こんにちは。
Databricks Data + AI Summit 2026(DAIS2026)現地レポート、第3弾をお届けします。今回のテーマは、データ基盤づくりの土台でありながら、これまで最も泥臭く、最も人手のかかってきた領域——データエンジニアリングです。
会場のセッションは、大きく2つのメッセージで構成されていました。ひとつは Lakeflow によるデータスタックの徹底的な簡素化。もうひとつは、新発表 「Genie ZeroOps」 による、データ運用そのものの”自動運転”です。「ツールを増やして複雑さに対処する」時代から、「ツールを束ね、運用をエージェントに任せる」時代へ——その転換点を強く意識させる内容で、現場でパイプラインを書いたり直したりしている立場からすると、思わず前のめりになる発表でした。
順を追ってレポートしていきます。
顧客事例:PepsiCo
セッションは、いきなり製品紹介から入るのではなく、グローバル企業のリアルな現場から始まりました。登壇したのは PepsiCo の Magesh Bagavathi 氏(Global Chief Data and AI Officer)。
世界中に拠点を持ち、膨大な商品・サプライチェーン・販売データを扱う PepsiCo にとって、データとAIの活用は「あったら嬉しい」ものではなく、事業そのものを動かす基盤です。だからこそ、その現場で何が起きているのか、どんな複雑さと向き合っているのか——という生々しい話は説得力があり、会場の関心を一気に引きつけました。製品デモの前に「顧客の現実」を置くことで、このあと語られる Databricks の打ち手が「絵に描いた機能」ではなく「課題への回答」として聞こえてくる、という流れの設計が見事でした。

