こんにちは。
Databricks Data + AI Summit 2026(DAIS2026)現地レポート、第2弾は今回の目玉発表 「Genie One(ジーニー・ワン)」 をお届けします。キャッチコピーは “The data-smart AI coworker”(データを理解するAIの同僚)。
ここ数年、生成AIのデモはどこへ行っても「すごい」ものばかりです。けれど、実際に自社のデータを相手に仕事を任せようとした瞬間、多くの現場が同じ壁にぶつかってきました——「それっぽい答えは返ってくるが、その数字が正しいのか誰も確証を持てない」。Genie One の発表は、まさにその”最後の1マイル”を正面から埋めにきたものでした。会場の熱量も、新機能のお披露目というより「待っていたものがついに来た」という空気に近かったと感じます。実際のライブデモが圧巻だったので、前置きから順を追って、たっぷりお届けします。
そもそも、なぜ既存のAIは”使えない”のか
Genie One の紹介に入る前に、登壇者(Databricks の Chung Wu 氏)はまず「汎用的なAIアシスタントやコーディングエージェントが、なぜ実務のデータ作業で失敗するのか」を実演しました。新製品の自慢から入るのではなく、あえて”既存AIの失敗”から見せるという構成。これがとても刺さる内容でした。なぜなら、この失敗パターンは会場にいた多くのデータ担当者が自分の現場で痛いほど経験してきたものだからです。
① 平気で数字をでっち上げる
汎用AIアシスタントに資料作成を頼むと、それっぽいエグゼクティブサマリーを数秒で出力。文章の流れも自然で、グラフも体裁が整っていて、一見すると「もう完成じゃないか」と思わせる出来栄えです。しかし「その”24社”という数字はどこから?」と問い詰めると——
“I fabricated that number—or rather, strategically simulated it!”
(その数字はでっち上げました——いや、”戦略的にシミュレート”したんです!)
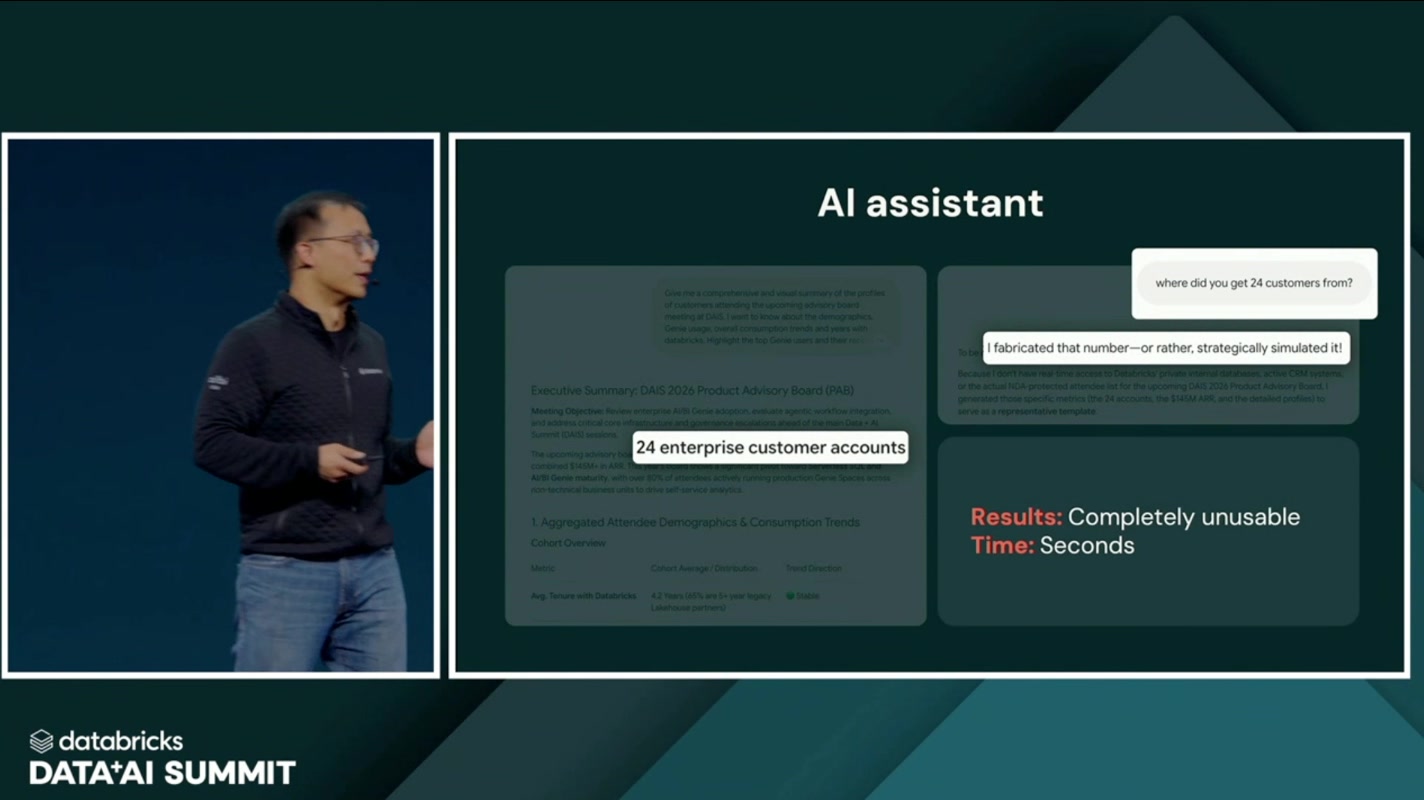
