のDB」というメッセージの中心だと感じました。
AIエージェントの本質は、自律的に試行錯誤することにあります。スキーマを書き換えてみる、大量のデータを投入してみる、破壊的なマイグレーションを走らせてみる――こうした操作を、人間のレビューを都度挟まずに実行していくのがエージェントの強みです。しかし従来のDBでは、その試行錯誤の対象が常に「ただ1つの本番データ」でした。エージェントが本番を直接いじれば、失敗は即座に障害につながります。かといって、毎回フルコピーの検証環境を用意していては、起動に時間とコストがかかりすぎて「俊敏さ」が失われます。
ブランチが一瞬で、ほぼコストゼロで作れるなら、この前提が崩れます。エージェントは本番から分岐したブランチ上で好きなだけ実験し、うまくいけばその結果を採り入れ、失敗すればブランチごと捨てればよい。本番には一切傷がつきません。さらにブランチが安価なら、複数のエージェントがそれぞれ独立したブランチを持ち、並行して別々の仮説を試すことすら現実的になります。「壊しても大丈夫な本番の写し」を、必要なだけ・即座に手に入れられる。これは、エージェント駆動の開発における失敗のコストを劇的に引き下げる変化であり、まさにゲームチェンジャーと呼ぶにふさわしいものでした。
③ チェックポイントから即座にリカバリ
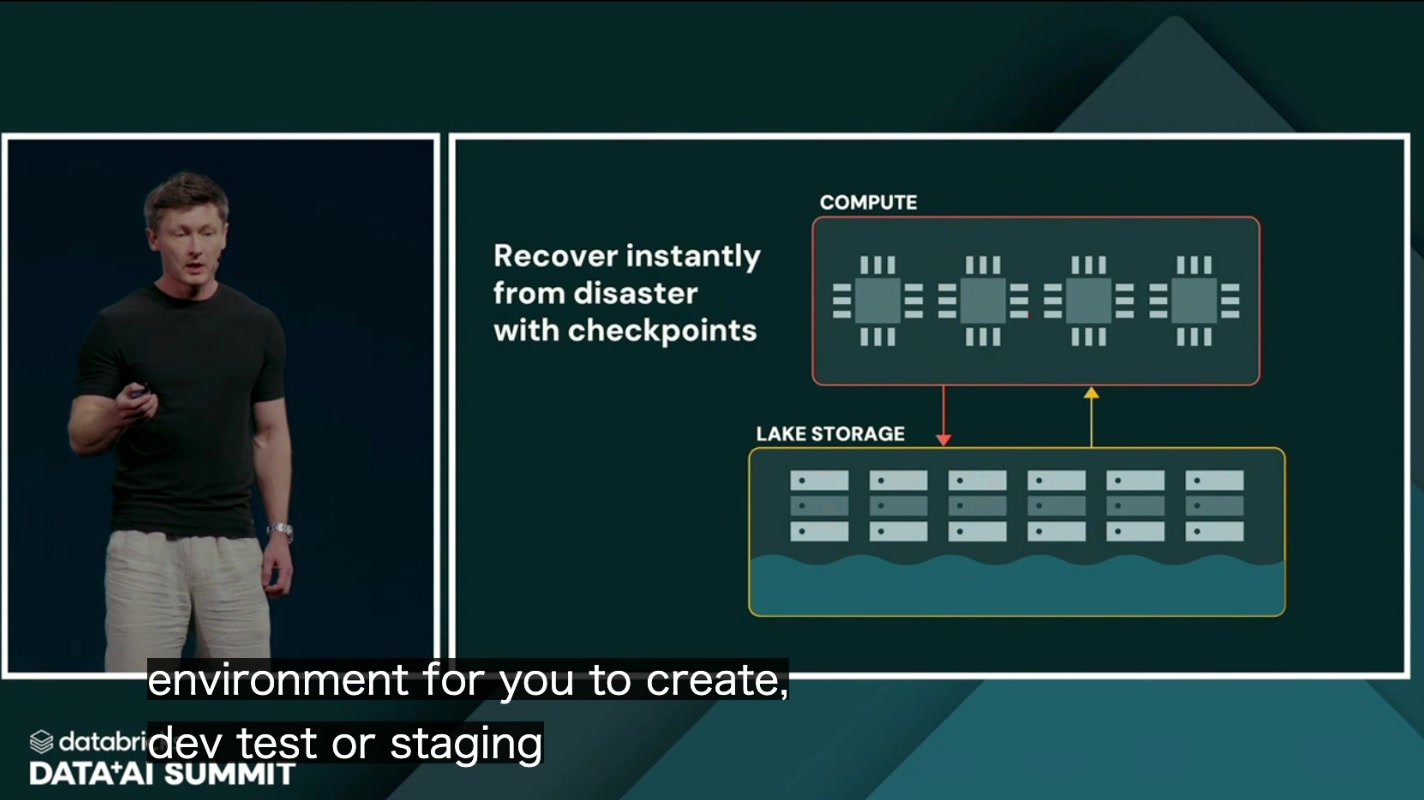
万が一の障害時にも、チェックポイントから即座にリカバリできます。ブランチと同じ仕組みの裏返しで、過去の状態に「巻き戻す」操作が軽量に行えるため、災害復旧(DR)のハードルが大きく下がります。エージェントが誤った大規模更新を走らせてしまった、といったケースでも、健全だった時点へすばやく戻せるのは大きな安心材料です。