「私たちは複雑さと折り合いをつけてきた」
続いて登壇したのは Databricks の Bilal Aslam 氏。現代のデータスタックがいかに肥大化し、複雑化しているかを、たった1枚のスライドで突きつけてきました。
スライドに並ぶのは、いまやデータ基盤の”定番”となったツールの数々です。Kafka、Flink、Spark、dbt、EMR/Glue、Airflow、Snowflake、Alteryx……。それぞれは優れたツールですが、取り込み・変換・準備・オーケストレーション・分析と、レイヤーごとに別々のプロダクトを継ぎ接ぎしていくうちに、いつの間にか巨大で壊れやすいパッチワークが出来上がってしまう。多くのデータチームが身に覚えのある光景だと思います。
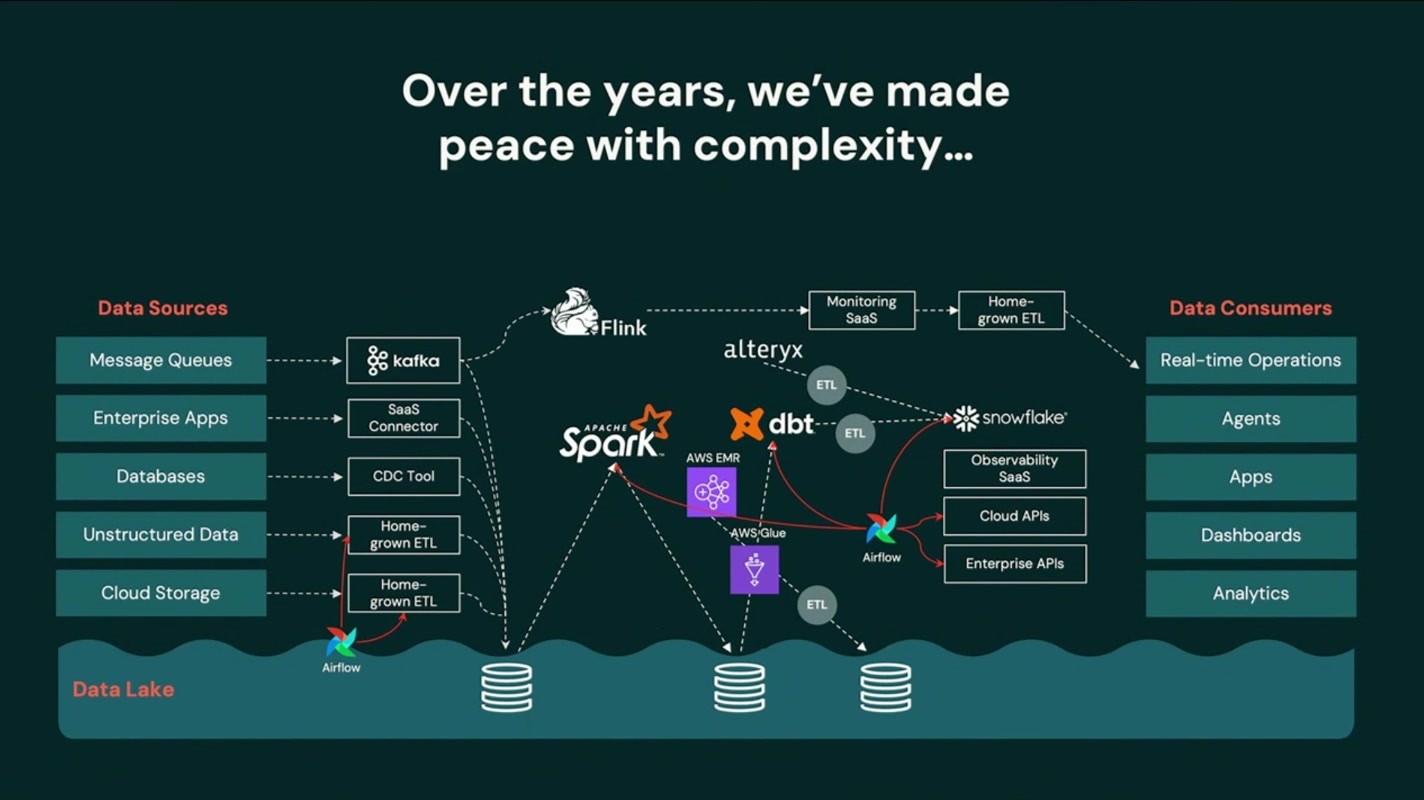
“Over the years, we’ve made peace with complexity…”
(私たちは長年、複雑さと折り合いをつけてきた…)
この一言が刺さるのは、単なる技術的な不満を超えて、業界全体が「複雑なのが当たり前」と諦め、それを前提に運用体制やコストを組み立ててきた、という現実を言い当てているからです。新しいツールを足すたびに学習コスト・接続コスト・監視コストが積み上がり、それでも「データ基盤とはそういうもの」と受け入れてきた——その”折り合い”を、Bilal 氏はあえて言語化してみせました。
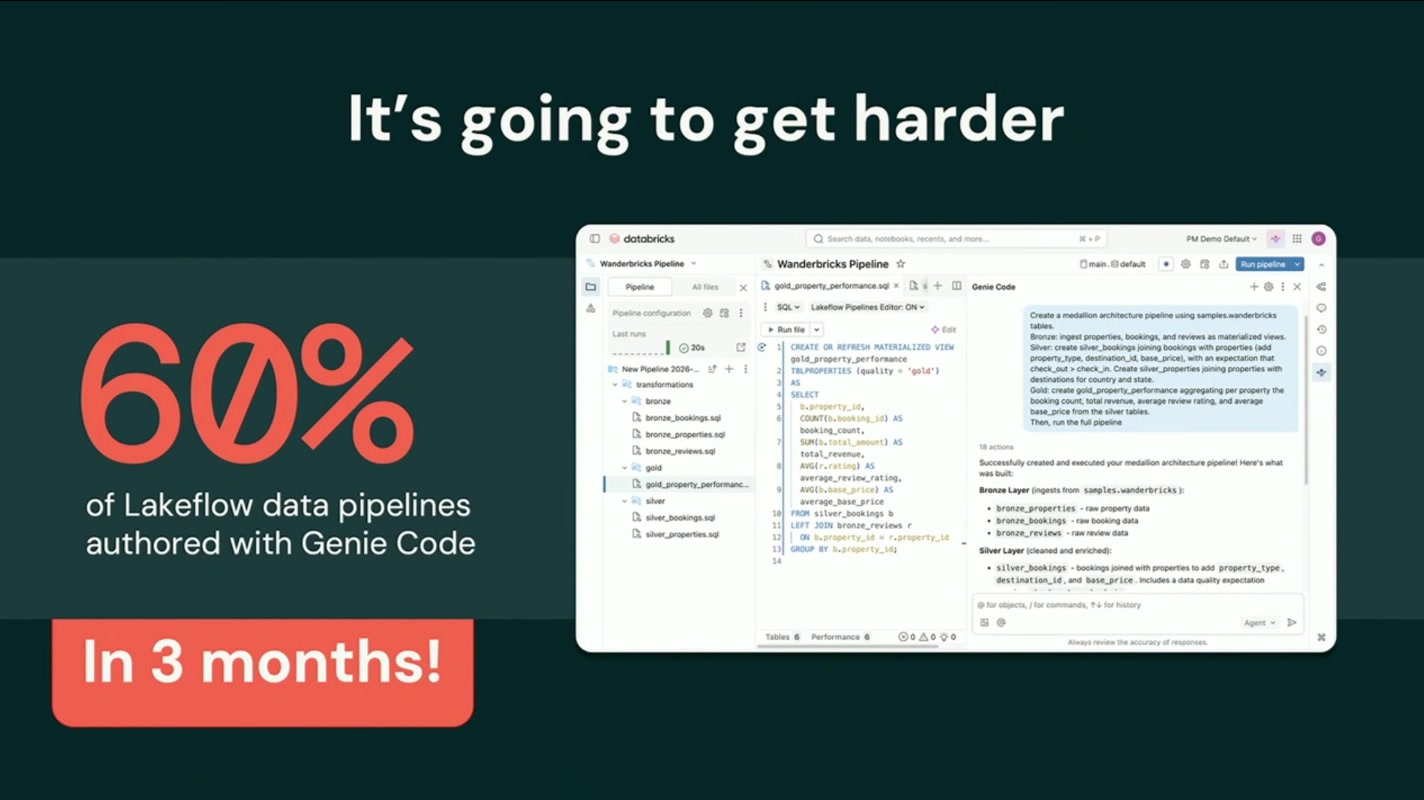