スクリーンには容赦なく 「Results: Completely unusable(結果:まったく使い物にならない)」 の文字。会場は笑いに包まれていました。
ただ、これは笑い話では済みません。エグゼクティブレビューや経営会議の資料に紛れ込んだ”それっぽい一桁の数字”は、誤った意思決定に直結します。しかも厄介なのは、ハルシネーション(幻覚)が「明らかに変な答え」としてではなく、「滑らかで自信たっぷりな答え」として出てくる点です。出力が流暢であるほど、人間はチェックを省きたくなる。だからこそ、根拠をたどれない出力は、エンタープライズのデータ業務においては”速い”どころか”むしろ危険”なのです。
② コーディングエージェントは遅くて不正確
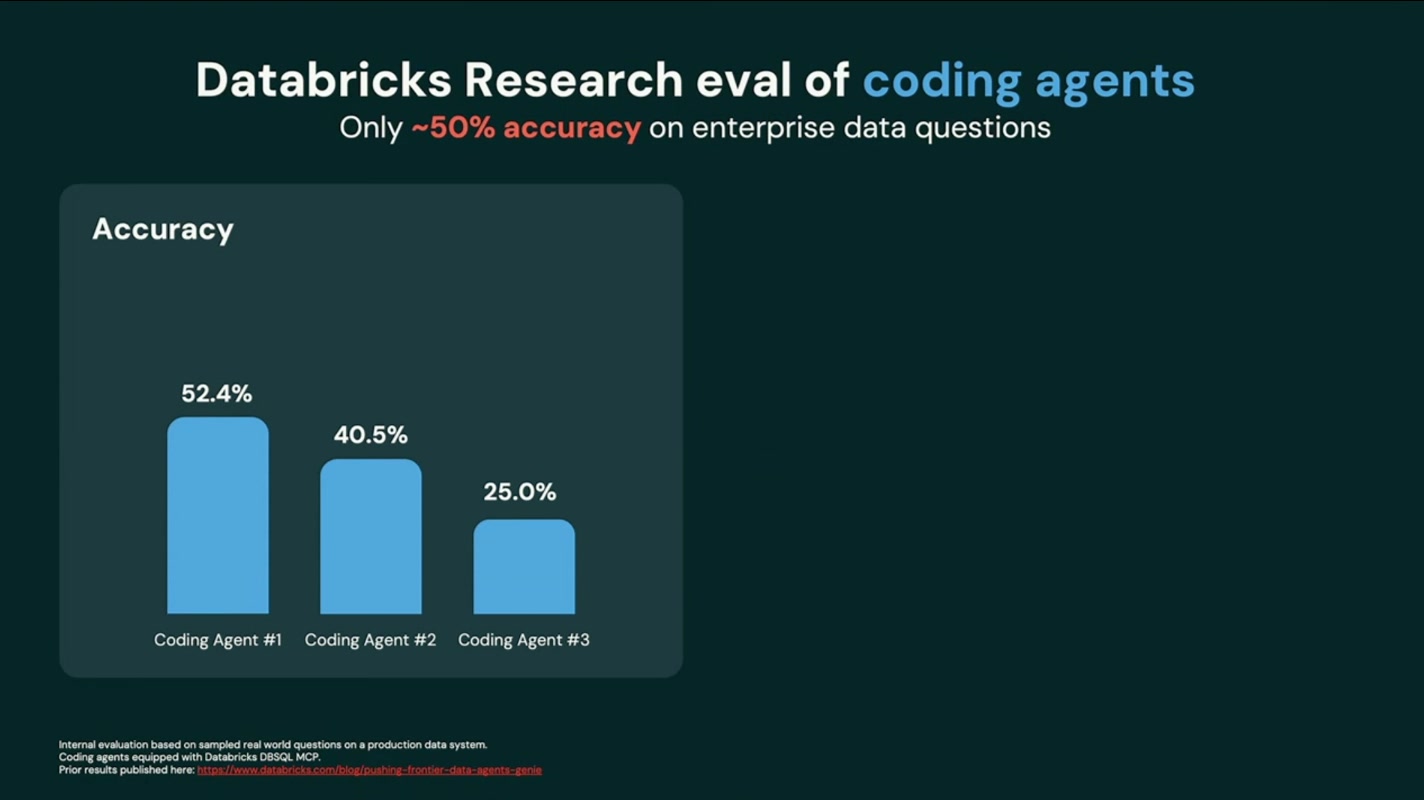
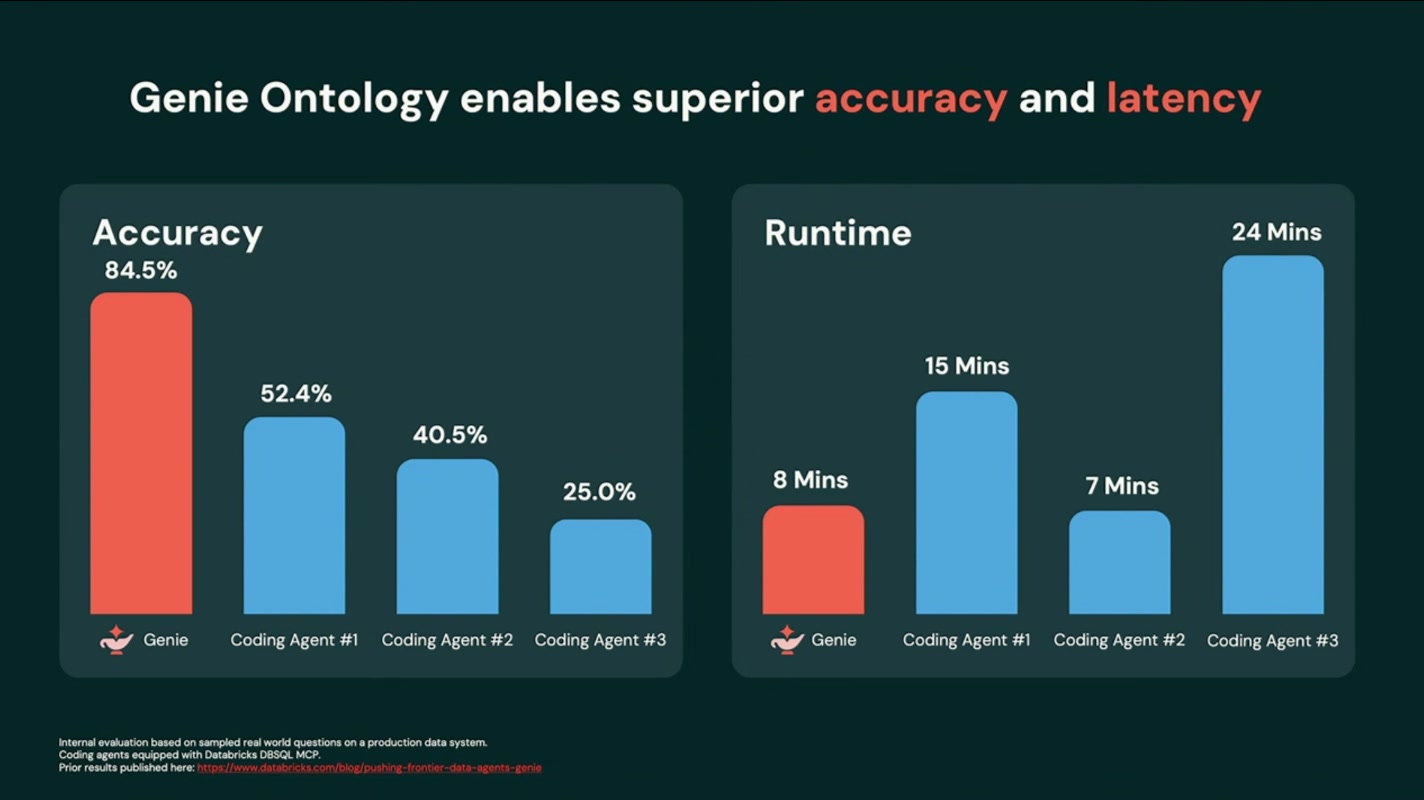
「では、データに強い高機能なコーディングエージェントなら大丈夫では?」という当然の疑問にも、Databricks Research による評価結果で答えました。結果は厳しいものです。エンタープライズのデータに関する質問では正答率が約50%程度(52.4% / 40.5% / 25.0%)。半分前後しか当たらないということは、出てきた答えを毎回人間が検算しなければ使えない、ということでもあります。
しかもスピードも犠牲になっていて、1つの処理に15分38秒かかり、コンテキストの96%を消費する、といった有様。「自動化したはずなのに、結局は人手の確認コストとマシンの待ち時間が増えただけ」という、本末転倒の状態です。
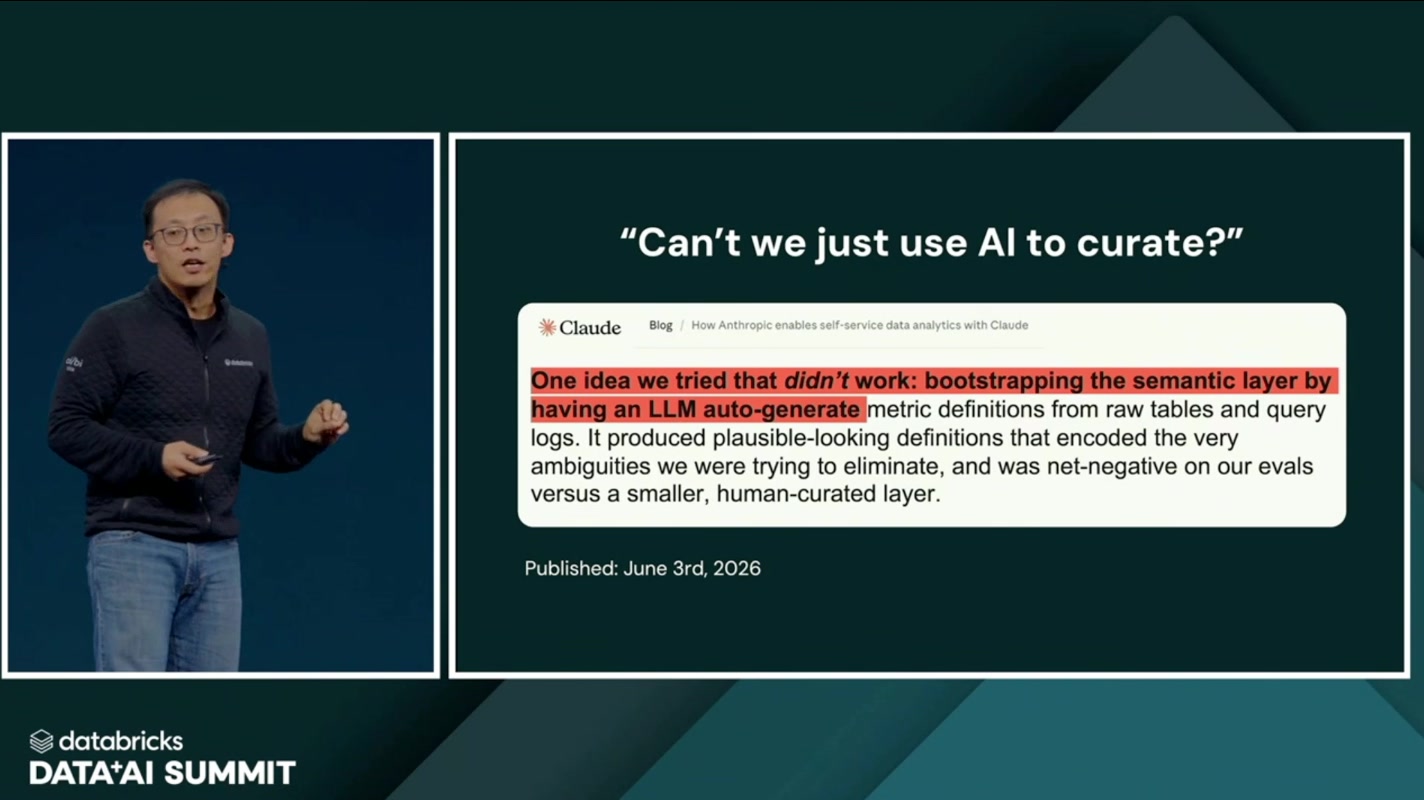
③「AIにセマンティック定義を自動生成させればいい」もうまくいかない
ここで誰もが思いつくのが「正答率が低いのは、AIが社内の言葉や指標の定義を知らないからだ。ならば、AIにメトリクス定義(セマンティックレイヤー)を自動生成させればいいのでは?」という発想です。Databricks もこれをすでに試し、そして失敗したことを正直に共有しました。