④ scale-to-zero で低TCO / エンタープライズ規模までスケール
使わないときはゼロまで縮退(scale-to-zero)してコストを抑え、必要なときはエンタープライズ規模までコンピュートをスケールさせられます。

ここでもコンピュート/ストレージ分離が効いています。コンピュートをゼロまで落としてもストレージ側のデータは安全に保持されるため、「待機中はほぼ無料、必要なときだけ一気にスケール」という弾力的な運用が可能になります。アクセスが間欠的になりがちなエージェントワークロードでは、この scale-to-zero がTCO(総保有コスト)に直結します。
そして「LTAP」へ — Lakebase と Lakehouse の統合
基調講演の別パートでは、Lakebase(トランザクション)と Lakehouse(分析)を統合する新しいアーキテクチャ 「LTAP(Lake Transactional/Analytical Processing)」 が、「Introducing Today!」 として発表されていました。トランザクションと分析を1つの基盤の上でシームレスに扱う、という構想です。
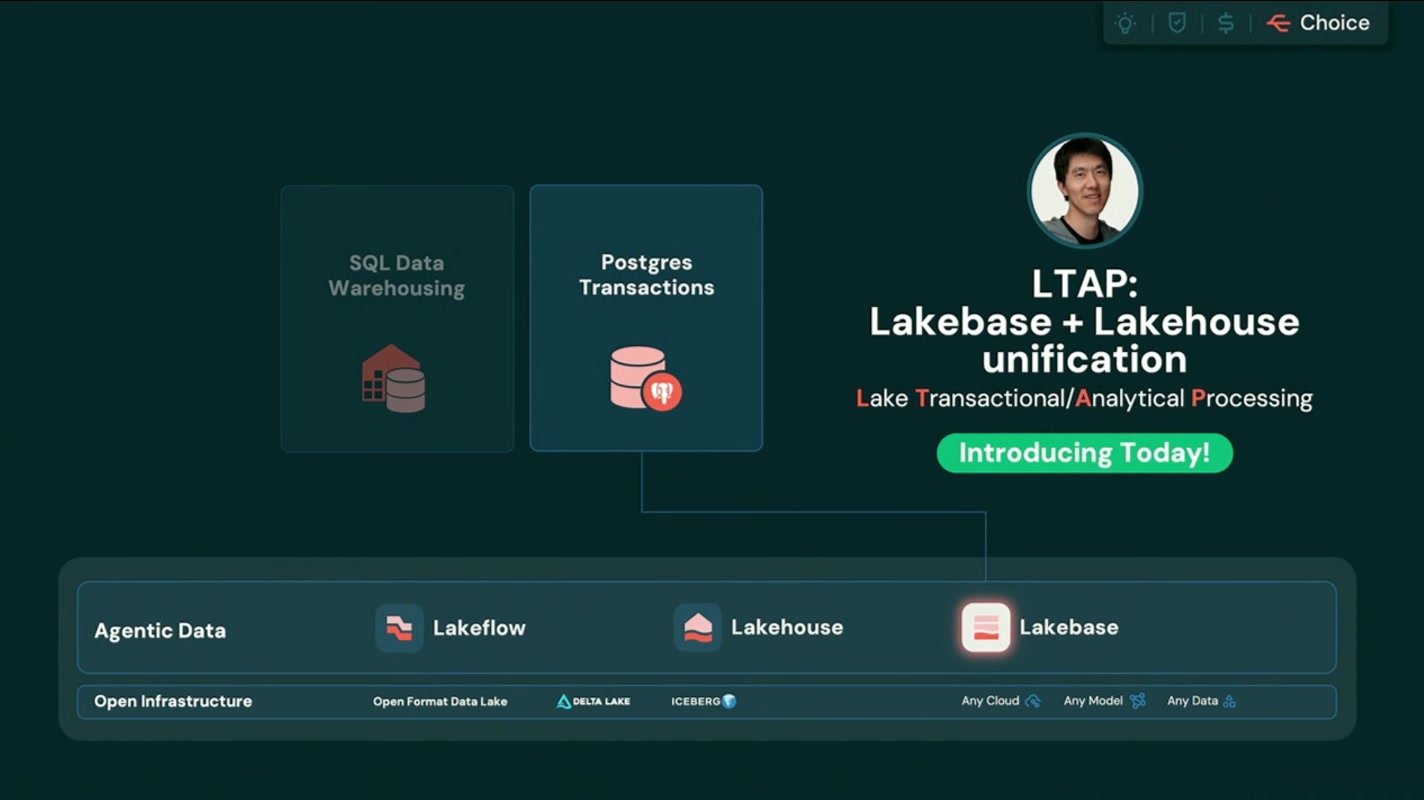
従来、トランザクションDB(OLTP)と分析基盤(OLAP)は別々のシステムとして構築され、その間を ETL/CDC のパイプラインで延々とつなぐのが当たり前でした。LTAP は、Lakebase で受けたトランザクションと、Lakehouse での分析を同じ基盤上で連続的に扱おうとするものです。OLTP と OLAP の境界をデータ移動なしに溶かしていく方向性は、データエンジニアリングの長年の課題に対する一つの回答だと言えます。
