
DataikuでSIGNATEコンペの2値分類予測したモデル作成手順紹介とDataikuの感想を記載しています。この記事を読んでDataikuの魅力点や全体的な流れについて少しでもイメージできれば幸いです。
はじめに
第2回金融データ活用コンペにDataikuを用いて参加しました。今回のコンペの概要としてローンを返済したかしていないかいないかの2値を予測するコンペになっています。評価指標はmeanF1scoreです。データセットはこちらにあります。
https://signate.jp/competitions/1325#disclosure-policy
まず最初にざっくりDataikuを使ってみた感想と魅力点についてまとめました。そのあとに実際にどのような機能があり、2値分類に対してどのようなアプローチができたのか詳細にお話したいと思います。
【コンペ結果】
結果として作業時間はほぼ2日間程度になってしまい1150人中340位となりました。微妙な結果ですが、作業時間などを考えたら効率よく出来たのかなと思います。ほぼ2日間でEDA~多種のモデルアルゴリズムでベースラインモデルを確立し、特徴量パターンを4種類以上作り、アンサンブルなどを試せました。
また、SiNCEとして他のチームの方が入賞できたので喜ばしい限りです。(私は関わっていないですが笑)
【Dataiku熟知度】
このコンペ以前からDataikuについては知っており、具体的に業務などで使っていましたので他の参加者に比べたら前提知識などのアドバンテージはあったのかなと思います。これが良い機会でしたのでDataikuの以下の認定証を取得しました。
・MLプラクティショナー認定証