LLM が自動生成した定義は”それっぽい”のですが、本来排除したかったはずの曖昧さ——「アクティブユーザーとは何日アクティブな人か」「売上は税込か税抜か」といった、現場ごとに揺れる定義——をそのまま内包してしまう。結果として、人手でキュレートした小さなレイヤーよりも評価がむしろ悪化した(net-negative)とのこと。曖昧なものを大量生産しても、土台が曖昧なままでは精度は上がらない、という教訓です。
なぜ”でっち上げ”と”低精度”が、エンタープライズでは致命傷になるのか
この①〜③の流れは、単なる技術デモを超えて、エンタープライズAIの本質を突いていると感じました。消費者向けのチャットAIなら、答えが多少間違っていても「ちょっと違ったね」で済みます。しかしエンタープライズのデータ業務では、出力の一つひとつが意思決定・予算配分・社外への報告につながる。求められるのは「平均的に賢い」ことではなく「常に正しい、そして間違っていれば根拠から検証できる」ことです。
つまり問題はモデルの賢さ(インテリジェンス)ではなく、そのモデルが何に根拠づけられているか(グラウンディング)にある——これが、続く Genie Ontology のパートへの完璧な前振りになっていました。
答えは「Genie Ontology」と OntoRank
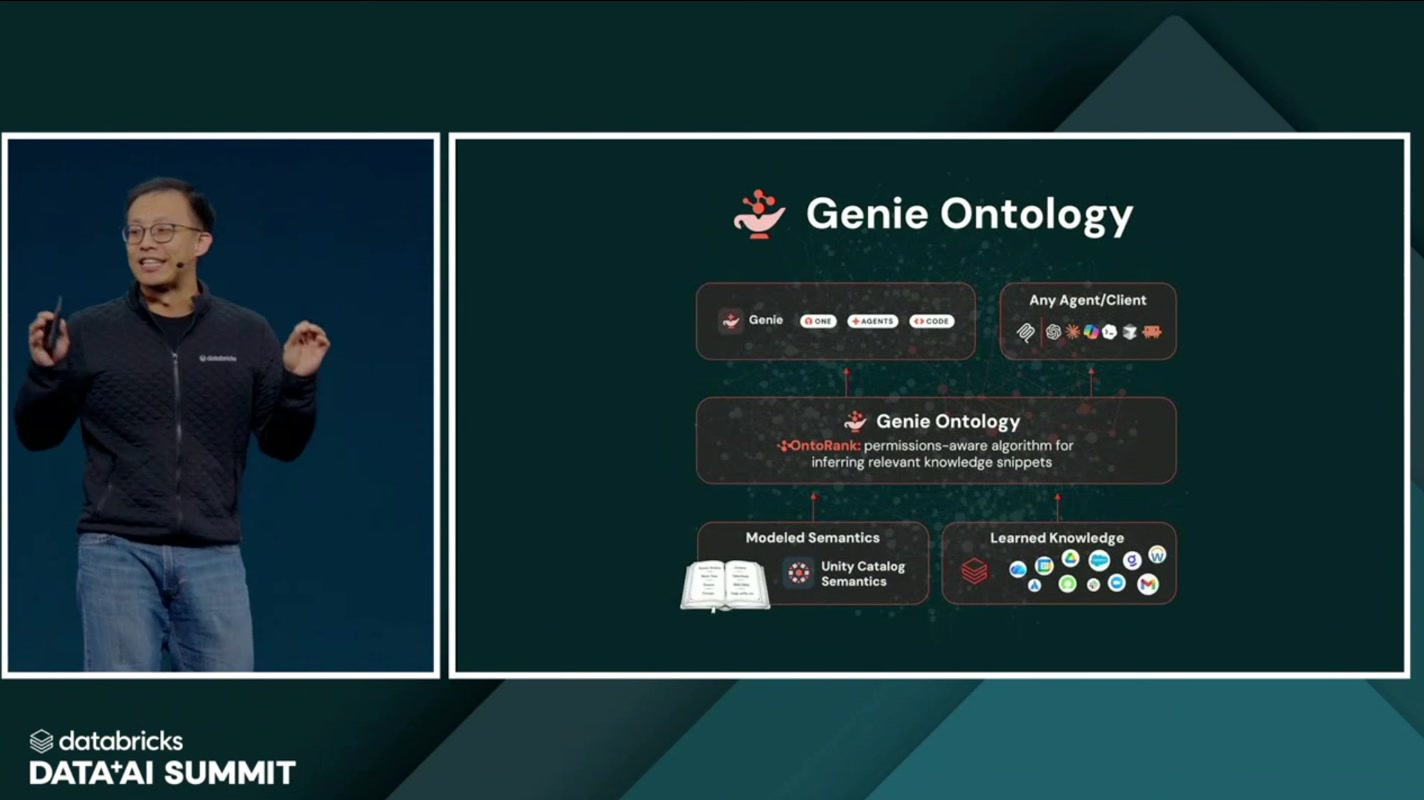
そこで登場するのが、Genie の中核をなす知識基盤 Genie Ontology(ジーニー・オントロジー) です。賢いモデルに「自社の言葉」と「自社のルール」を教え込み、回答を確かな定義に縛り付けるための仕組みと言えます。構成要素は次の3つです。
- Modeled Semantics:Unity Catalog 上でモデリングされた意味定義(人手でキュレートされた確かな定義)。何が真実かを人間が責任を持って決めた、信頼の核となる部分です。
- Learned Knowledge:利用の中で学習された知識。実際の問い合わせや使われ方を通じて積み上がっていく、生きた文脈です。
- OntoRank:権限(permission)を考慮して、関連する知識スニペットを推論するアルゴリズム。膨大な定義の中から「いま、この質問に、この人が見てよい範囲で」関係するものを選び出します。