そしてエージェント時代に入り、状況は 「It’s going to get harder(さらに難しくなる)」。AIエージェントが大量のデータを読み書きし始めれば、扱うデータ量も、求められる信頼性も、ガバナンスの厳しさも一段上がる。複雑さは放っておけば膨らむ一方だ、という警鐘です。
一方で、明るい兆しも示されました。Databricks 上でのパイプライン作成では、すでに 60% が Genie Code で書かれているというのです。しかも、それがわずか3か月で到達した数字だという点が衝撃的でした。「パイプラインを人が手書きする」前提そのものが、すでに足元から崩れ始めている——複雑さは増す一方で、それを生成・運用する手段は急速にAIへ移りつつある、という二面性が鮮やかに描かれました。
各レイヤーを「Simplify(簡素化)」する
では、その複雑さにどう向き合うのか。Databricks の答えは、拍子抜けするほどシンプルでした。データスタックの各レイヤーを、ひとつずつ徹底的に簡素化していく。新しいツールを足して複雑さを増やすのではなく、レイヤーごとに「これ1つでいい」と言い切れる形に畳んでいくアプローチです。
順番に、変換・準備・取り込み・オーケストレーションの4レイヤーが俎上に載せられました。
データ変換 → Apache Spark™ Declarative Pipelines
まず、データ変換のレイヤー。ここに当てるのが Apache Spark™ Declarative Pipelines です。