・コアデザイナー認定証
【Dataiku関連の記事】
以前にもDataiku関連に関する記事を書いているので、良かったらご覧下さい。
・https://blog.since2020.jp/ai/dataiku-dssの導入に迷っている方必見!3つのインストー/
・https://blog.since2020.jp/ai/dataikuでbigqueryのデータを分析!簡単な連携方法と使い方/
・https://blog.since2020.jp/ai/dataiku_review/
・https://blog.since2020.jp/ai/gcp上にdataiku-dssをセットアップする方法を解説!/
Dataikuを使ってみた感想と魅力点
Dataikuを使用した感想は、機械学習モデル構築のPDCAサイクルが驚くほど迅速に進められる点に魅力を感じました。データの分析、加工、様々なアルゴリズムでの予測実験がノーコードで手軽に行え、コーディングに費やす時間がほぼゼロに等しいのが素晴らしいです。ノーコードへの不安もあるかもしれませんが、基本的な機能は十分に備わっており、機械学習の知識がある方にとっても満足できる機能が揃っています。
さらに、複数の実行を同時に行えるため、モデル学習にかかる時間を有効活用しながら他のデータの加工や分析も進めることができます。作業のフローは視覚的かつ整理しやすく、フローをコピー&ペーストすることで同じ処理を容易に再利用できます。これにより、作業の途中での変更も柔軟に行え、チームでの共有にも向いています。
総じて、Dataikuを試してみた感想は、機械学習モデル構築の短時間化とデータサイエンスの知識がある人にとっては開発が劇的にスムーズに進むプラットフォームだと感じました。