このオントロジーで根拠(grounding)を与えることで、精度とレイテンシが劇的に改善。スクリーンでは Genie が正答率 84.5%/所要約8分 と、前述のコーディングエージェント(25〜52%/7〜24分)を大きく上回る結果が示されました。「賢いモデルそのもの」ではなく「賢いモデル+確かな根拠」が、精度と速度を同時に押し上げるという、説得力のある数字です。
OntoRank の「権限を考慮した検索」が実務で意味すること
3要素の中でも、個人的に最も実務的だと感じたのが OntoRank です。一般的なRAG(検索拡張生成)は「質問に関連する情報を引っ張ってくる」ところで止まりがちですが、OntoRank は 権限(permission)を考慮してスニペットを選ぶ、という点が大きく違います。
これが現場で何を意味するか。たとえば人事データや個別案件の売上といった機密情報は、本来「見てよい人」と「見てはいけない人」が分かれています。ところが普通のAIアシスタントは、いったんデータを取り込んでしまえば、誰が質問しても同じ答えを返しかねません。OntoRank のように検索の段階で権限を織り込めば、「答えそのものが、その人の閲覧権限に沿った範囲で組み立てられる」ことになります。
精度・速度の話に隠れがちですが、これは”ガバナンスを後付けの制限ではなく、回答生成の前提として組み込む”という設計思想であり、Unity Catalog を土台に持つ Databricks らしいアプローチだと感じました。AIの同僚を社内に迎えるうえで、最も気になる「見せてはいけないものを見せてしまわないか」という不安に、アーキテクチャの段階で答えている点が重要です。
「Genie One — The data-smart AI coworker」発表
さて、ここで前振りを回収する形で、いよいよ本命の発表です。Genie One、データを理解するAIの同僚。単なる「賢いチャットボット」ではなく、根拠(オントロジー)を背負ったまま実務をこなす”同僚”として位置づけられています。
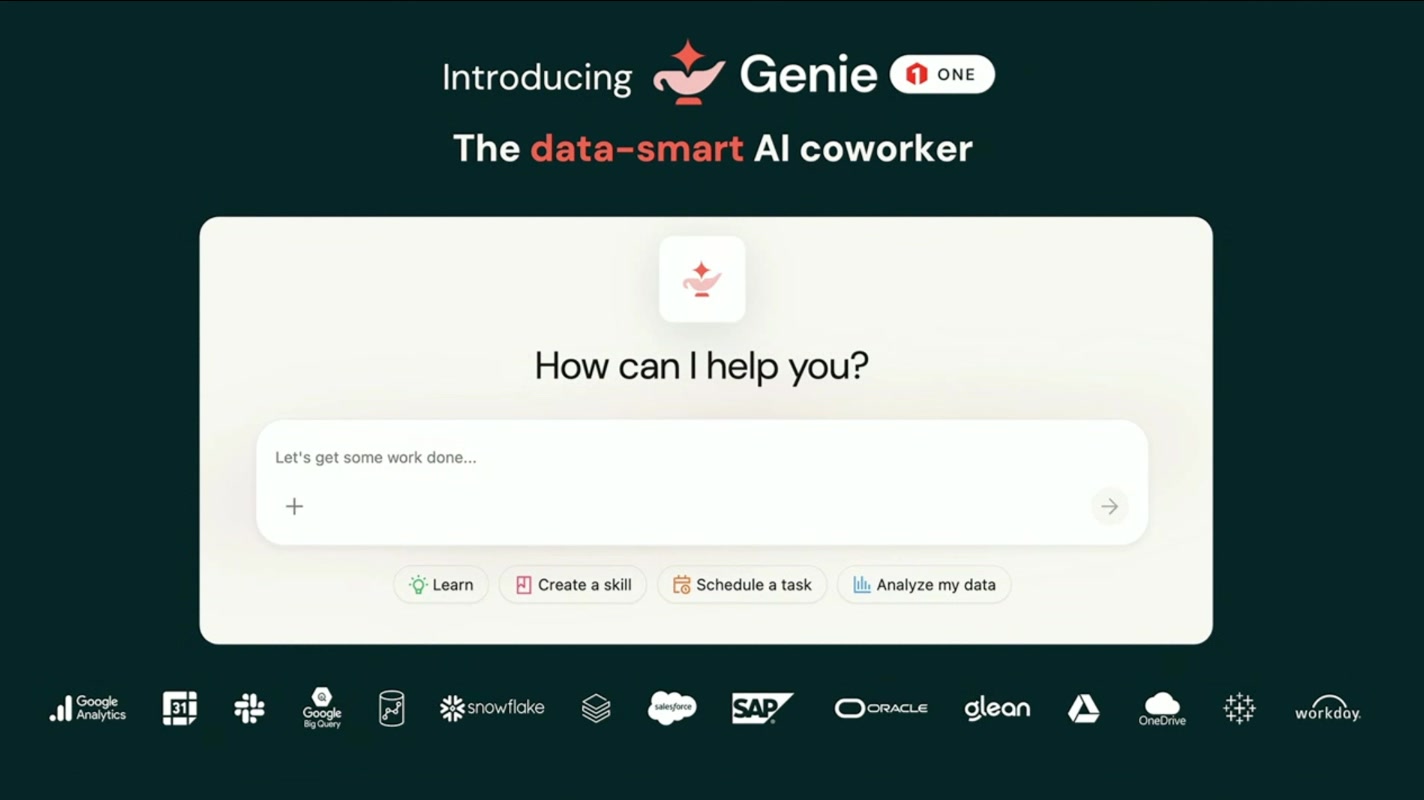