ポイントは「宣言的(Declarative)」であること。「どう処理するか」という手続きを細かく書くのではなく、「最終的にどういうデータが欲しいか」を宣言すれば、あとはエンジンが実行計画を組み立ててくれる。そして最大の魅力は、バッチもストリーミングも、まったく同じ書き方で扱える点です。
従来、バッチ処理とストリーミング処理は別物として扱われ、それぞれに別のフレームワークやコードパスを用意するのが常でした。それを1つの宣言的な記述に統一できるのは、運用面でも学習コスト面でも大きな簡素化につながります。

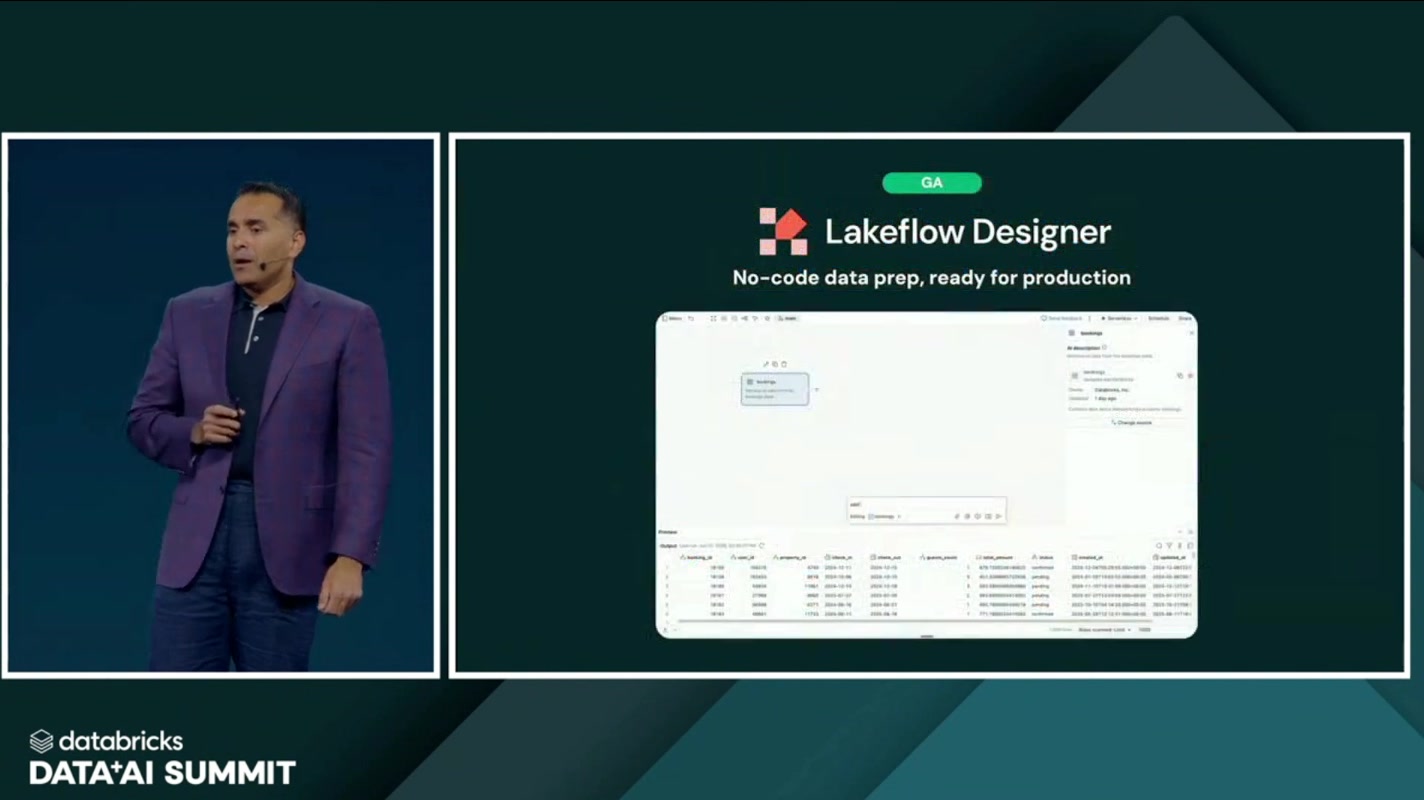
データ準備 → Lakeflow Designer(GA)
次が、データ準備のレイヤー。ここを担うのが Lakeflow Designer で、今回 GA(一般提供) になったことが発表されました。
Lakeflow Designer は、コードを書かずにデータ準備ができるノーコードツールです。ここで Bilal 氏が強調していたのが「No-code data prep, ready for production」というフレーズ。ノーコードツールは「手軽だけど本番には使えない」と見られがちですが、Lakeflow Designer は本番運用に耐える品質を備えている、という主張です。
ノーコードで作ったものがそのまま production grade のパイプラインになる、というのは、データに詳しいビジネス側の人材が手を動かせる範囲を一気に広げます。エンジニアの手が空くだけでなく、データ活用の裾野そのものが広がる発表でした。
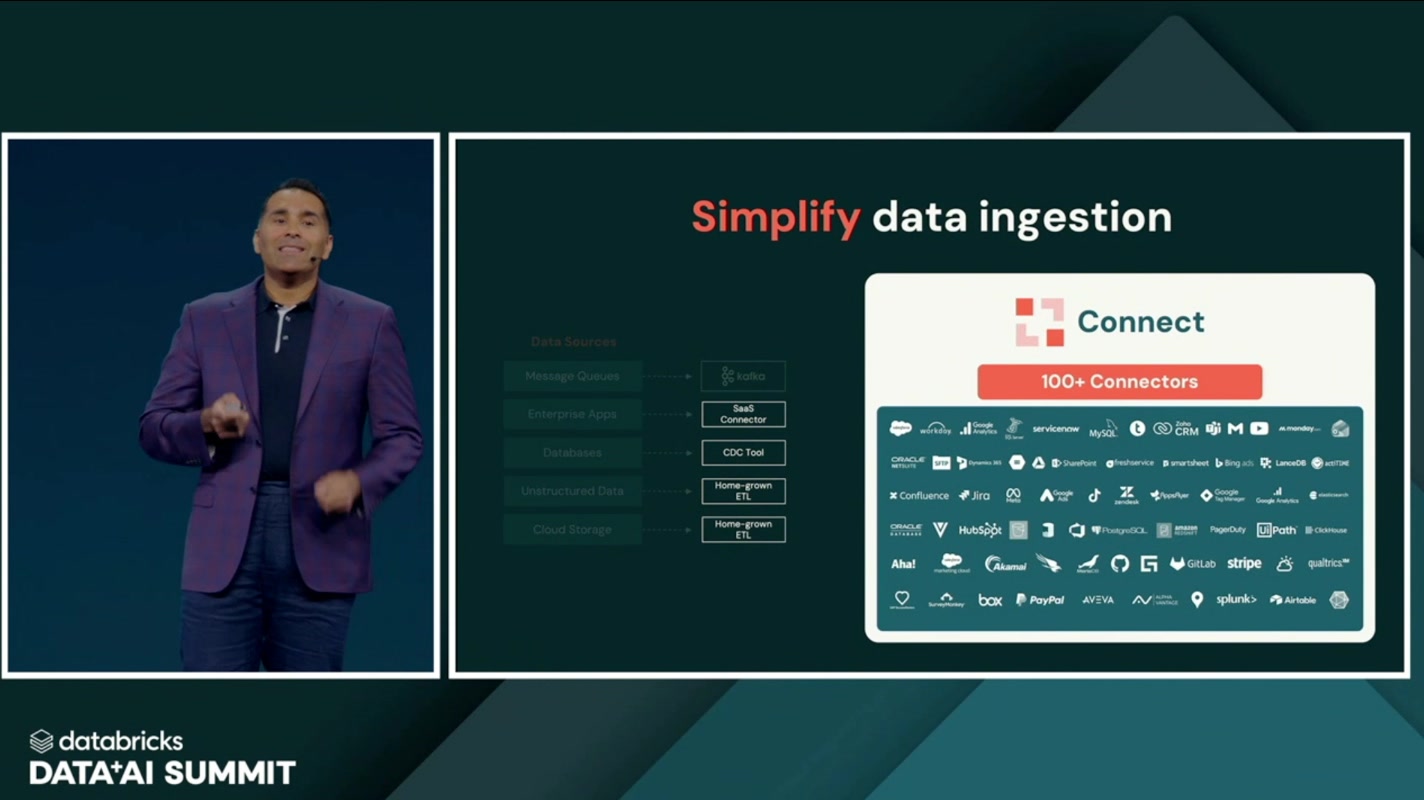
データ取り込み → Connect(100+コネクタ)