2値分類予測モデル構築手順の概要
それではどのようにモデルを構築したのか手順の概要をご紹介します。
【全体図】
複数の学習データのパターンから機械学習モデル構築をしました。また、US州のオープンデータなども新規特徴量として追加して試してみたりしました。
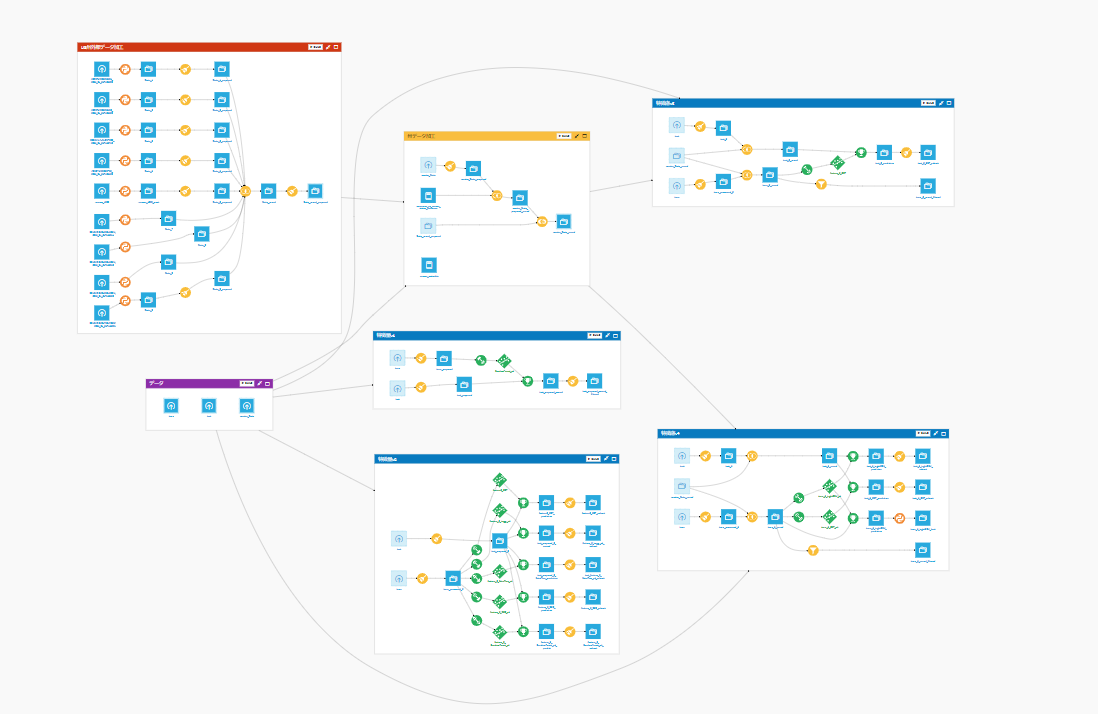
【ベースモデル構築部分】
ここでベースとなるモデルを作成しています。
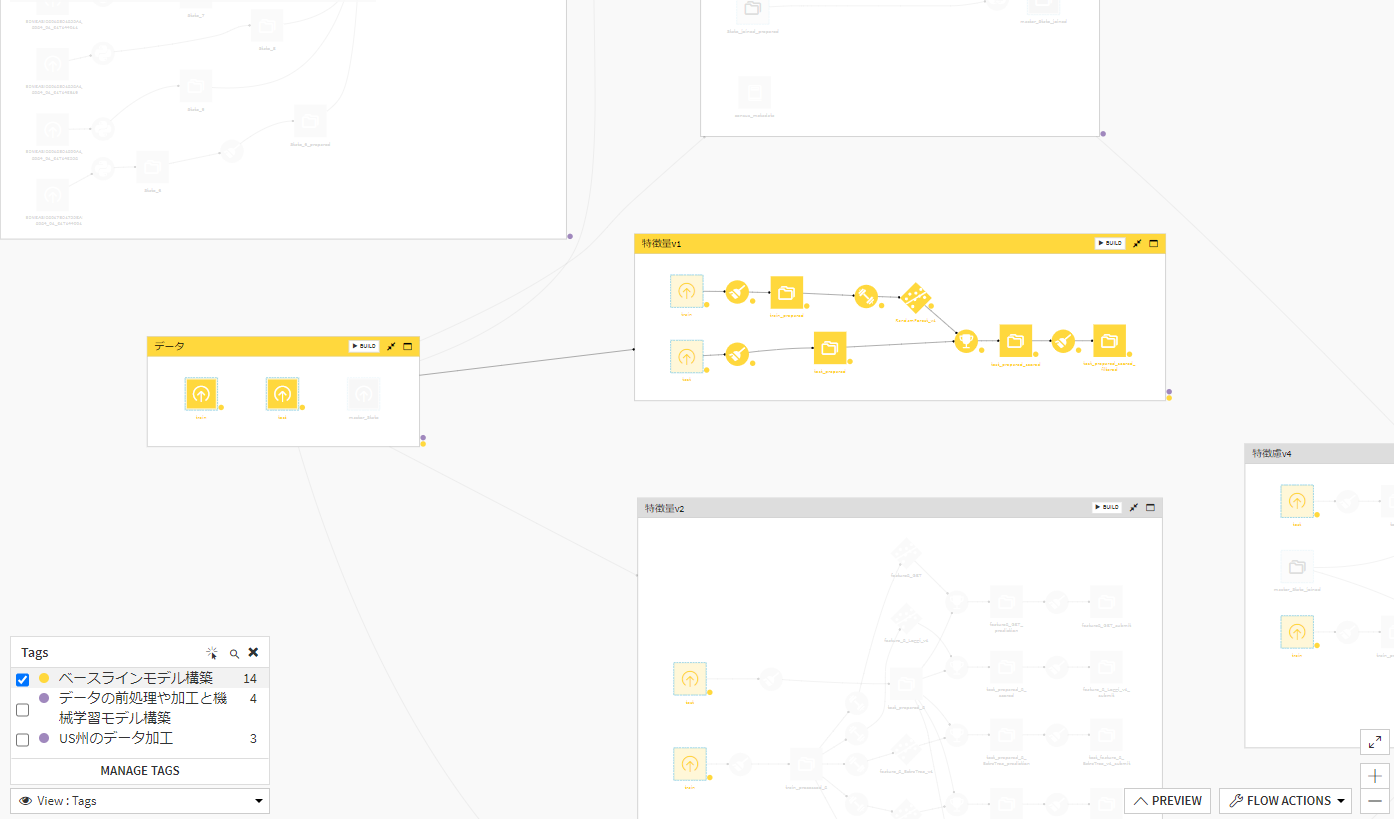
【データ前処理からモデル構築部分】
ここでは複数の学習データに分け、それぞれ複数の機械学習モデルで構築しています。特徴量パターンごとにゾーン(四角い枠のこと)に分けています。

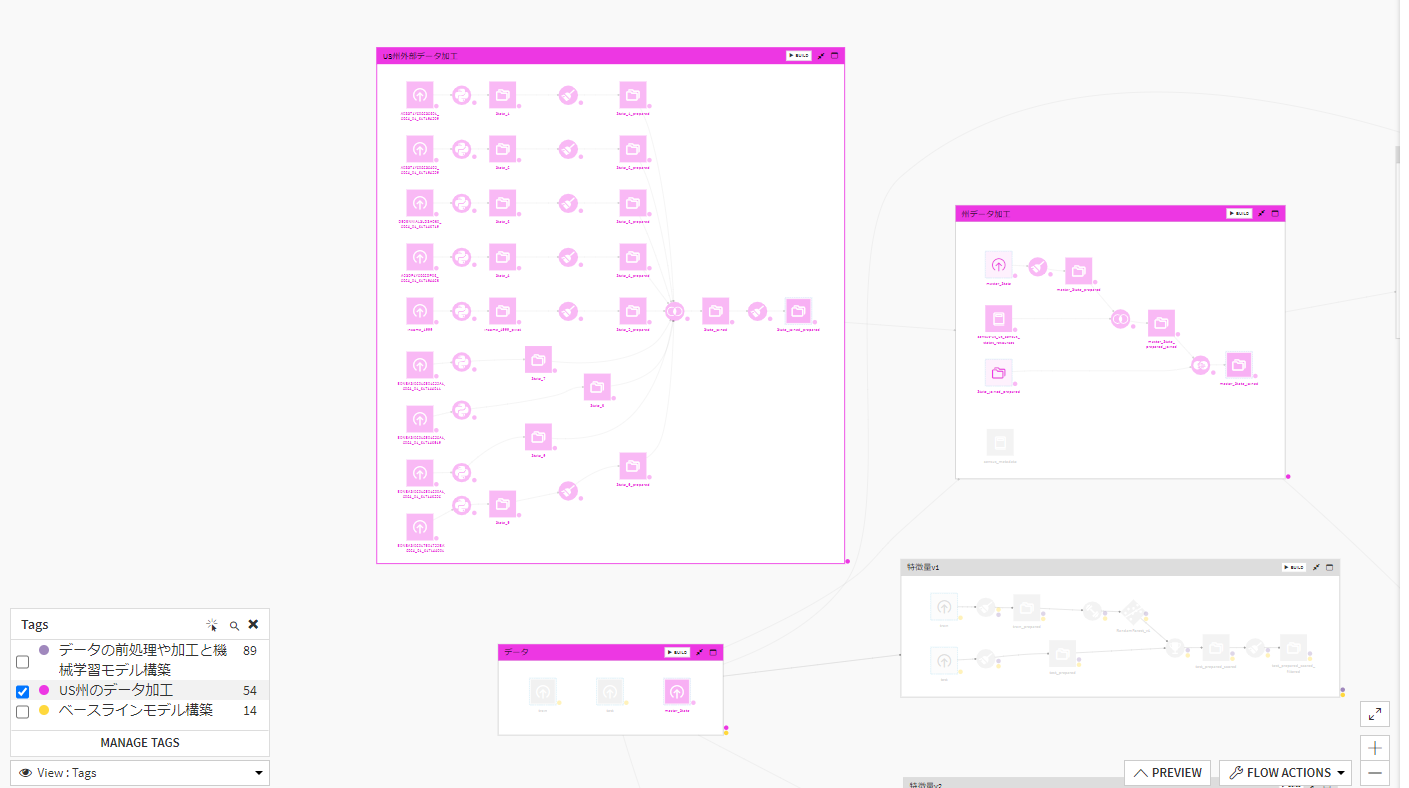
【US州のデータ加工部分】
ここでUSの州データとして外部データを追加し、加工しています。
手順1.EDAをやってみる
とりあえずどのようなデータがあるのかEDAを行ってみました。記事はこちらに記載しています。
【Dataiku】簡単に全列のnullや外れ値を確認し、EDAしてみる
手順2.ベースラインモデル構築
最低限の加工を行って、複数の機械学習モデルで実験し、ベースラインモデルを構築しました。
2-①データの加工データの加工は以下のものを行いました。
日付を変換し、欠損値を埋め、日付から要素を抽出し、金額のデータを数値に置き換えています。
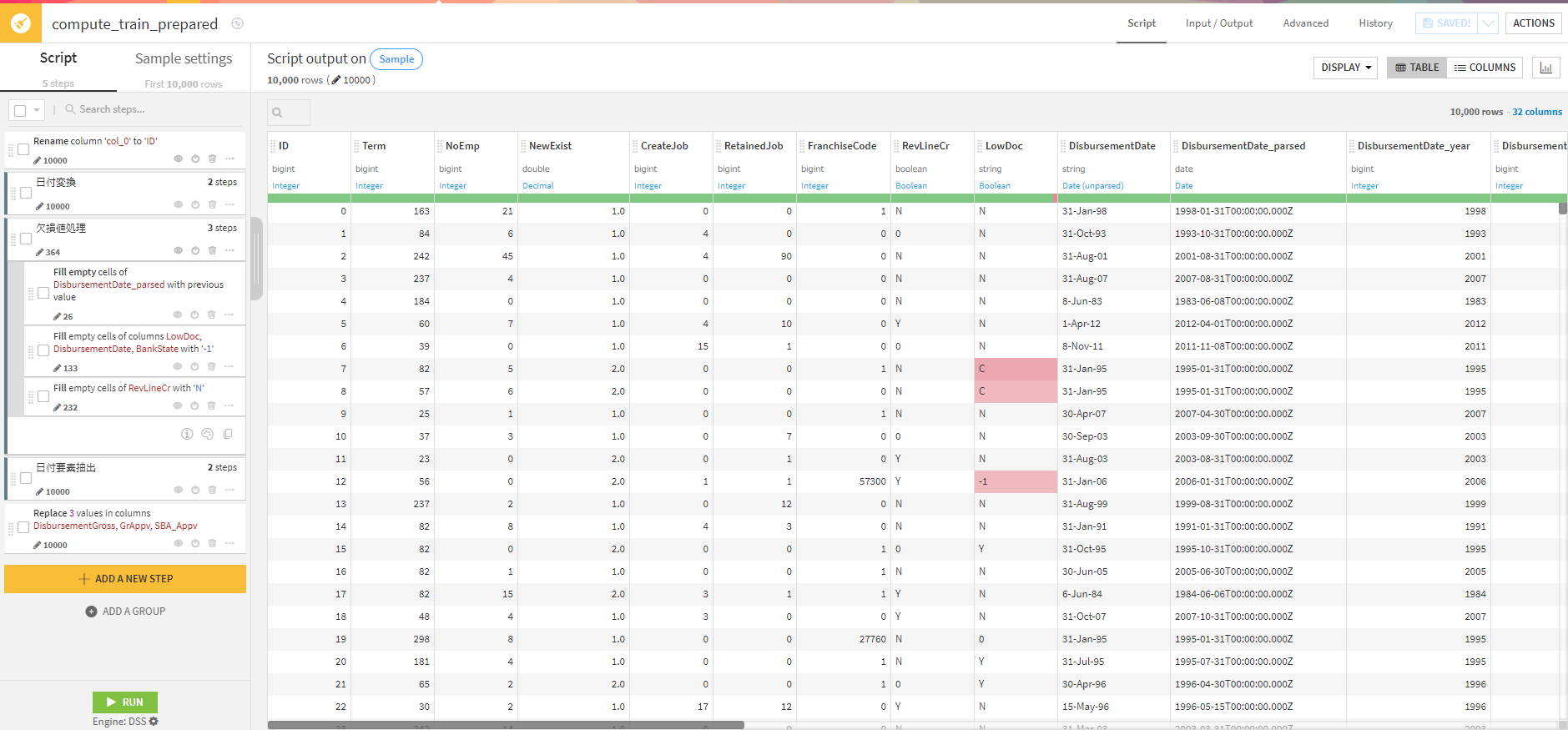
列名の変換はカラムの名前部分をクリックし、「Rename」で変換します。