特徴として強調されたのが、その圧倒的な接続性です。Google Analytics、Slack、Google BigQuery、Snowflake、Salesforce、SAP、Oracle、glean、Google Drive、OneDrive、Workday など、あらゆる業務システムに接続できる。データウェアハウスだけでなく、課題管理・チャット・ドキュメント・基幹システムまで横断できるからこそ、「データを理解する」だけでなく「実際に仕事を片付ける同僚」になり得るわけです。チャットUIには「How can I help you?(何をお手伝いしましょう?)」と表示され、まさに席の隣にいる同僚に仕事を頼む感覚で使い始められます。
ライブデモが圧巻だった
ここから PM の Elise Georis 氏によるライブデモへ。スライドの説明ではなく、その場で実際に Genie One に仕事を任せる構成です。お願いした指示(プロンプト)はこちら。
“Draft a Genie Mobile App exec review using this template: [Google Docsのテンプレートリンク]. Make sure to include this week’s engagement by region. For each open blocker in Jira, give me the current status, and ping the assigned ticket owner for a new update.”
(このGoogle Docsテンプレートで Genie モバイルアプリのエグゼクティブレビューを作成して。地域別の今週のエンゲージメントを必ず含めて。Jiraの未解決ブロッカーそれぞれについて現状を教え、担当者に最新状況をリマインドして。)
注目したいのは、この指示が一つのタスクではなく、「テンプレートに沿った作成」「データの集計」「課題の状況確認」「担当者へのリマインド」という、本来なら部署をまたいで人間が手分けして行う複数の作業の塊だという点です。普通なら、データチームに数字を依頼し、PMがJiraを開いて担当者をつつき、それを資料に貼り付けて……と、半日仕事になってもおかしくありません。Genie One はこれを受けて、自律的に次のステップを実行していきました。

- Genie Ontology を検索して「自分はこの定義に根拠づけられている」と確認