3つ目は、データ取り込み(ingestion)のレイヤー。ここを担当するのが Connect です。
データ基盤を作るとき、地味に時間を食うのが「あちこちに散らばったデータをかき集めてくる」工程です。SaaSごと、DBごとにコネクタを自前で書いたり、ETLツールを設定したりするのは、骨が折れるわりに付加価値の見えにくい作業でもあります。
Connect には、Salesforce、Workday、ServiceNow、SharePoint、Jira、PostgreSQL、Stripe、Splunk……といった主要なサービス向けに、100以上のコネクタが用意されています。各種SaaS・DBからの取り込みを、自前実装ではなく標準コネクタで賄えるようになり、取り込みレイヤーの複雑さを大幅に削ぎ落とします。
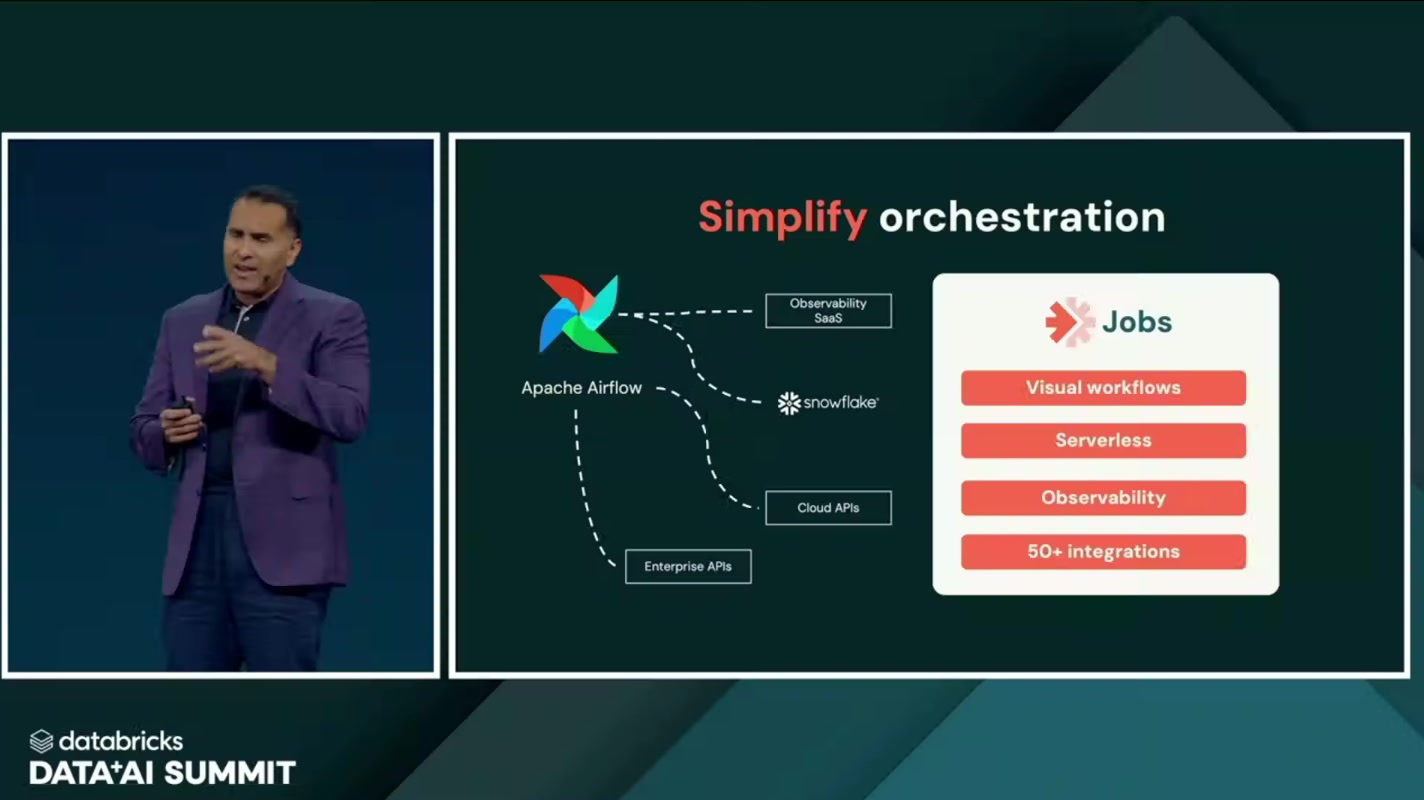
オーケストレーション → Jobs
最後が、ワークフローのオーケストレーション。ここを束ねるのが Jobs です。
ビジュアルなワークフロー定義、サーバーレス実行、オブザーバビリティ(可観測性)、そして50以上の連携——これらを兼ね備え、現場で乱立しがちな Airflow ベースのオーケストレーション環境を置き換えていく狙いです。ジョブの依存関係を画面上で組み立て、サーバーの面倒を見ずに走らせ、何がどこで詰まっているかをそのまま観測できる。「つなぎのためのツールをさらに別途用意する」必要がなくなる、というのがポイントです。
すでに桁違いのスケールで使われている