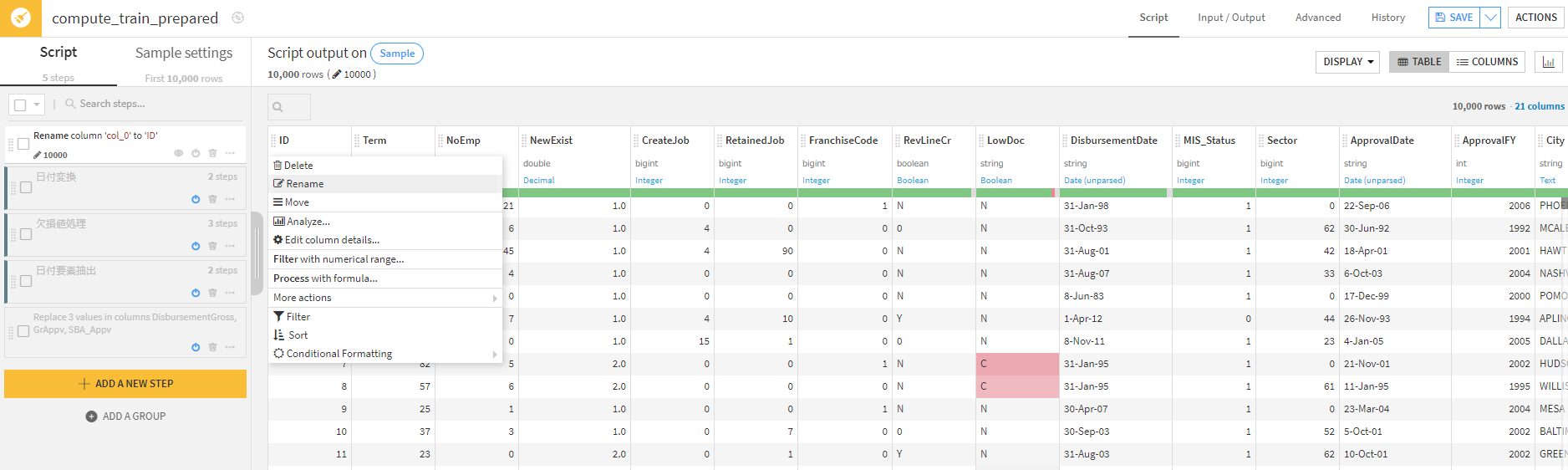
日付の変換などはカラムの名前部分をクリックし、「Parse date…」でさっと変換できました。
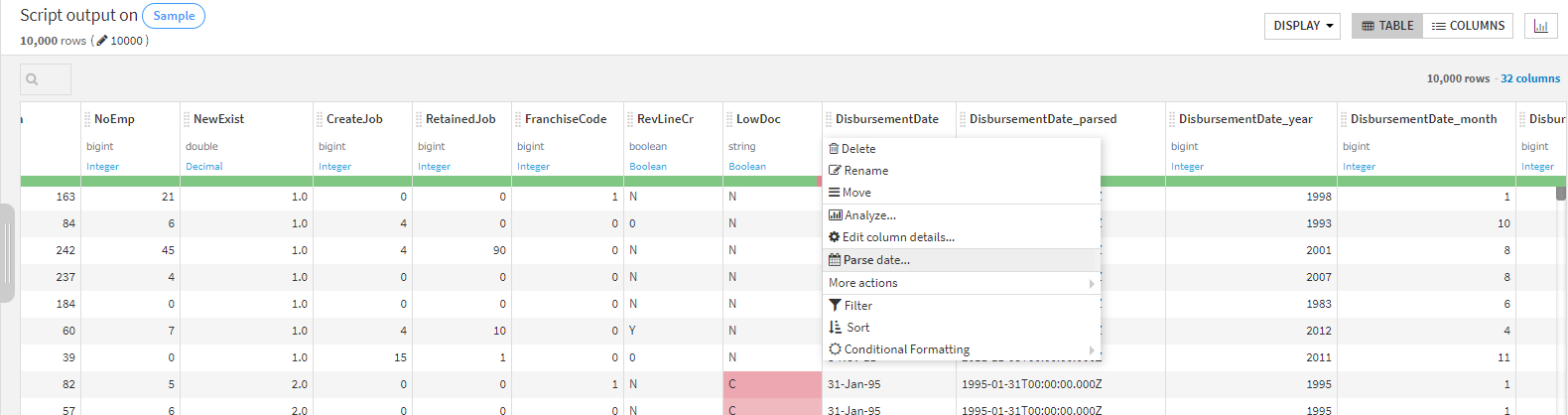
また、欠損値の補完も「More Actions」から「Fill empty with ….」でさっと行えます。
※左のステップを見ると分かりますが、このように加工処理をステップのように記載し、加工の順番を変えることも可能ですし、手順をグループ化することも可能です。また、加工の処理を一時的に非表示にしたり無効にできます。その他の便利な機能としては加工ステップをコピーし、別のところで全く同じ加工処理を行えます。
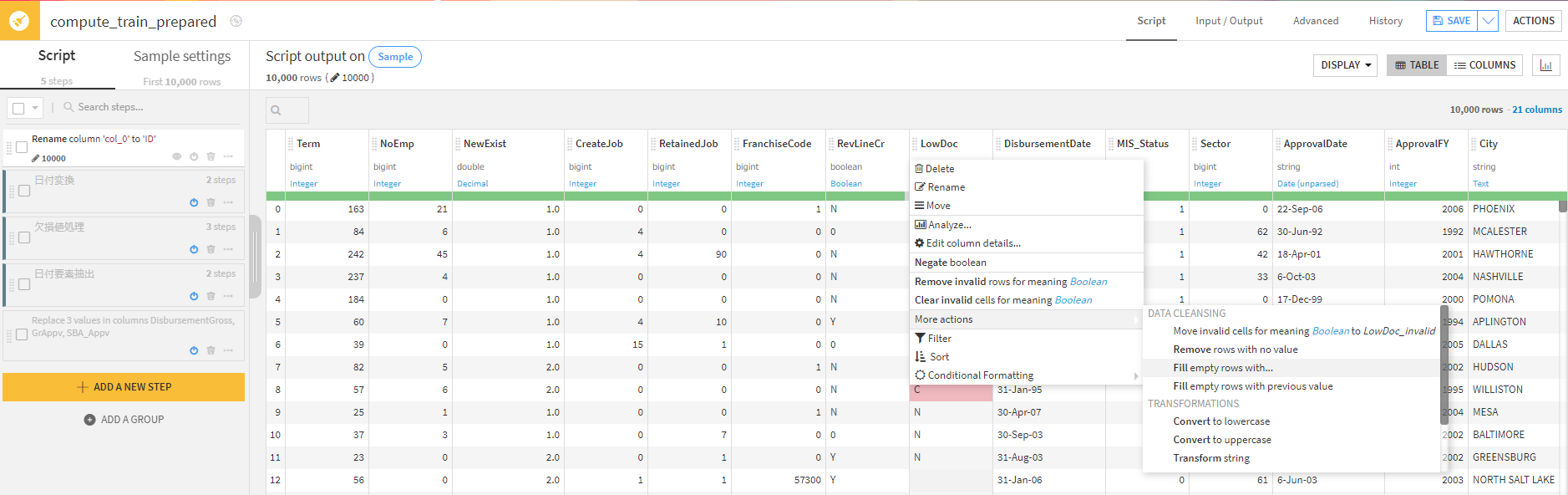
金額の加工も「Find and Replace」から行えます。
左のステップに詳細がありますが、複数カラムを同時に具体的に指定して何をどのように変換するか決めれます。
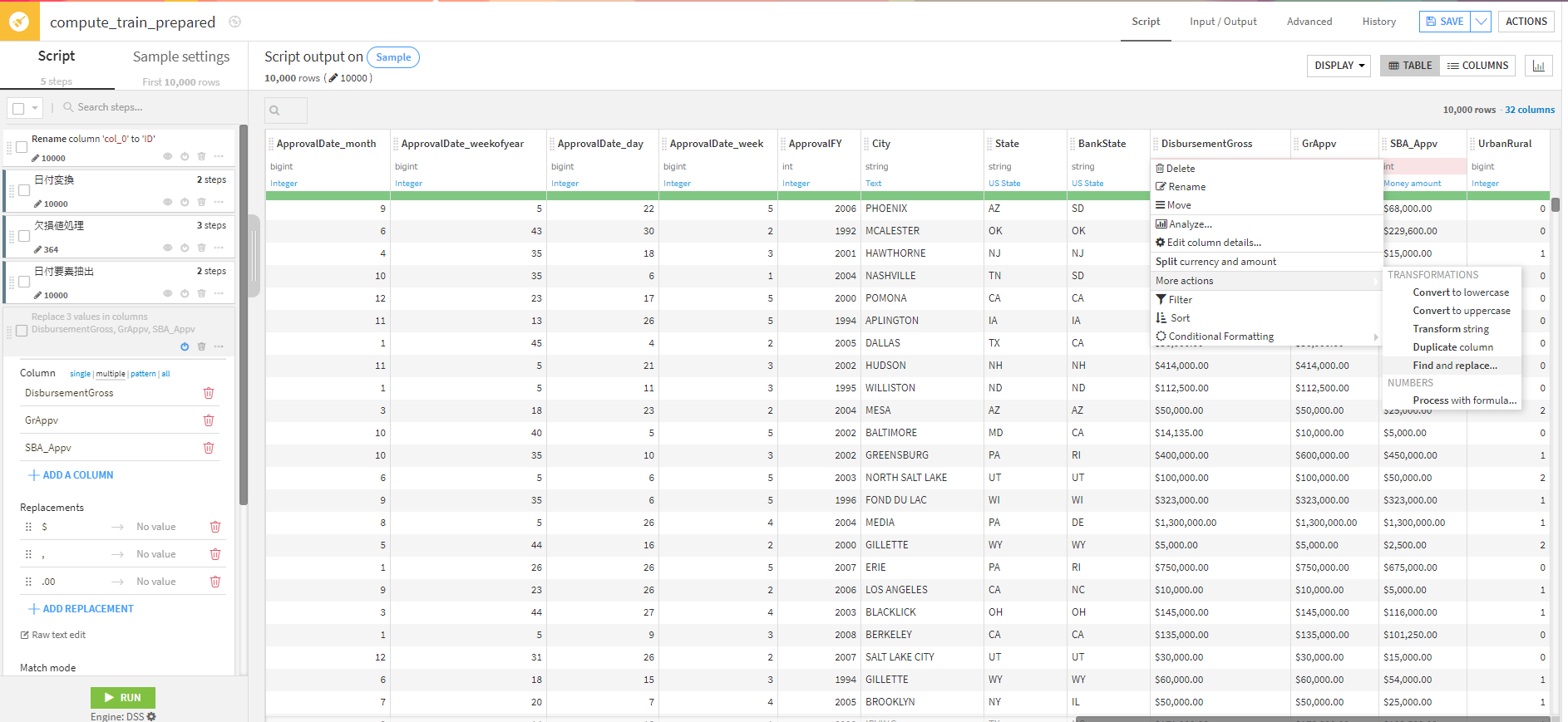
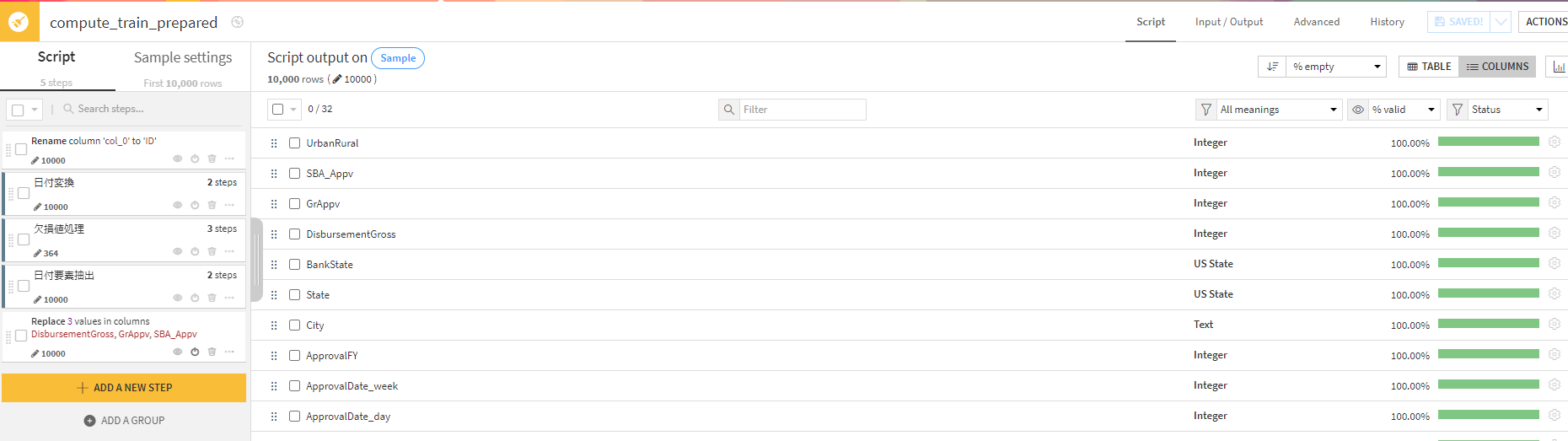
こうすることで、もともとnullの行があったのですが、欠損値処理などを行えました。
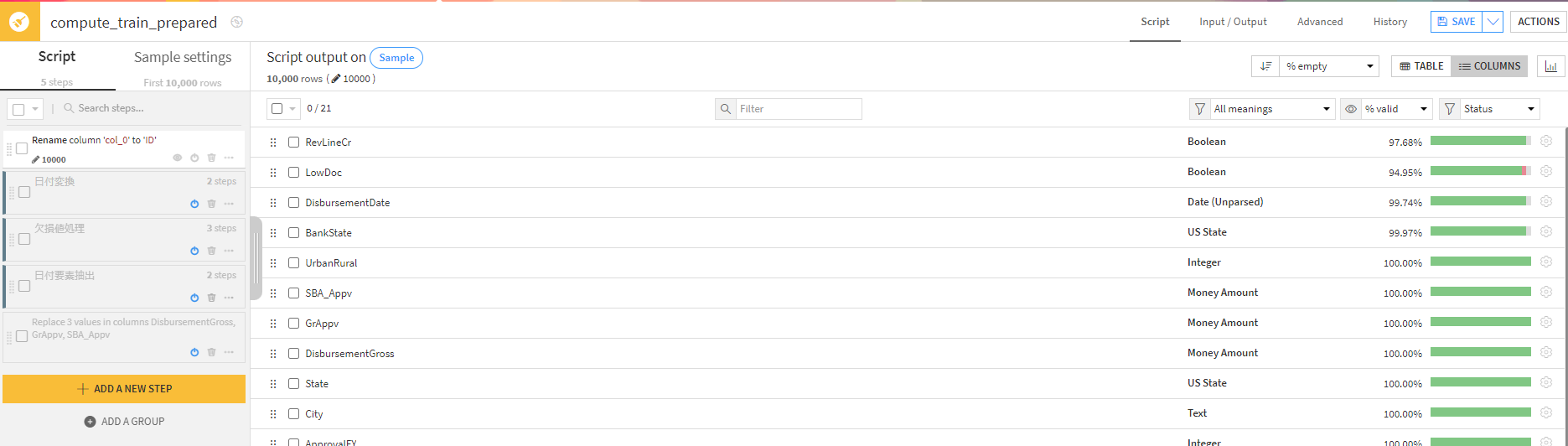
【加工前】
※こちらはemptyの割合が高いカラムから並び替えて表示しています。勿論ほかの指標(invalidなど)で並び替え可能です。
【加工後】