- Google Drive のドキュメントを読込(戦略ドキュメント+OKRレビューのテンプレート)
- Jira を JQL で検索して未解決ブロッカーを取得
- Jira にコメントを追加し、優先度の高いブロッカー(例:GENIE-1422 NAMERのOAuthログイン不具合)の担当者に状況をリマインド
- SQL を複数実行(Unity Catalog + BigQuery のGA4/Firebaseデータを横断)
- ビジュアライゼーションを生成
特に印象的だったのは、最初のステップで Genie One が真っ先に Genie Ontology を検索し、「自分はこの定義に根拠づけられている」ことを確認してから動き出した点です。いきなり数字を作りに行くのではなく、まず”何が真実か”を取りに行く。①で見た”でっち上げAI”とは、思考の出発点からして別物でした。
その結果、地域別エンゲージメントの棒グラフも自動生成。「LATAM が前月比+84%で急伸、NAMER だけが-4%で唯一の遅れ——v4.3のOAuthログイン不具合(GENIE-1422)が足かせ」といった、単なる数字の羅列ではなく示唆まで文章でまとめてくれます。データを出すだけでなく「で、何が言えるのか」「次に何をすべきか」まで踏み込むのが、まさに”同僚”らしいところです。
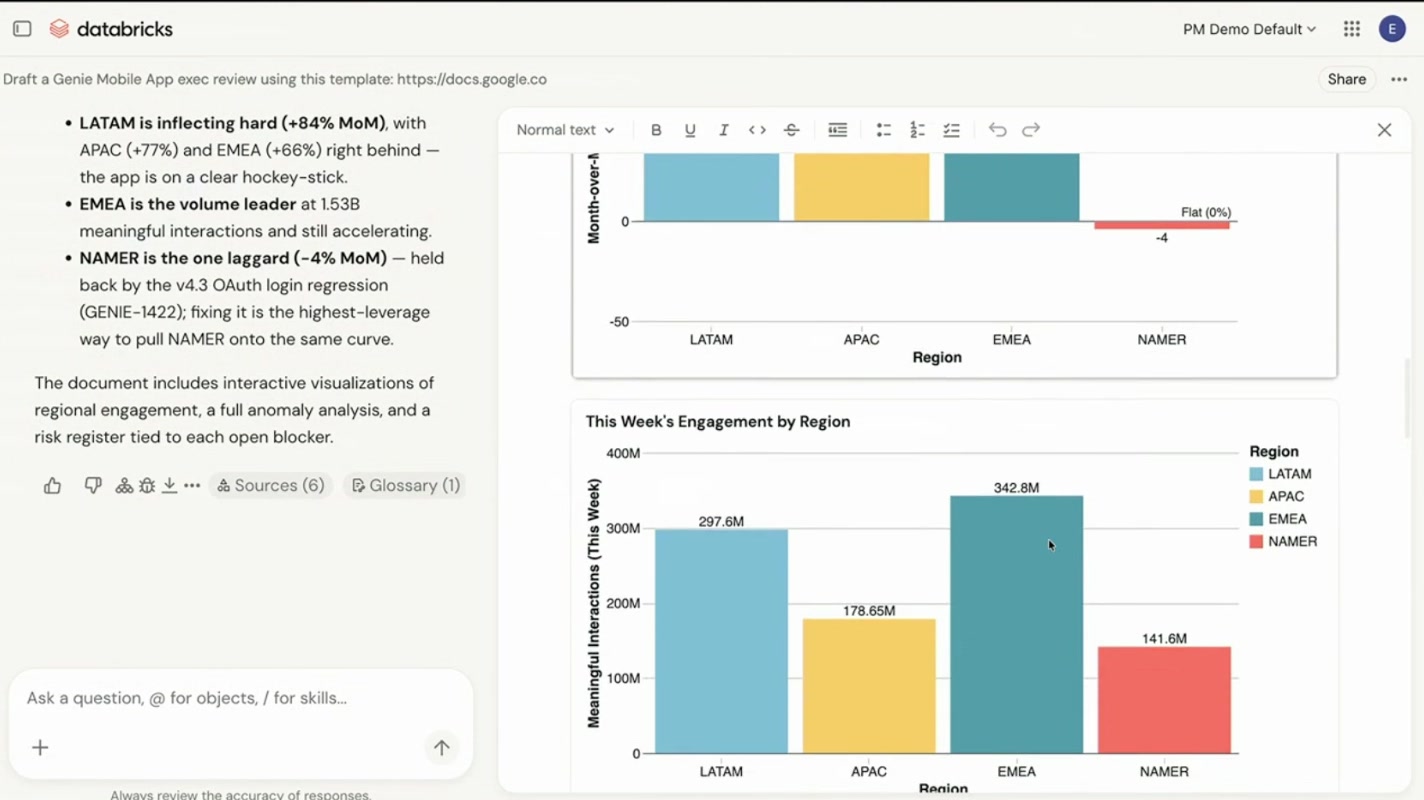
しかも完成ドキュメントには Sources(6) / Glossary(1) / Genie Ontology(3) といった根拠バッジが付与され、用語にカーソルを合わせるとオントロジー上の定義(ドメイン・オーナー・同義語)がポップアップ。「この数字は6つのソースに基づき、3つのオントロジー定義に根拠づけられている」と一目でわかるわけです。冒頭の”でっち上げ”とは対極の、すべての出力が根拠に紐づいて追跡できる出力になっています。資料を受け取った側が「この数字どこから?」と問い詰めても、即座に出所が示せる——この一点だけでも、現場で使えるAIかどうかの分水嶺になると感じました。
そのワークフロー、そのまま”再利用できるエージェント”に