ここで Bilal 氏は、「これは未来の話ではなく、すでに現実だ」と畳みかけます。これら Lakeflow の構成要素は、構想段階のものではなく、すでに圧倒的な規模で本番稼働しているというのです。

- 200T(200兆)行/日 を Spark Declarative Pipelines が処理
- 1.7B(17億)回/月 のジョブ実行
- 顧客の 50% がサーバーレスで稼働
数字の桁が大きすぎて一瞬ピンと来ませんが、1日あたり200兆行、月に17億回のジョブ実行というのは、エッジケースもピーク負荷も含めて、あらゆる現場の負荷を浴び続けてきたということです。そのスケールで磨かれてきたからこそ、ノーコードでも「ready for production」と言い切れるわけで、ここまでの簡素化の話に厚みを与える裏付けになっていました。さらに顧客の半数がすでにサーバーレスへ移行している点も、「インフラの面倒を見る」こと自体を手放す方向にトレンドが固まりつつあることを示しています。
そして本命:「Genie ZeroOps」
ここからがセッションの本命、新発表です。
Bilal 氏は、いきなり機能を見せるのではなく、まず「なぜ運用をエージェントに任せるべきなのか」という論理を丁寧に積み上げていきました。曰く——「データエンジニアリングはソフトウェアエンジニアリングとは違う」。「最も難しいのは”検証(verify)”だ」。「だから運用エージェントはデータプレーンの一部である必要がある」。
この3つの主張は、それぞれ後ほど掘り下げますが、結論はこうです。
ANNOUNCING — Genie ZeroOps — Put your data and AI ops on autopilot.