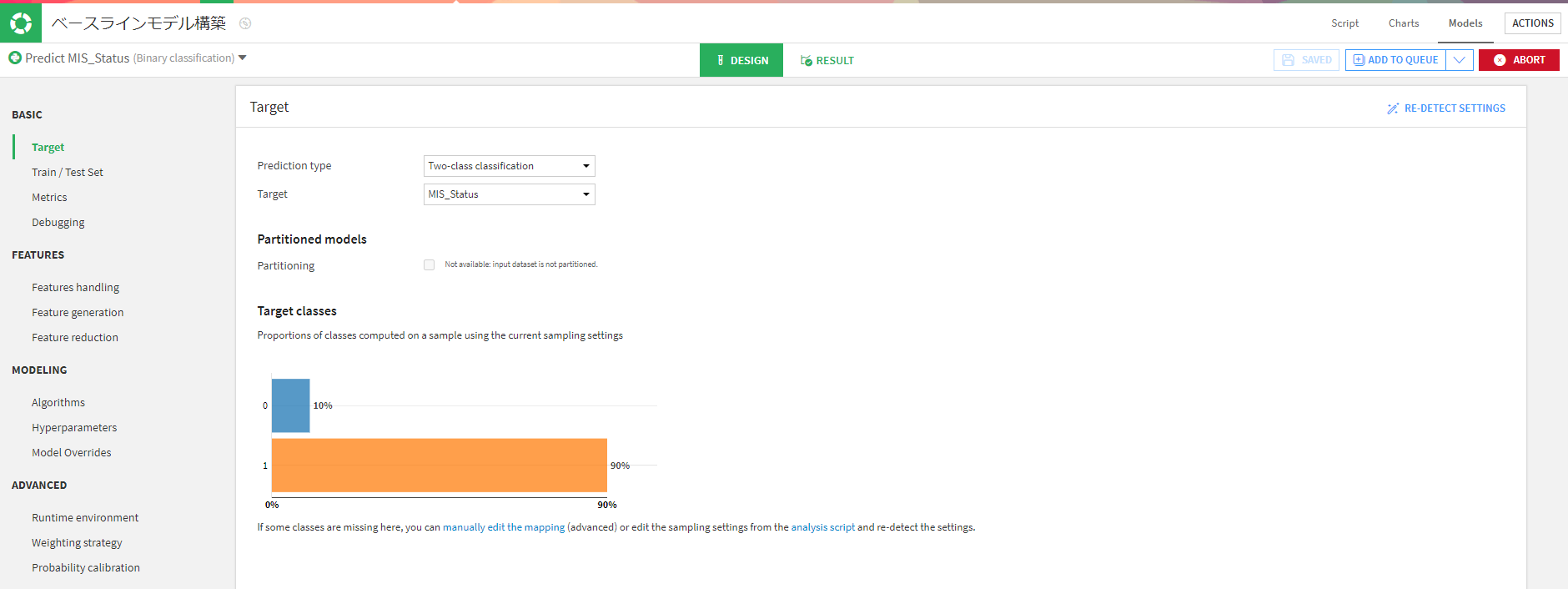
どのようなモデルを構築するのか定義します。今回は2値分類でそれぞれの割合も出してくれています。
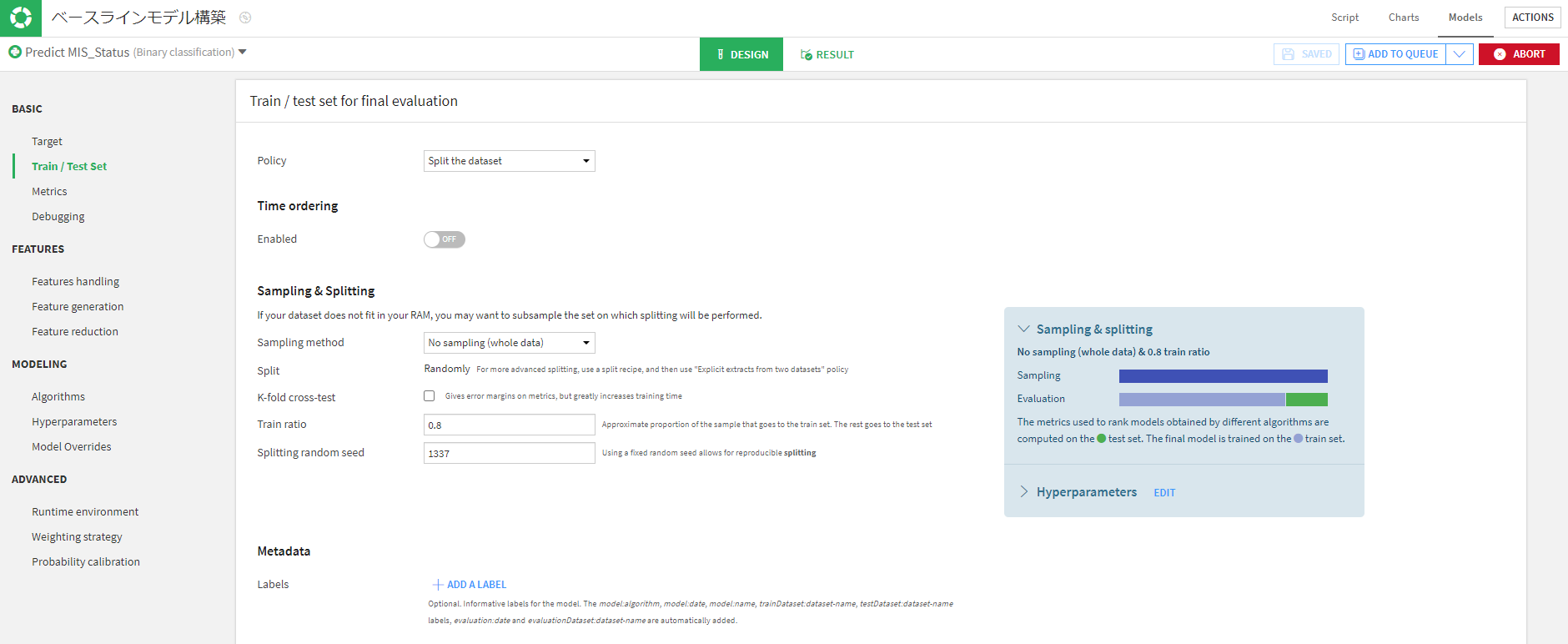
学習データと検証データの設定ですが、今回はベースモデルなのでK-foldは行わずに全部のデータを使って8:2に分割しています。
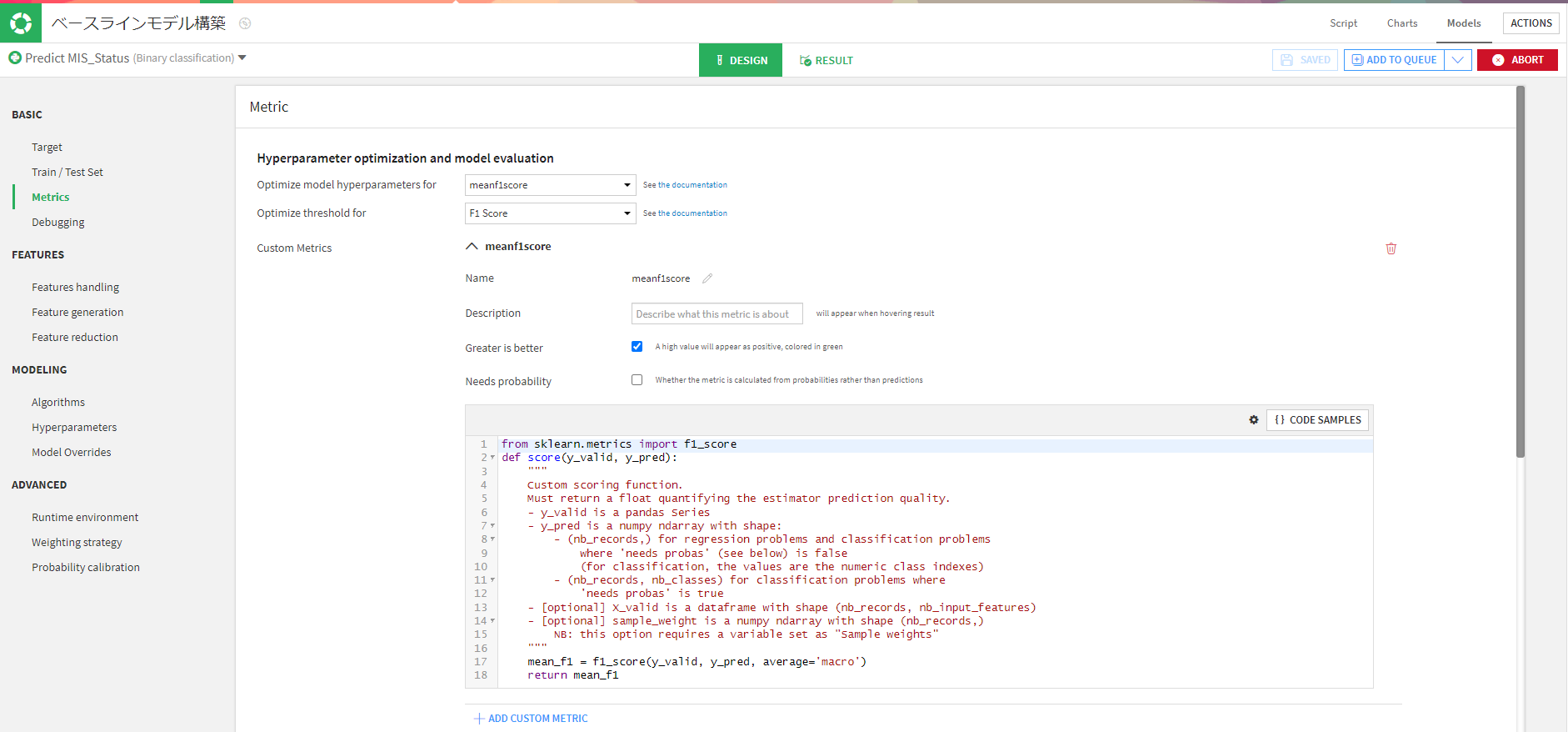
評価指標にはmeanF1scoreをカスタムメトリクスとして追加しました。
パラネーターはmeanf1score,閾値にはF1scoreで調整してくれます。
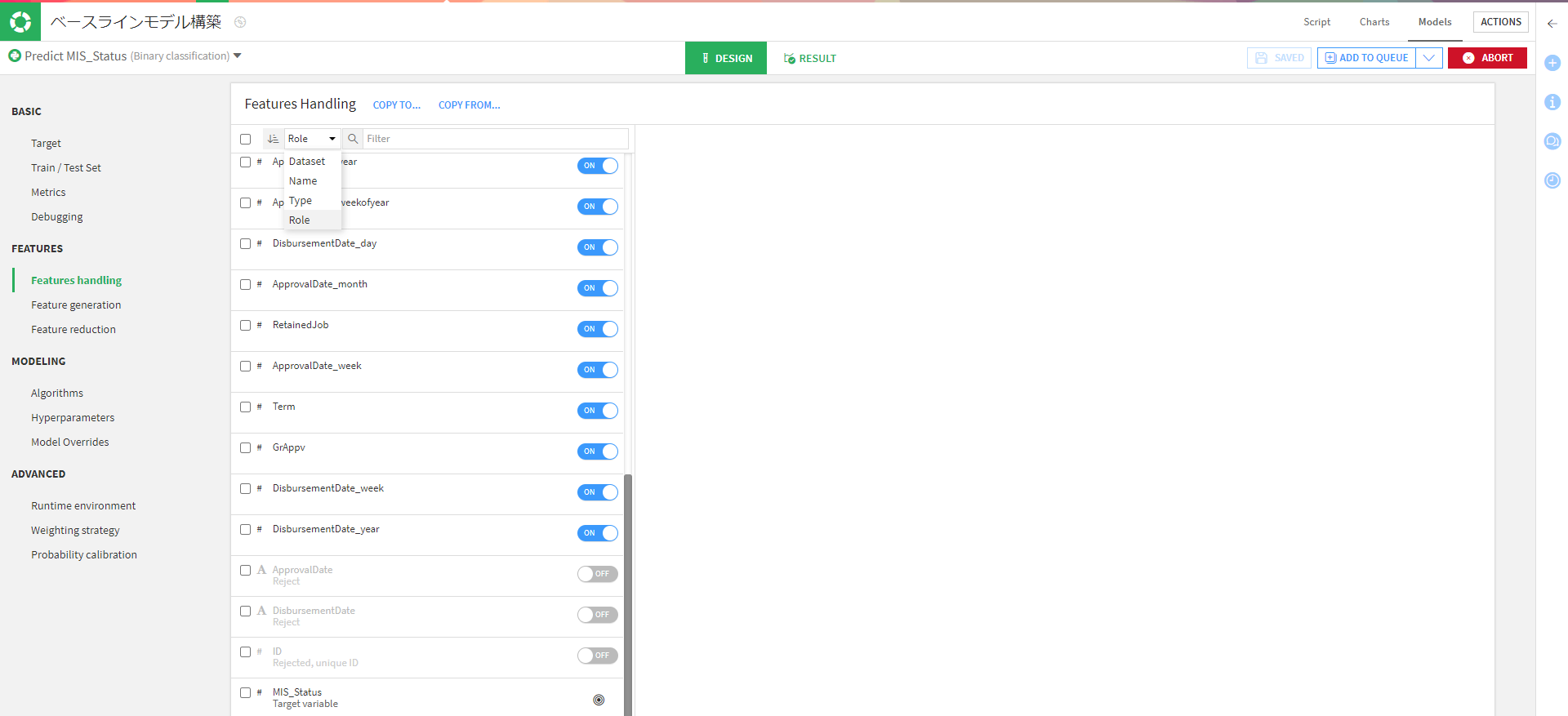
特徴量として以下の3行を除外しました。
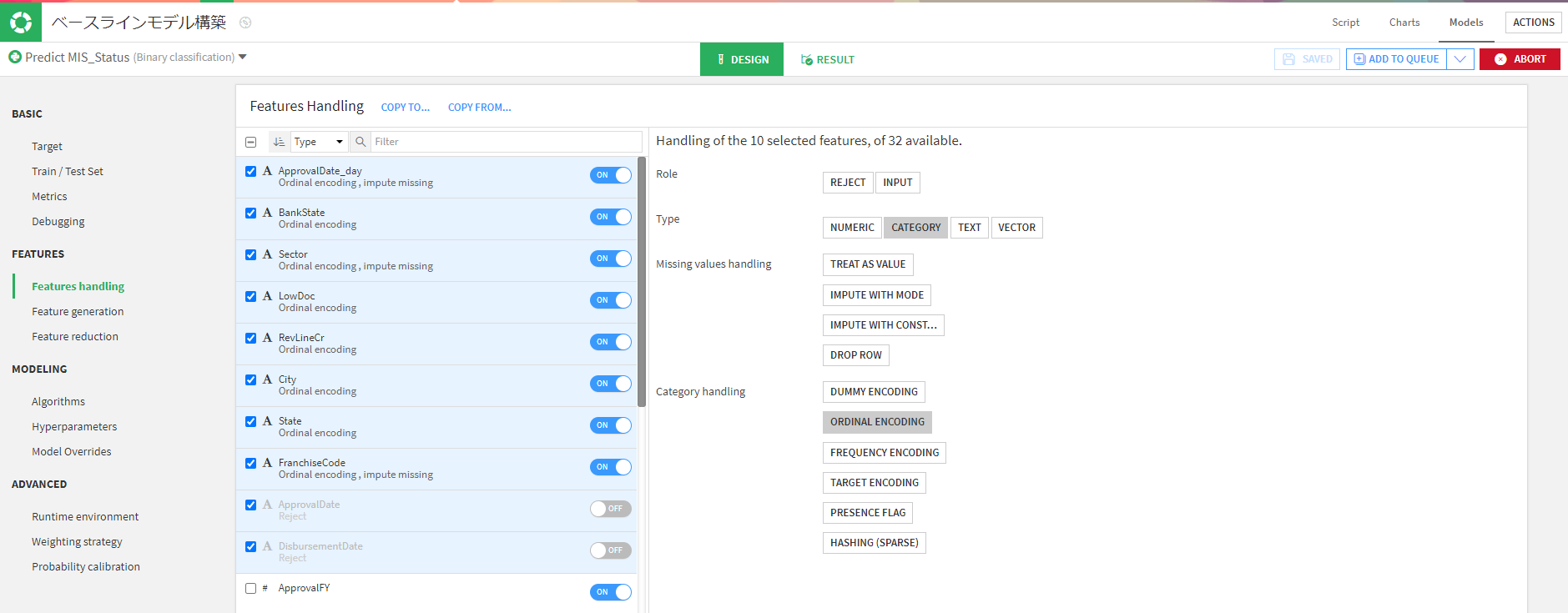
カテゴリ変数は全てオーディナルエンコーディングにします。
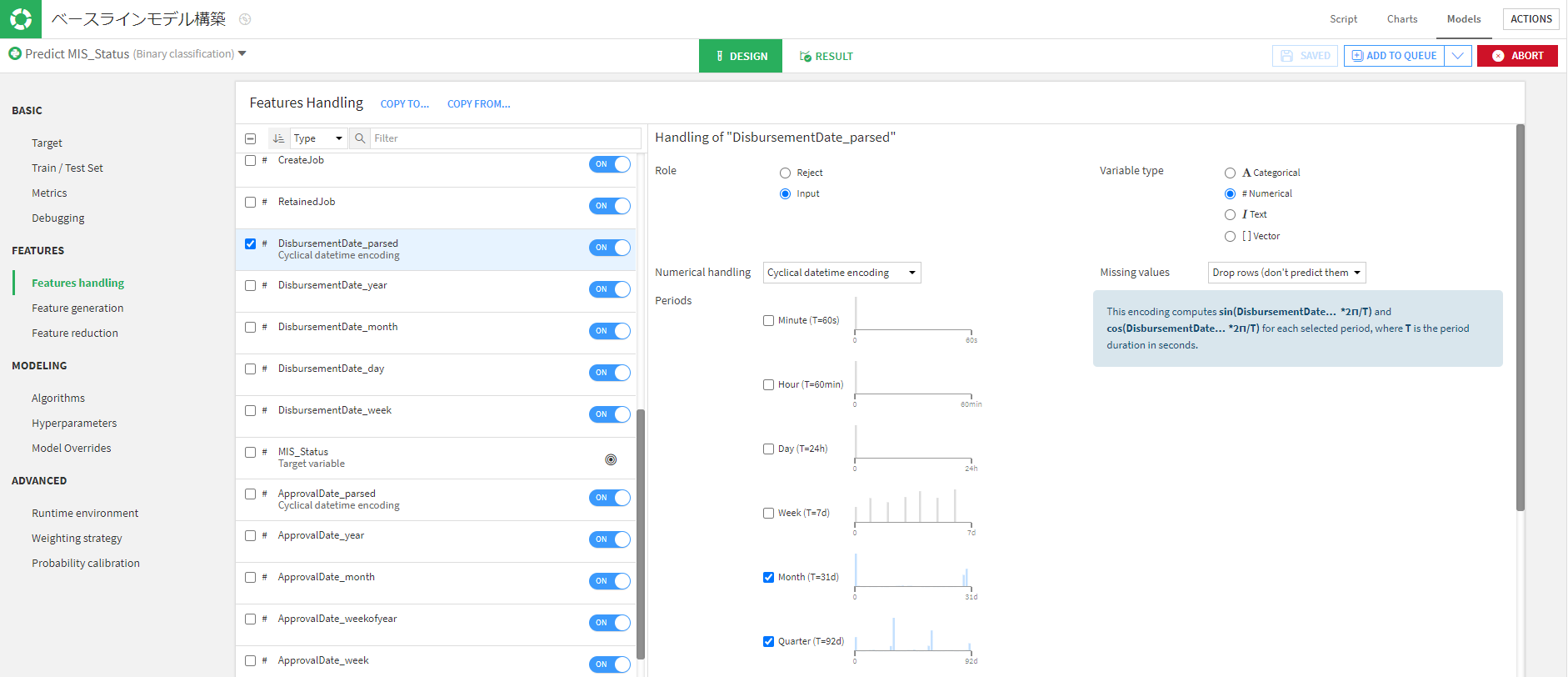
日付データは三角特徴量として扱いました。
アルゴリズムを選択します。
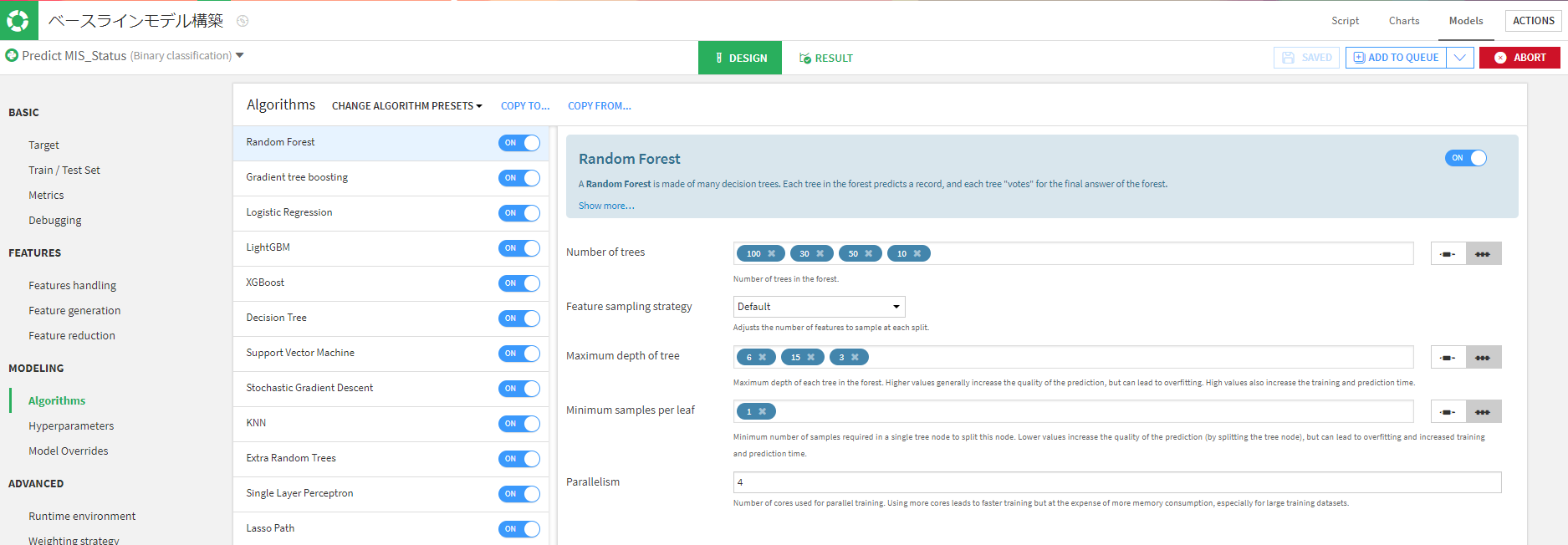
今回は特にパラネーター調整や特徴量の生成、削減などは行わずに作成しました。
以下のアルゴルズムで学習させました。結果はこのようになりました。
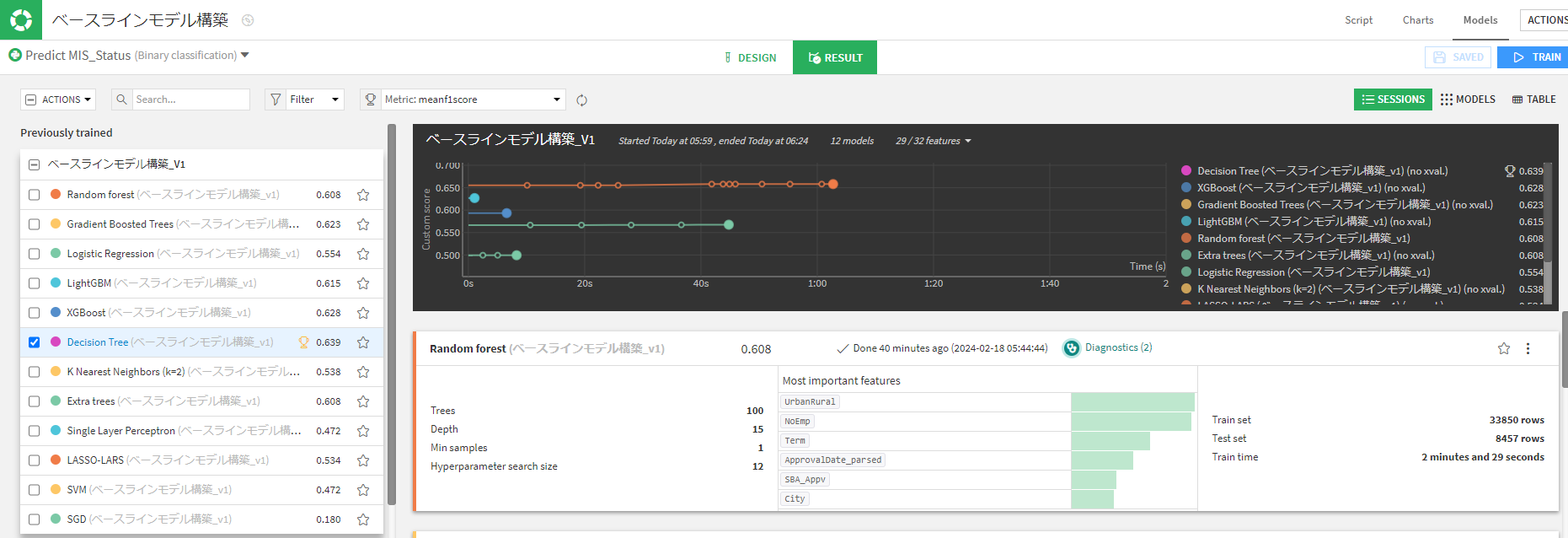
評価指標をROC AUCに変えるとランダムフォレストが最も良いです。
なのでランダムフォレストにベースモデルを適当に決定します。