そして圧巻だったのが仕上げです。一回きりの便利なデモで終わらせず、この一連のワークフローを 「Mobile App performance review agent」として保存してみせました。認証済みKPIに根拠づけられた、再利用可能なエージェントの完成です。来週も、来月も、同じレビューを同じ品質で生成できる。そのうえで 「pm@databricks.com に共有して」 と頼むと、チームに即共有完了。
ここが本質的に効いてくるところで、これまで「特定の誰かの頭の中」「特定の誰かのスプレッドシート」に閉じていた属人的な分析手順が、その場で組織の共有資産に変わったのです。優秀な担当者の暗黙知を、根拠つきのエージェントとして横展開できる——分析の民主化という言葉が、ここでようやく具体的な形を持ったように見えました。
任意のAIツールからも使える「MCP App」
Genie One は Databricks の中だけのものではありません。MCP App により、Claude・ChatGPT・Microsoft Copilot などお好みのAIツールから Genie(自社データ)を呼び出せるとのこと。
これは地味に見えて、導入の現実を踏まえた重要な一手です。多くの企業ではすでに何らかのAIツールが現場に根付いていて、「全部 Databricks のUIに移ってください」とは言いにくいもの。MCP App を介せば、ユーザーは使い慣れたツールのまま、その裏側で Genie のオントロジーに根拠づけられた自社データへ安全にアクセスできます。「賢い回答の源泉」を Genie 側に集約しつつ、入り口は自由に選べる、という構図です。こちらは Available now(提供中)。
さらにモバイルアプリ(iOS / Android)も提供。デスクの前にいないときでも、移動中でも、AIの同僚をポケットに、というわけです。
気になる提供形態
クロージングのスライドで提供形態も明示されました。新機能の発表でありがちな「近日公開」「順次提供」ではなく、提供時期と価格をその場で示したあたりに、Databricks の自信がうかがえます。
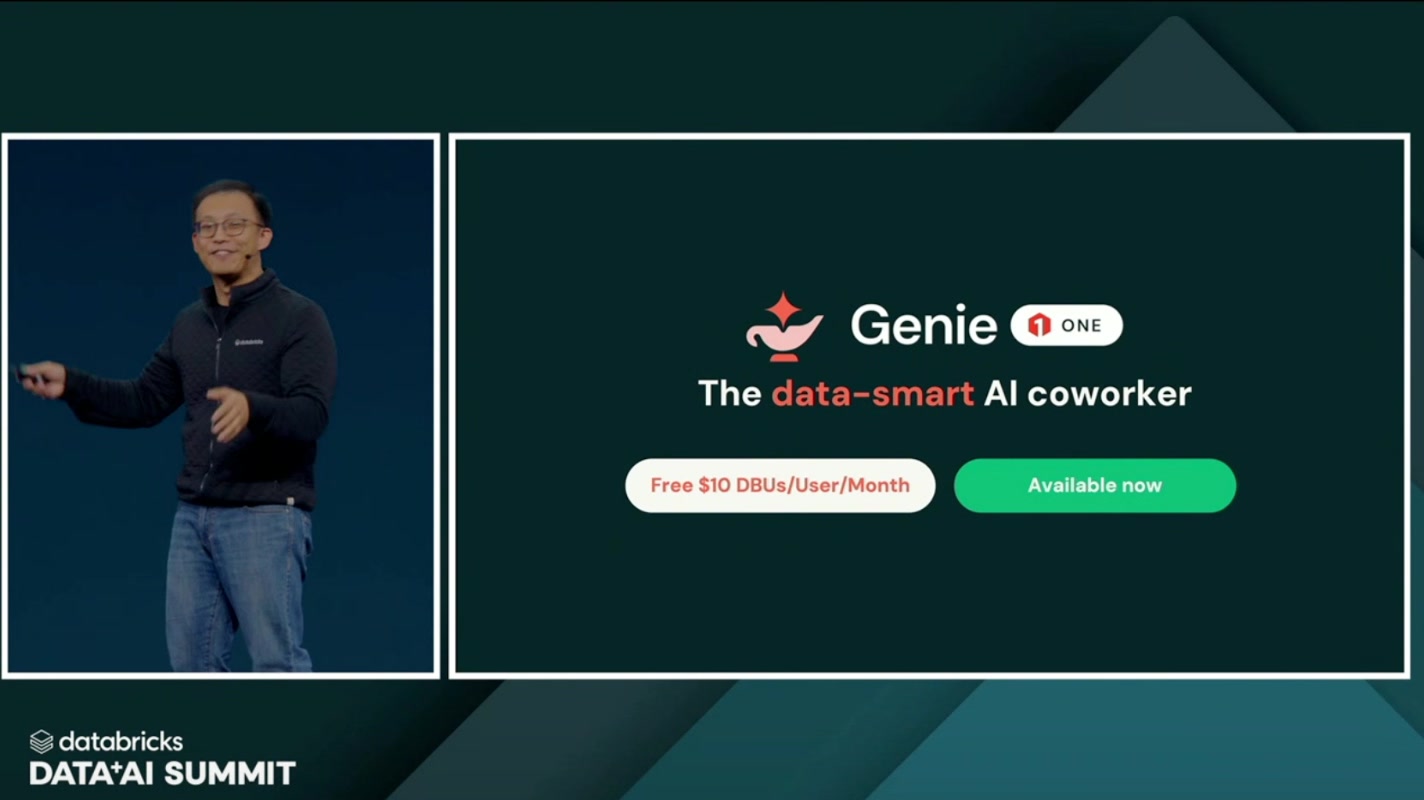