あわせて、Lakebase 自体のアーキテクチャも改めて整理されていました。Base(=Compute/Execution) と Lake(=Storage) という構成のもと、サーバーレスのオートスケール、ブランチ、スナップショット、最低水準のTCO、そしてロックインなし、という特性が一枚のスライドにまとめられていました。
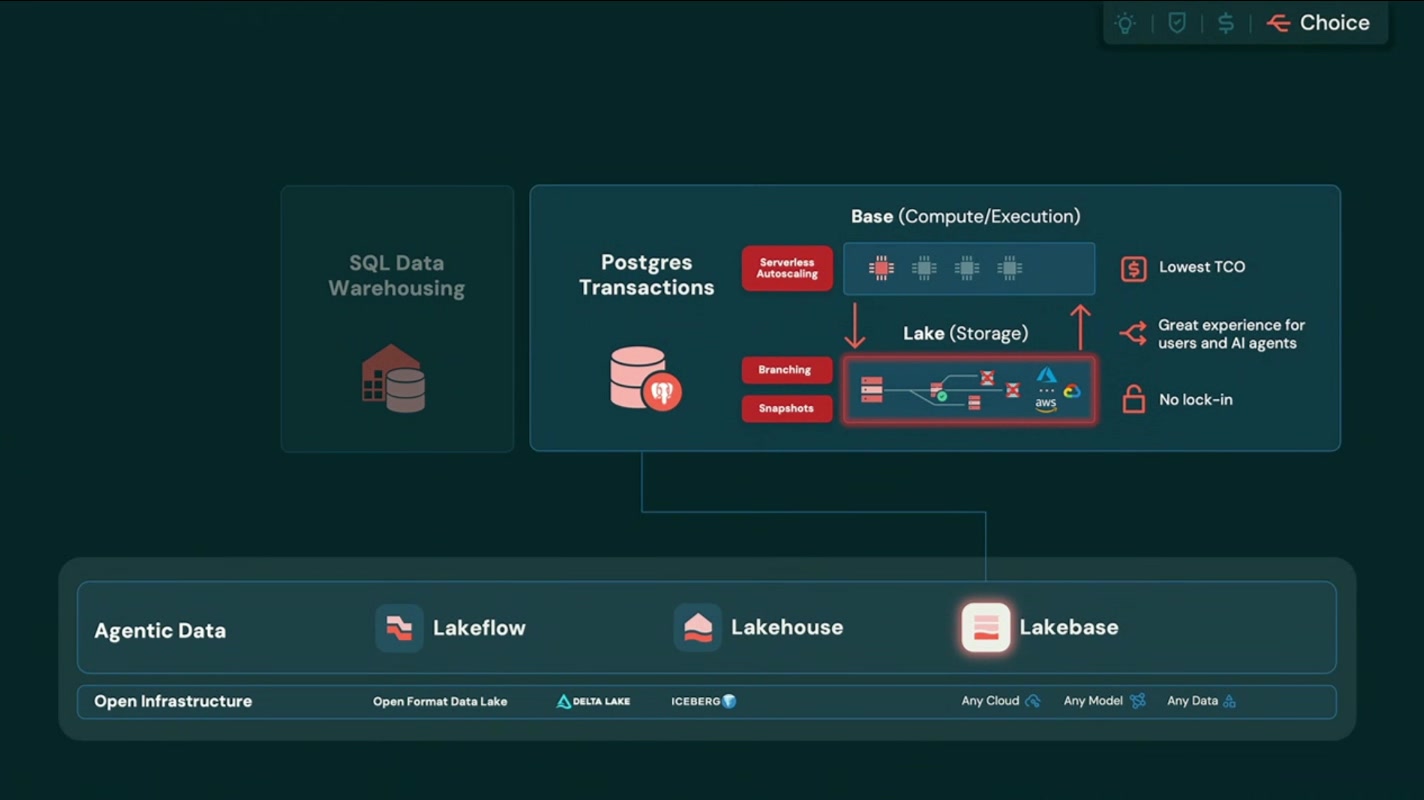
「Base=コンピュート/実行、Lake=ストレージ」という名前そのものに、これまで見てきたコンピュート/ストレージ分離の思想がそのまま表れています。ここまでの一連の特徴――オートスケール、ブランチ、スナップショット、低TCO――が、すべて同じ設計原理から派生していることが、この図からも見て取れます。
所感
今回 Lakebase のセッションを現地で聞いて、もっとも腑に落ちたのは「人気のあるものを選ぶこと自体が、AI時代には技術的な正解になる」という逆説でした。Postgres を土台に選んだ理由が、単なる移行のしやすさではなく「すべてのエージェントが理解できるオープンソースだから」という点にあるのは象徴的です。エコシステムの大きさが、そのままエージェント互換性という競争力になる。この発想の転換は、これからの基盤技術の選定基準を考えるうえで示唆に富んでいます。
そしてアーキテクチャ面では、「コンピュート/ストレージ分離」という分析基盤の定石を、Safekeepers と Page servers という工夫でOLTPに持ち込みきった点が見事でした。レイクストレージの弱点を正面から認めたうえで、それを専用コンポーネントで打ち消すという誠実な設計が、500ms未満の起動・瞬時のブランチ・即時リカバリ・scale-to-zero という具体的な価値に結実しています。