(データとAIの運用を自動運転に。)

Genie ZeroOps は、データ/AI運用で起きるインシデントを、検知・診断・修復まで自律的にこなすAIエージェントです。アラートを上げて人に丸投げするのではなく、問題を見つけ、原因を切り分け、直すところまでを一気通貫で担う——文字通りの”自動運転(autopilot)”です。
なぜ「データエンジニアリングはソフトウェアエンジニアリングと違う」のか
Bilal 氏が最初に置いた論点を、少し補足しておきます。
ソフトウェアエンジニアリングの世界では、テストは基本的に決定論的(deterministic)です。同じ入力を与えれば同じ出力が返り、`assertEquals(expected, actual)` のように「正解」を明確に書ける。だからCIで自動チェックが回り、壊れたらすぐに分かります。
ところがデータエンジニアリングは、扱う対象がコードではなくデータそのものであり、その性質は統計的(statistical)です。「このテーブルの値は正しいか?」と問うても、唯一絶対の正解があるわけではない。昨日と今日でデータの分布が変わるのは異常なのか、それとも事業が伸びた正常な変化なのか——それは一律のルールでは判定できません。検証(verify)が難しい、というのはまさにこの点で、人間が文脈を踏まえて「これはおかしい/これは想定内」と判断せざるを得ない領域だったのです。
Genie ZeroOps が狙うのは、この「統計的な世界での検証と判断」をエージェントに肩代わりさせること。決定論的なテストでは捉えきれない異常を、データの中身を見て診断し、修復案まで出す——ここに価値の核心があります。
なぜ運用エージェントは「データプレーンの一部」でなければならないのか
もう一つの論点が、運用エージェントの”置き場所”です。
仮に運用エージェントを、データ基盤の外側にある別システムとして作ったとしましょう。すると、そのエージェントが何かを診断するたびに、外からデータやメタデータをかき集め、権限を確認し、状態を推測する必要が出てきます。動きは鈍く、見えている情報も限定的で、何より「直す」ところまで安全に踏み込むのが難しい。
これに対し、運用エージェントがデータプレーンの一部——つまりデータやテーブル、ポリシー、ジョブと同じ場所に同居していれば、状態をリアルタイムに把握でき、ガバナンスやアクセス制御と整合した形で診断・修復を実行できます。「監視ダッシュボードを別に立てる」のではなく、データ基盤そのものに運用知能が埋め込まれている、というのが ZeroOps の設計思想であり、これが先ほどの2つの主張と一本につながっています。
ライブデモ:PII露出インシデントを自律修復
理屈のあとは、実演です。ライブデモは、運用ダッシュボード「ZeroOps Inbox」から始まりました。