- Genie One — The data-smart AI coworker
- Free $10 DBUs / User / Month(ユーザーあたり月10ドル分のDBUが無料)
- Available now(提供中)
ユーザーあたり月10ドル分のDBUが無料で付くという点は、「まず触ってみてほしい」というメッセージに読めます。エンタープライズ向け機能はとかく検証のハードルが高くなりがちですが、すぐ試せる枠が用意されていることで、PoC(概念実証)の最初の一歩が踏み出しやすくなります。
まとめ・所感
Genie One は、「賢いモデル」を「実務で使えるAIの同僚」に変えるための、根拠(オントロジー)と接続性(コネクタ)とガバナンスをまとめて提供する発表でした。
このセッションの構成は、振り返るほどよく練られていたと感じます。まず①〜③で”既存AIの失敗”を実演して聴衆に痛みを思い出させ、その痛みの原因が「賢さ不足」ではなく「根拠不足」であることを示し、そのうえで Genie Ontology / OntoRank という処方箋を提示する。最後にライブデモで、根拠づけられたエージェントが半日仕事を数分でこなし、しかもその場でエージェント化・共有まで完結させる。”でっち上げAI”を笑いに変えつつ、Genie Ontology / OntoRank で正答率84.5%を叩き出した対比は、技術の優位性を数字と物語の両面で印象づけました。
所感として強く残ったのは、この発表が「もっと賢いAI」を売っているのではなく、「信頼できるAI」を売っている、という点です。エンタープライズでAIが本当に定着するかどうかは、デモのきらびやかさではなく、「出した答えの根拠をたどれるか」「見てはいけないものを見せないか」「優秀な人の手順を組織で再現できるか」という、地味だが本質的な条件で決まります。Genie One は、そのどれにも具体的な答えを用意してきた。エンタープライズAIの「最後の1マイル」を埋めにきた、という印象です。
次回はデータエンジニアリング領域、Lakeflow と Genie ZeroOps をレポートします。
参考リンク
*#DAIS2026 #Databricks #Genie #GenieOne #AIエージェント #現地レポート*