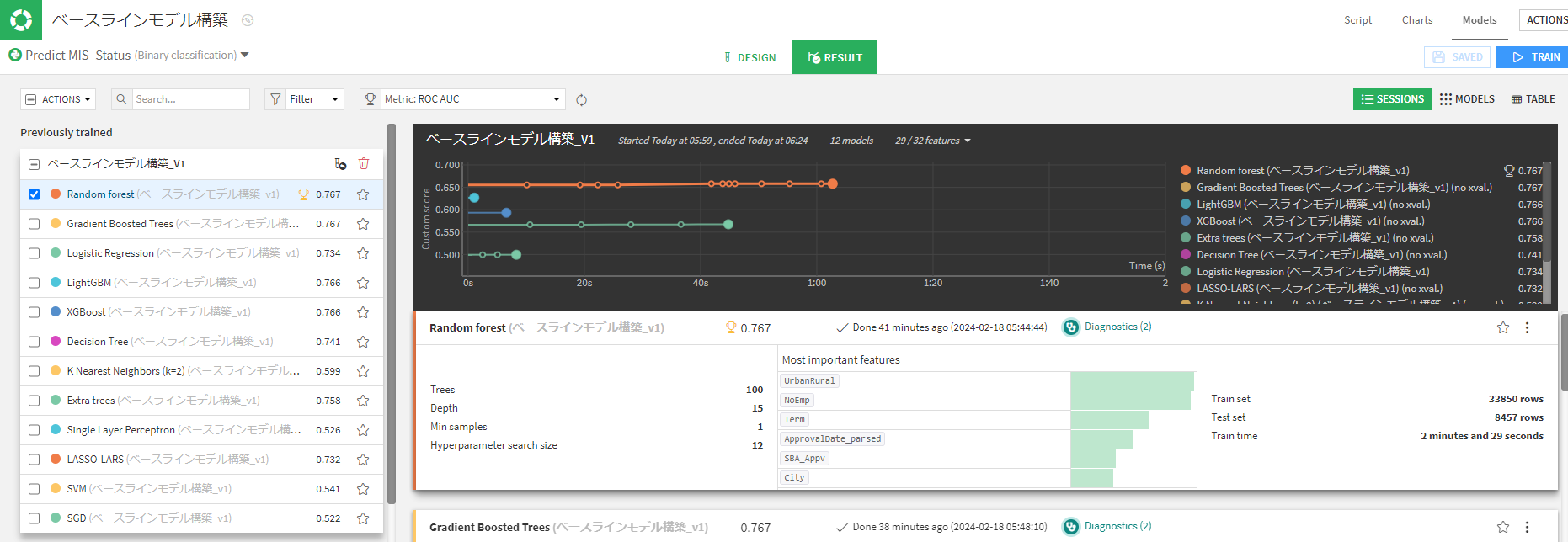
モデルの詳細な結果はこのようになっています。
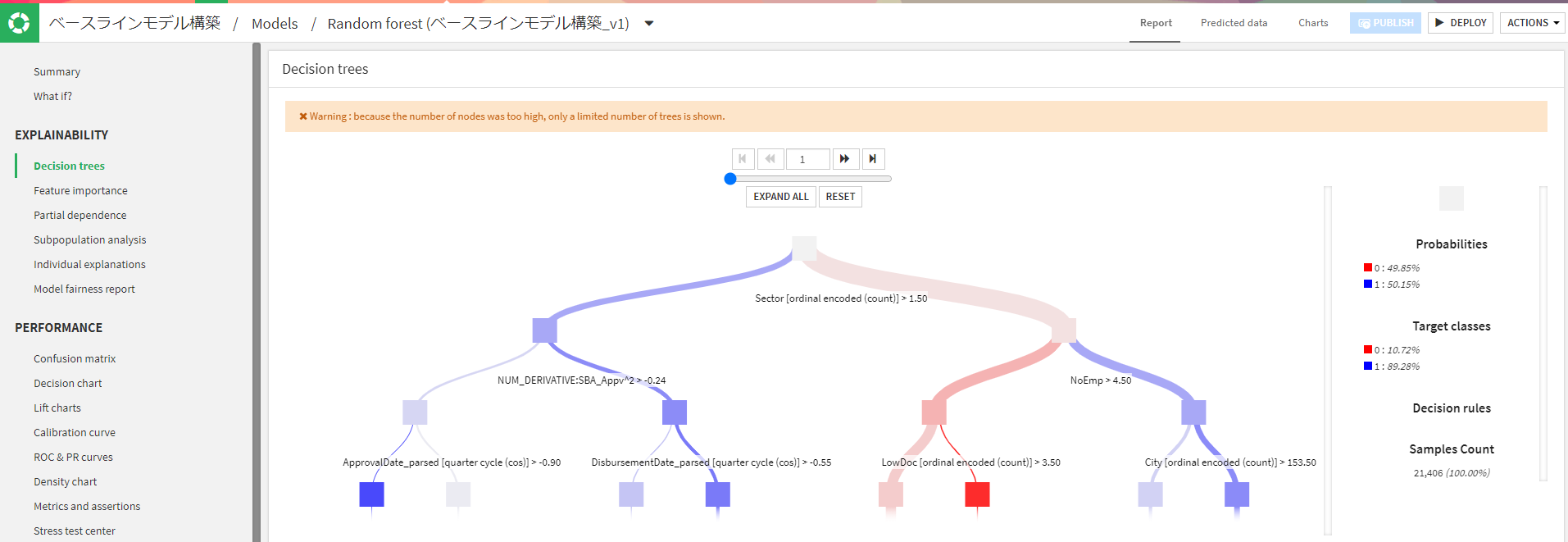
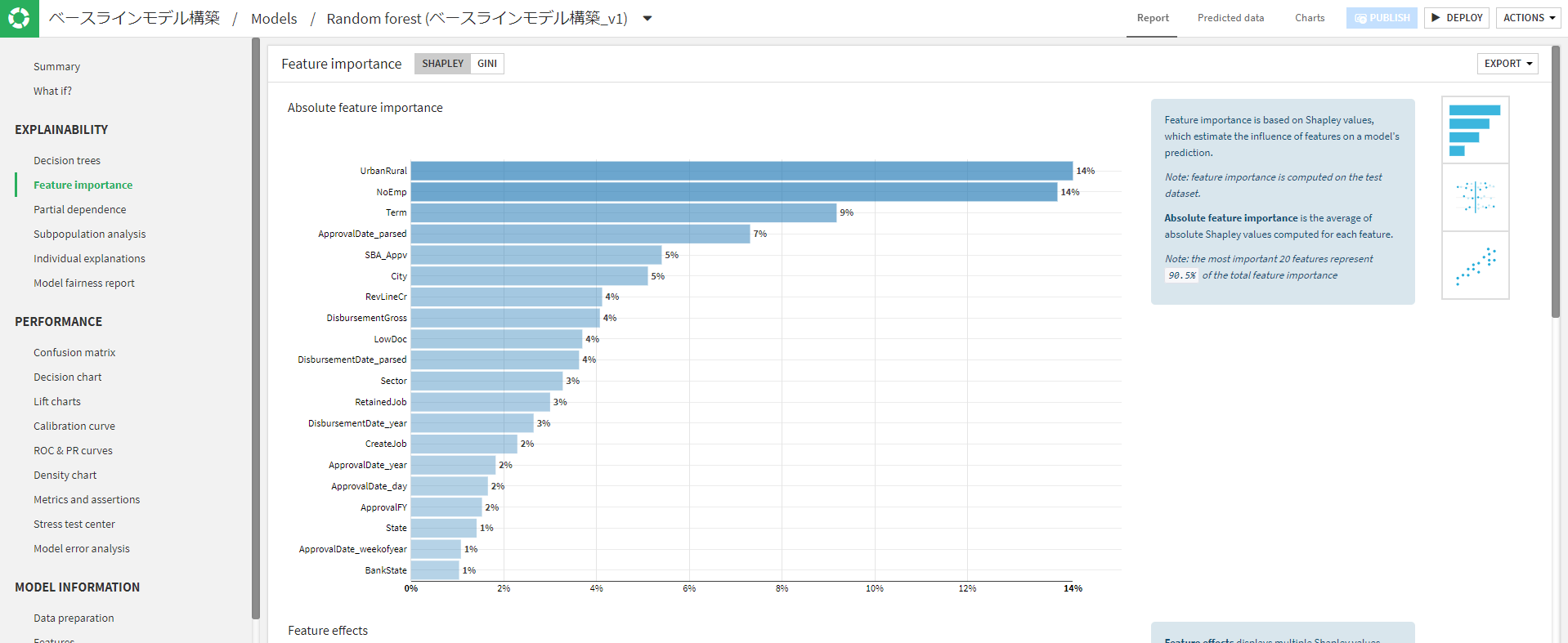
他にもLift図やROC-AUC曲線など細かくモデルの結果を見れます。特徴量の値の閾値の変化によってどの程度精度が変わるかなど細かい分析も可能になっています。今回のコンペでは使用していないですが、ビジネス面でクライアントに説明する時などに使えそうですね。
ではカテゴリ変数をダミーエンコーディングにした場合精度は変わるのでしょうか。検証します。
結果的に精度が上がりました。
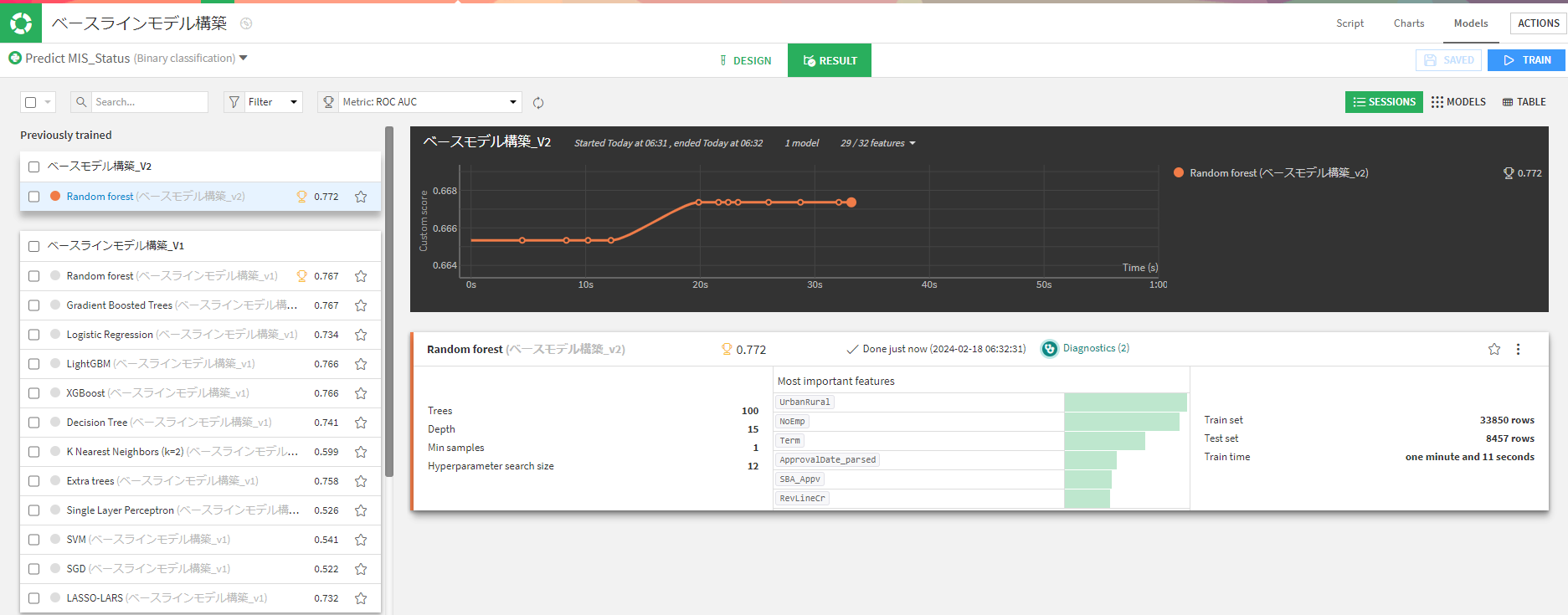
もし前のモデルのデザインに戻りたいときは、「Revert design to this session」でその時定義した設定に戻れます。
では最終的にこのモデルをデプロイします。

それではベースモデルが決まったのでテストデータも同様の前処理を行い、予測させます。
まずは、テストデータの前処理ですが学習データの前処理ステップをコピーし、入力データセットを「test」に変更し、出力データセットの名前を決めるだけです(便利)
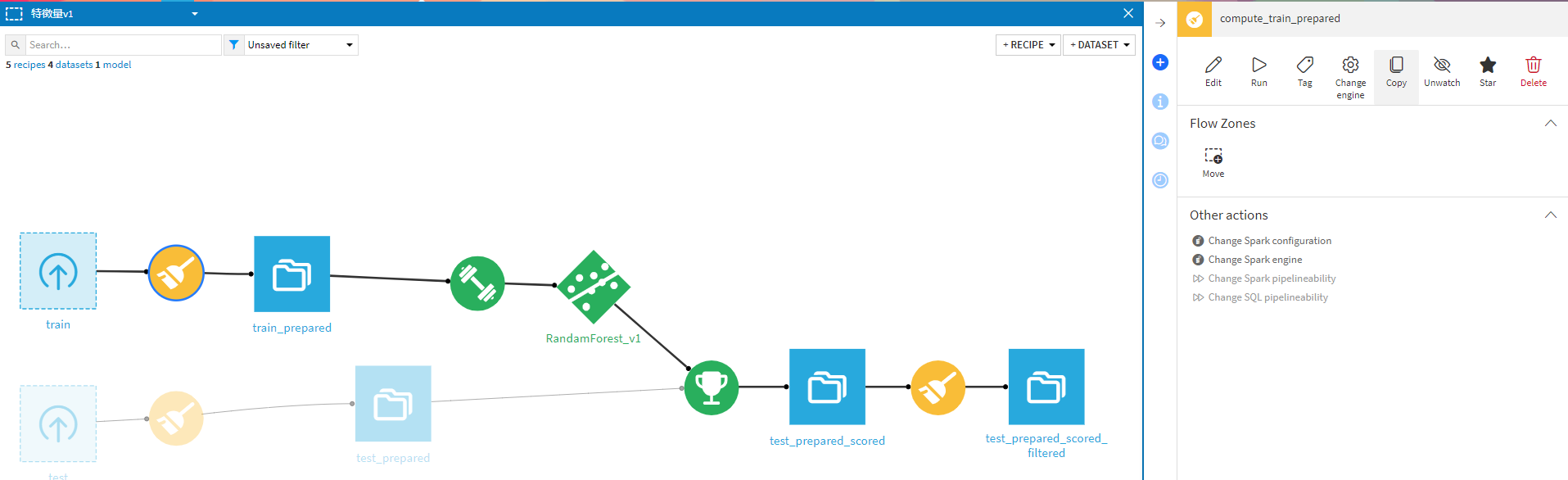
そして「Prediction」からモデルを選択して、予測させます。
予測させるときに、学習時の閾値を使うかなど設定できます。(ここで閾値の変更も可能)そして、出力するデータのカラムの指定もできます。