このInboxが監視しているのは、今月発生した30件のインシデント、87のジョブ&パイプライン、そして980テーブル。まさにデータ運用の司令塔です。ここから、最も深刻な1件にドリルダウンしていきます。
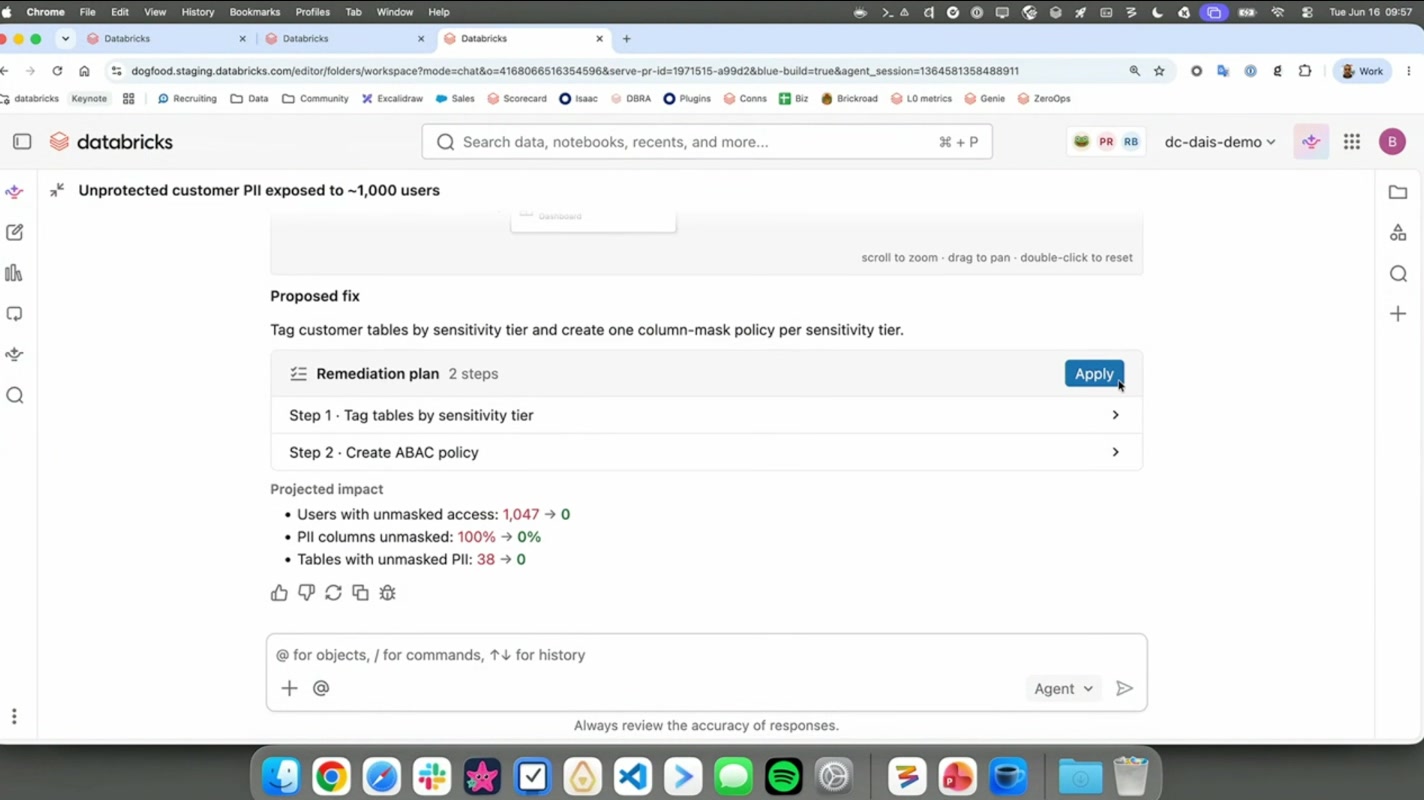
「約1,000ユーザーに顧客PIIが無防備に露出している」
——個人情報(PII)が、本来アクセスすべきでない約1,000人のユーザーに丸見えになっている、という重大インシデントです。セキュリティ・コンプライアンスの観点から、放置できない類の問題です。
これに対し、ZeroOps は単に警告を出すのではなく、具体的な修復プランを提案してきました。
- テーブルを機密度ティアでタグ付けする
- ABAC(属性ベースアクセス制御)ポリシーを作成する
さらに、このプランを適用した場合の見込みインパクトまで、数字で提示してくれます。
- PII露出ユーザー:1,047 → 0
- PII列:100% → 0%
- 対象テーブル:38 → 0
「問題はこれです」だけで終わらず、「こう直せます。直すとこうなります」まで一気に見せる。検知・診断・修復のループが、ダッシュボードの中で完結していく様子は、これまでの「アラートが鳴ったら人が調べて手で直す」運用とは、別次元の体験でした。
まとめ
データエンジニアリングのセッションは、終わってみれば見事に 「簡素化(Simplify)」と「自動運転(ZeroOps)」 の2本立てに整理されていました。
- 作る側:変換・準備・取り込み・オーケストレーションの各レイヤーを Lakeflow で簡素化(Lakeflow Designer は GA)。乱立したツール群を、レイヤーごとに「これ1つ」へ畳んでいく。
- 守る側:運用そのものを Genie ZeroOps が肩代わりし、検知から修復までを自律化。データエンジニアは「維持に費やす時間を減らし、作ることに時間を使える」ようになる。
個人的にいちばん腑に落ちたのは、「データエンジニアリングはソフトウェアエンジニアリングとは違う/最も難しいのは検証だ/だから運用エージェントはデータプレーンの一部であるべき」という、ZeroOps の前段で語られた一連のロジックでした。”パイプラインを書く・直す・守る”という地道で終わりのない作業ほど、実はエージェントに向いている——その割り切りが一貫していて、現場目線で非常に納得感のある発表でした。複雑さと”折り合いをつけてきた”時代から、複雑さを束ねて運用を手放す時代へ。データエンジニアの仕事の重心が、確実に「作る」側へシフトしていくことを予感させる内容でした。
次回は、レイクハウスをリアルタイム化する Lakehouse//RT(Reynold Xin 氏セッション)をレポートします。
参考リンク
*#DAIS2026 #Databricks #Lakeflow #GenieZeroOps #データエンジニアリング #現地レポート*