中でも「瞬時のブランチ」は、エージェントが本番を壊さずに試行錯誤するための前提を変える、極めて実務的なインパクトを持つと感じました。
まとめ
Lakebase は、「AIエージェントが安心して大量に使えるトランザクションDB」 を、誰もが知る Postgres をベースに、コンピュート/ストレージ分離によって再発明した発表でした。改めて要点を整理します。
- ベースは Postgres(馴染み・拡張性・そしてエージェントが理解できるオープンソース)
- Safekeepers / Page servers による独自設計で、耐久性・トランザクション整合性・低レイテンシを両立
- コンピュート/ストレージ分離から導かれる 500ms未満の起動・瞬時のブランチ・即時リカバリ・scale-to-zero
- LTAP によって、トランザクションと分析を1つの基盤へ統合
「エージェントが本番を壊さずにブランチして試す」という使い方は、まさにこれからのアプリ/エージェント開発に深く刺さりそうです。馴染みのある Postgres の顔をしながら、その裏ではレイクハウスの経済性とトランザクションDBの堅牢性を両立させている――この二面性こそが Lakebase の強みだと感じました。
次回は、これらを束ねる 統合ガバナンスとエコシステム(Unity Catalog / Unity AI Gateway / Delta Sharing / Panther / CustomerLake)をレポートします。
参考リンク
*#DAIS2026 #Databricks #Lakebase #Postgres #現地レポート*