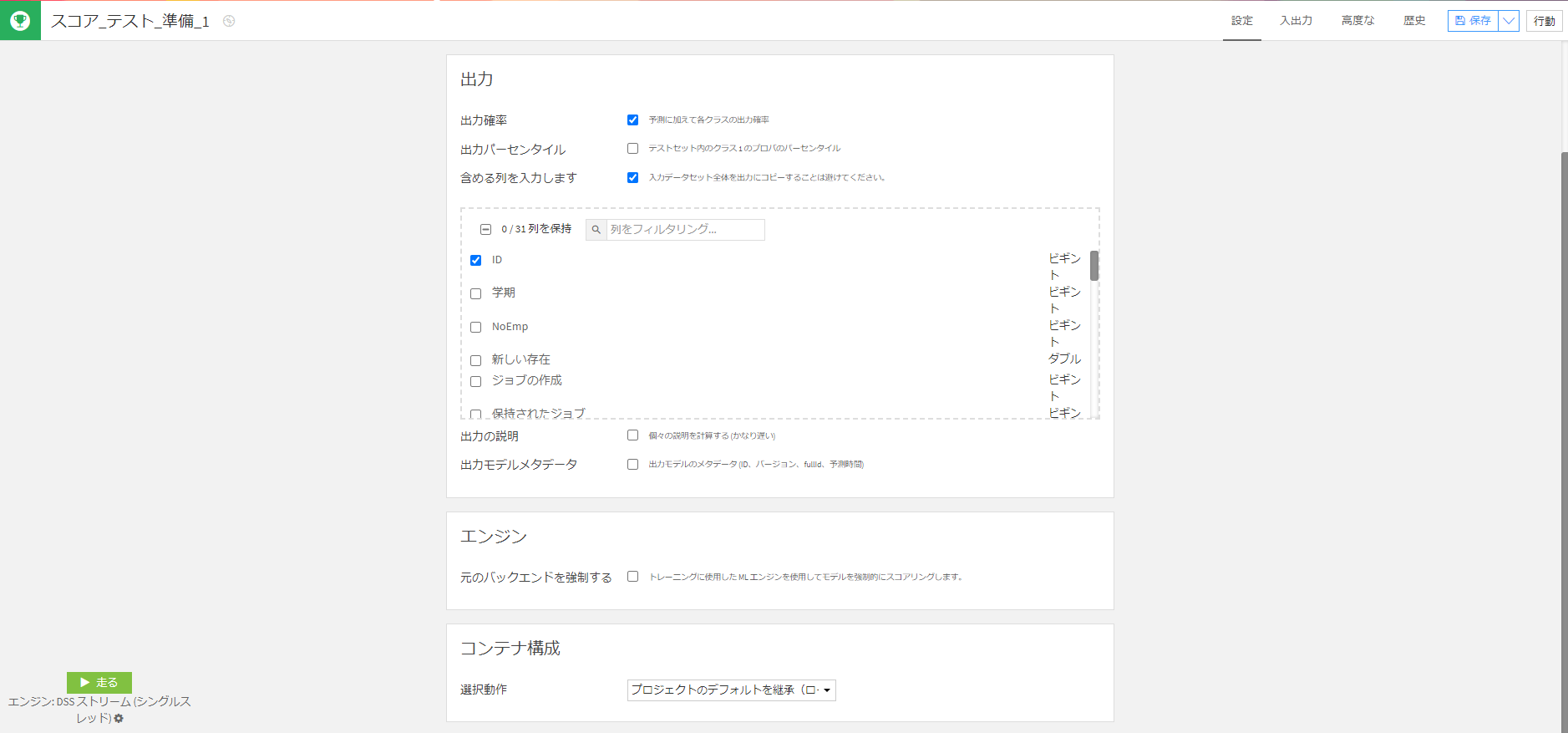
これを実行すれば予測完了です。
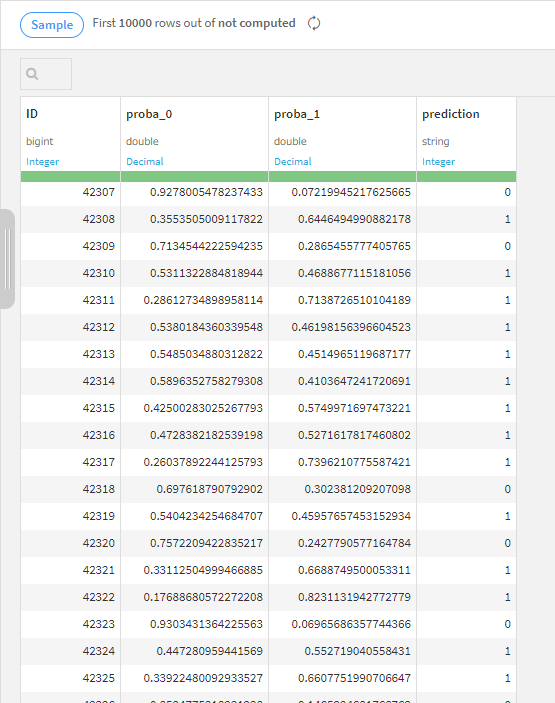
最後に不要な列を削除して提出します。
手順3.複数学習データのパターン作成
ベースモデルができたので、仮説を立てて複数の学習データパターンを作成したいと思います。
ここですべてのパターンを紹介するのは長くなってしまうので、便利な機能だなーと思うところをかいつまんで紹介します。
紹介①フランチャイズコードのカテゴリ変数処理
「Analyze」を選択します。
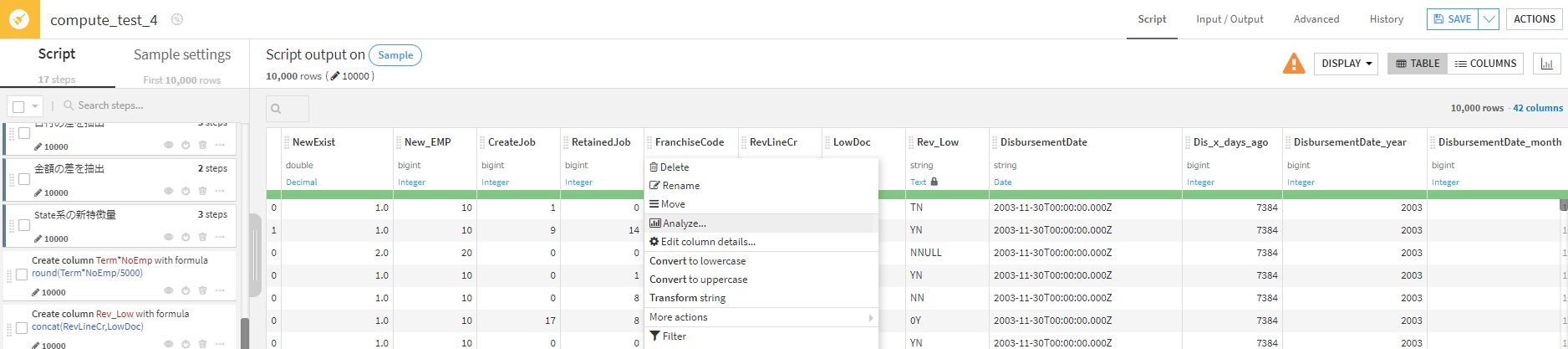
そうすると、フランチャイズコードはこのような構成割合になっており0以外はほぼ少ないことが分かります。なので0かそれ以外という意味ですべて1にまとめたいと思います。
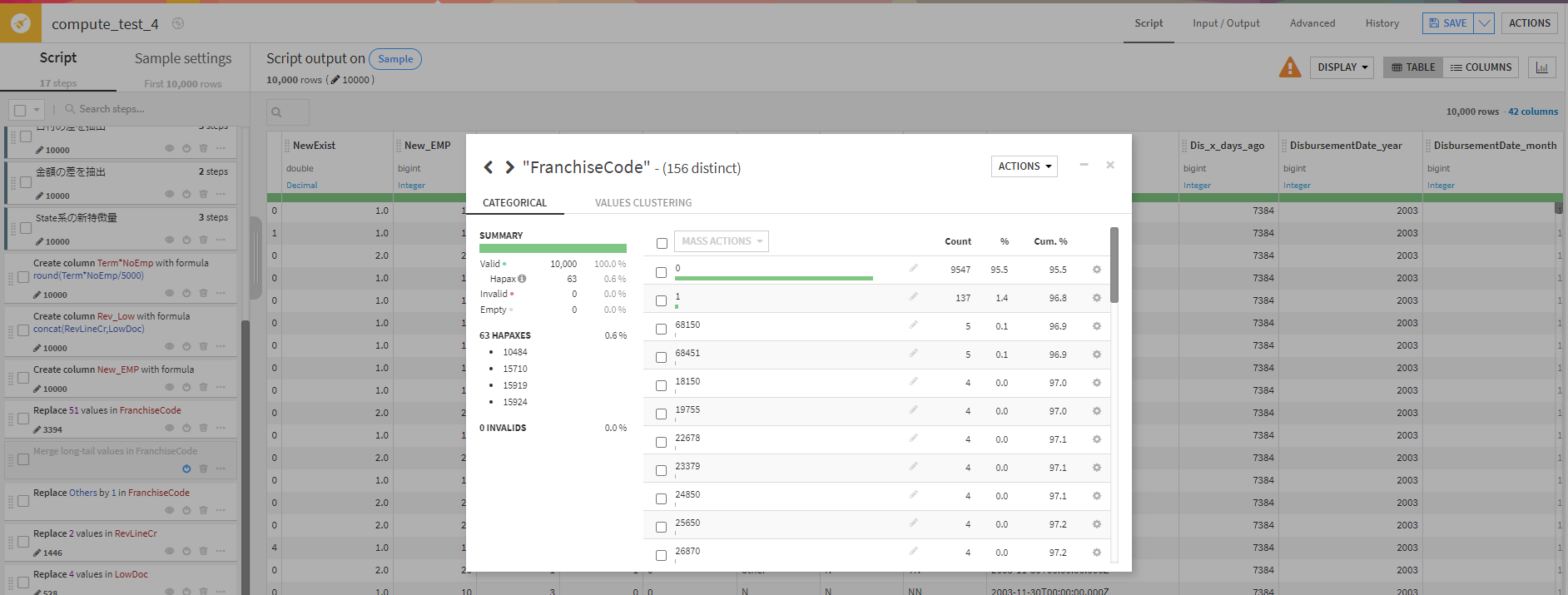
そこで、0を選択し「MASS ACTIONS」から「Merge all others」でそれ以外をすべて結合します。
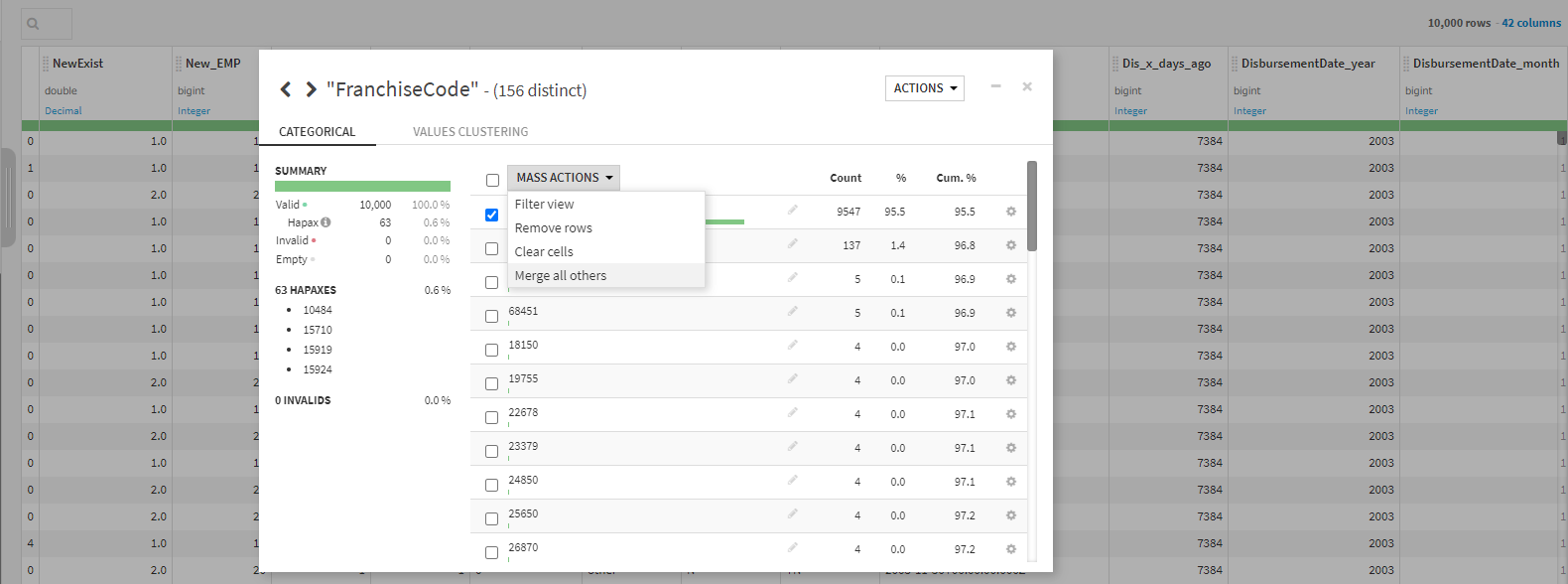
完了です。これはとても便利ですね!
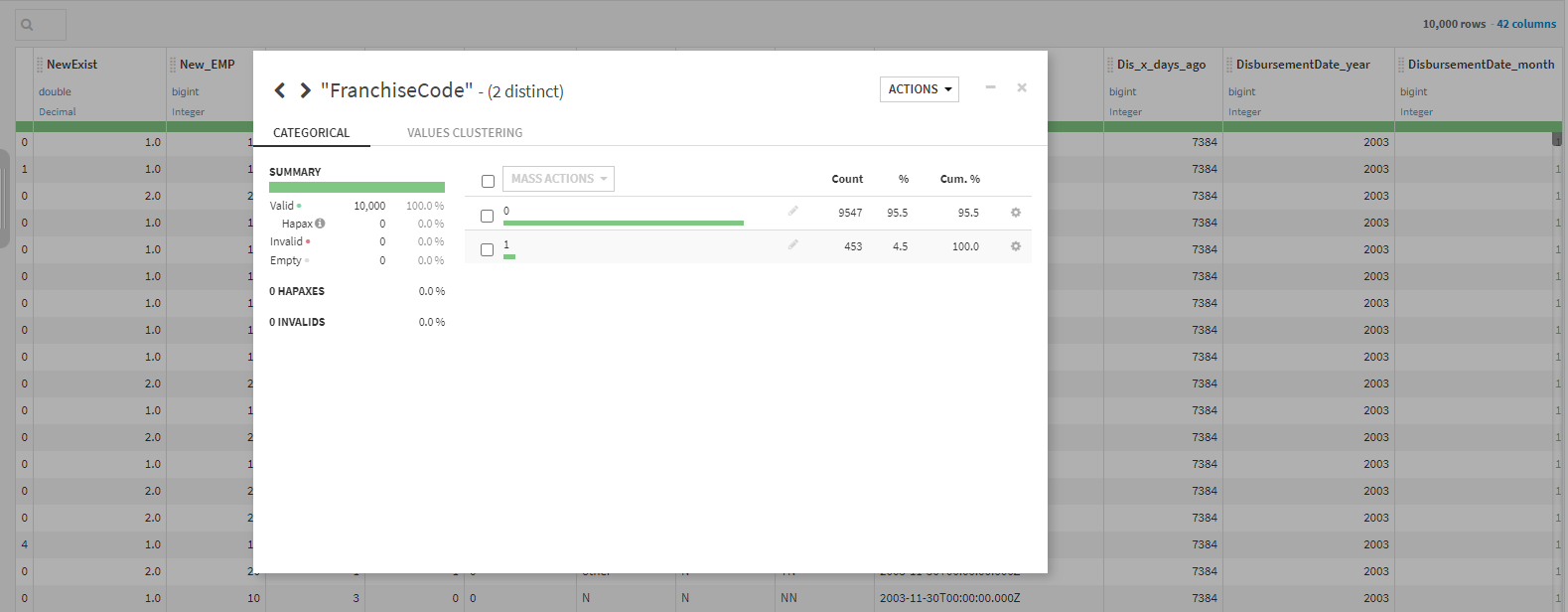
他にもこのようにカテゴリ変数の値を選択してどこをマージするかなど決定できます。
紹介②Excel感覚でformuraによる特徴量作成
紹介③同時にグラフに出力しながら特徴量作成の考察ができる
時にささっとグラフに出してどう加工したいか考えたいときに、Chartタブを使います。
保存したいときはダッシュボードに保存できます。
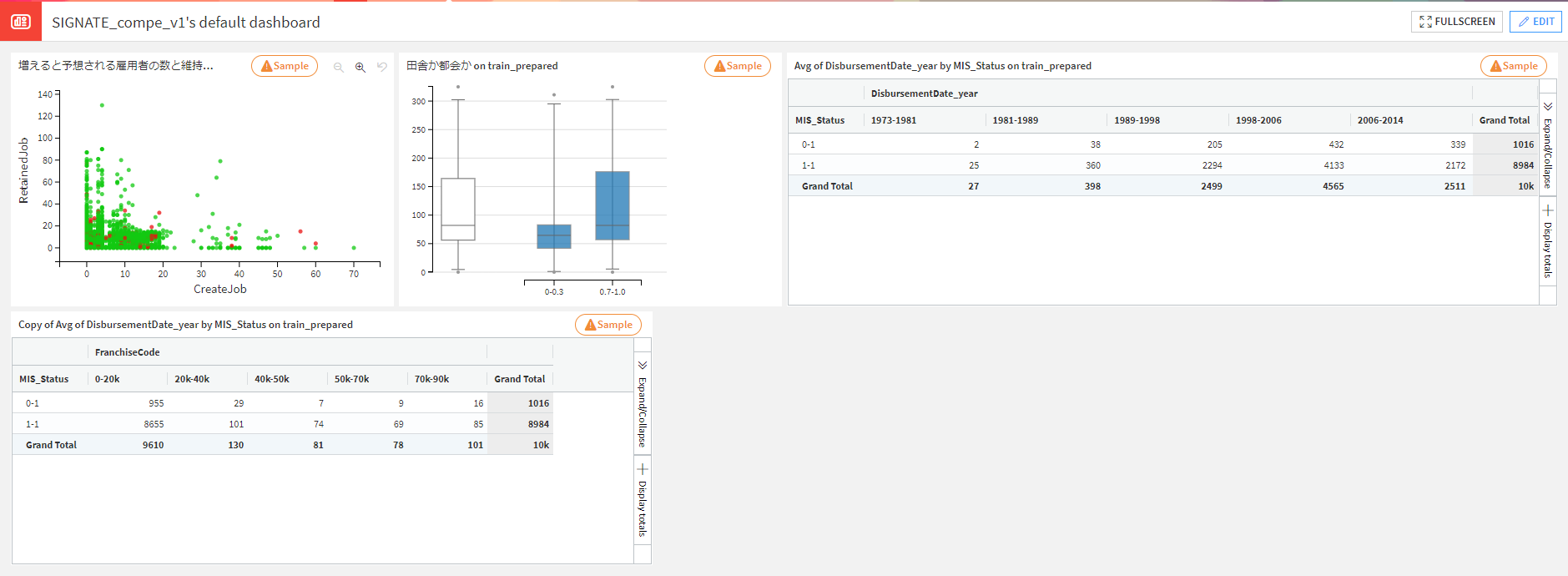
紹介④同時に統計解析しながら特徴量作成の考察ができる
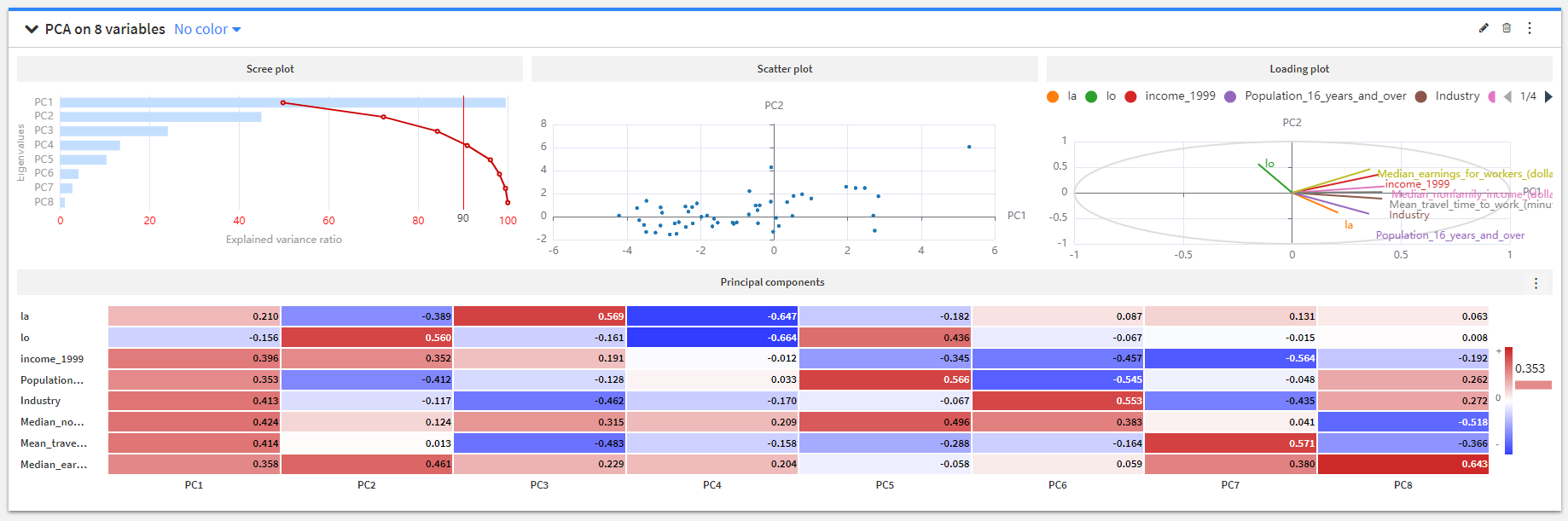
多重共線性など気になったときなどに統計解析が気軽にできます。実際にPCAや相関係数行列の表示で特徴量削減などを手動で少し行ったものもあります。
例:PCA
例:相関係数行列

行った検定一覧はこのようにしてまとめられます。
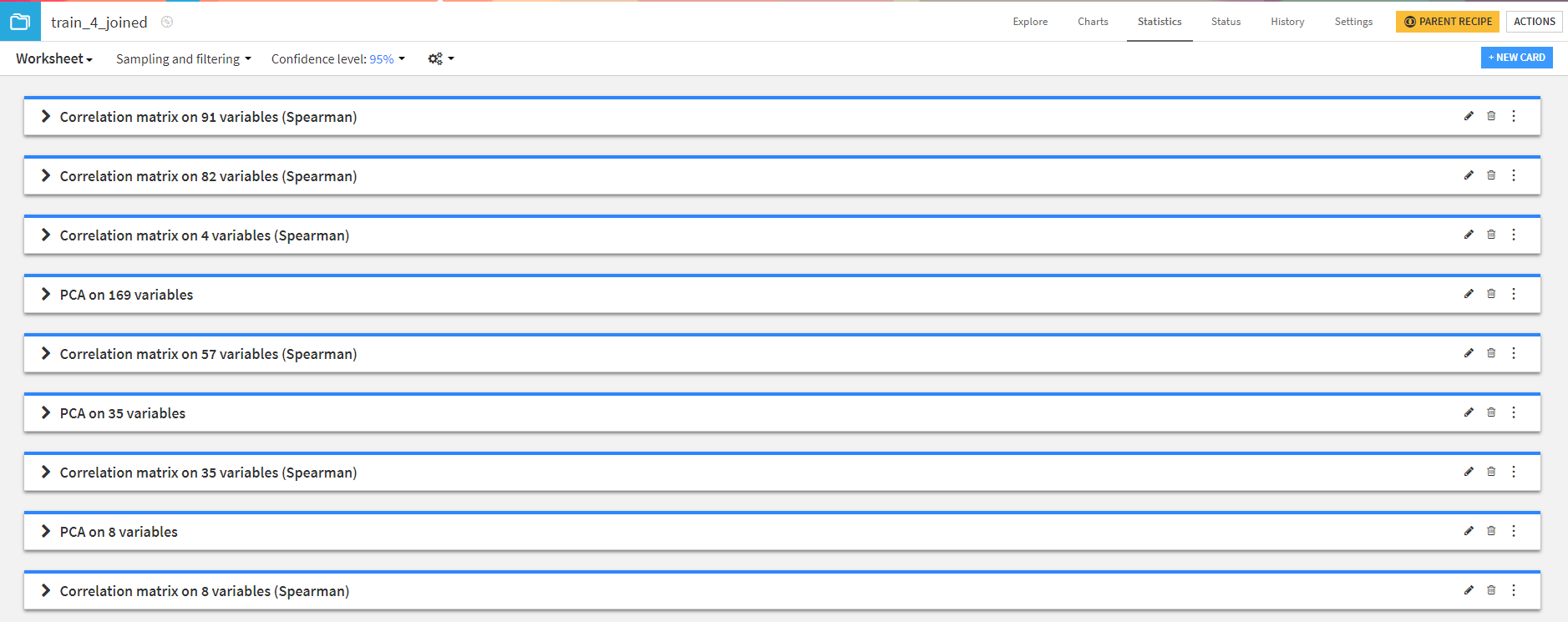
手順4.手順3で作成した複数学習データごとに機械学習モデル構築
ここでは細かい調整を行って機械学習モデル構築を行いました。
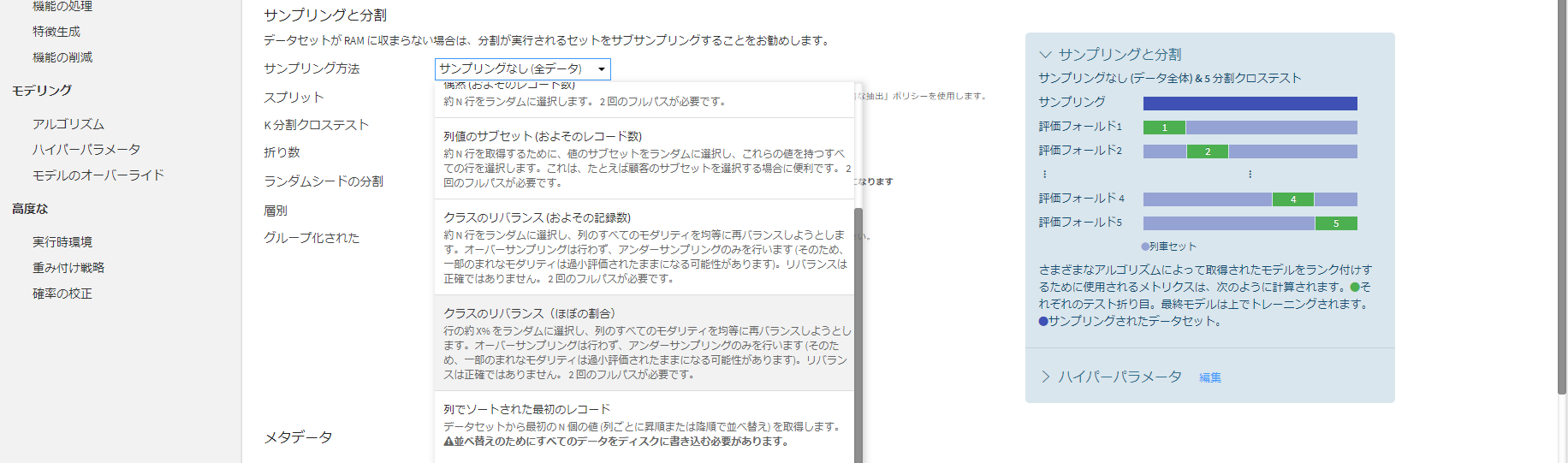
やったこと①-Kfolds
まず、5foldsにし、それぞれのfoldに目的変数の分布が偏らないように設定します。
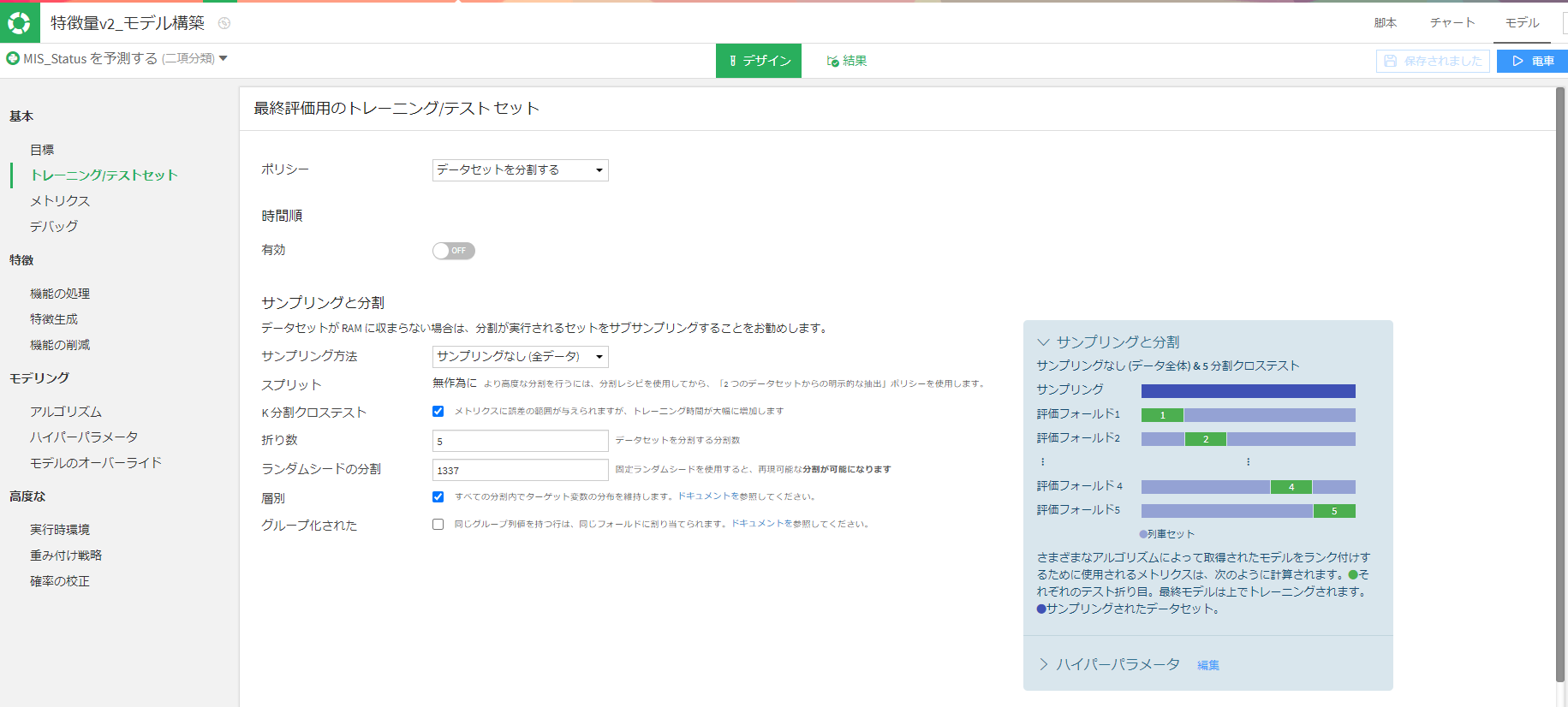
やったこと②-アンサーサンプリング
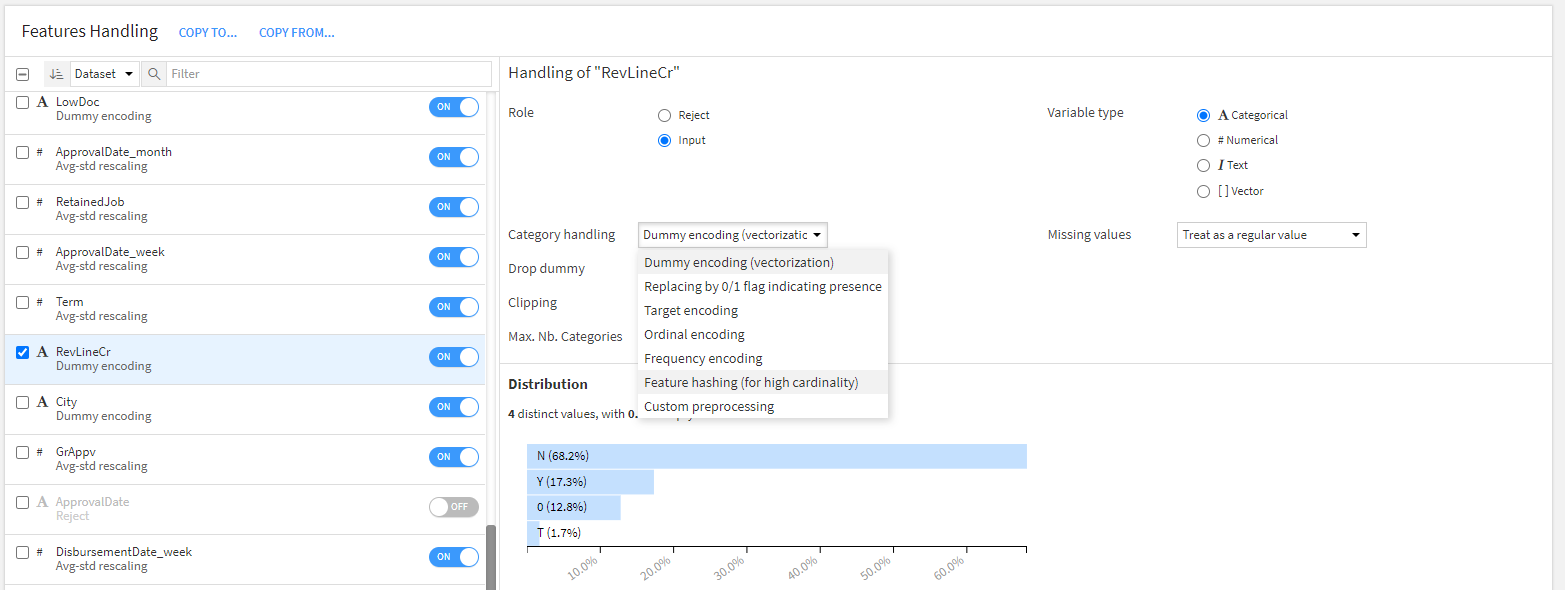
やったこと③-様々なカテゴリ変数処理の仕方で実験
Dataikuではカテゴリ変数ごとに以下の変換が可能です。ターゲットエンコーディングなども試してみたりしました。
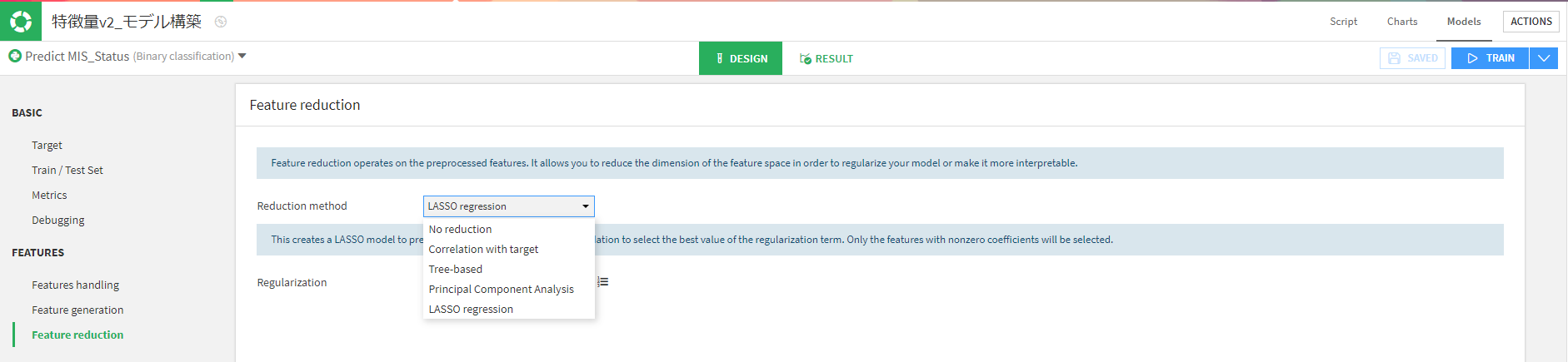
やったこと④-特徴量作成&削減
作成する特徴量の種類を決定します。

特徴量削減では以下の選択があります。好きなものを決定し、最終的に何列残すかなどを決めます。
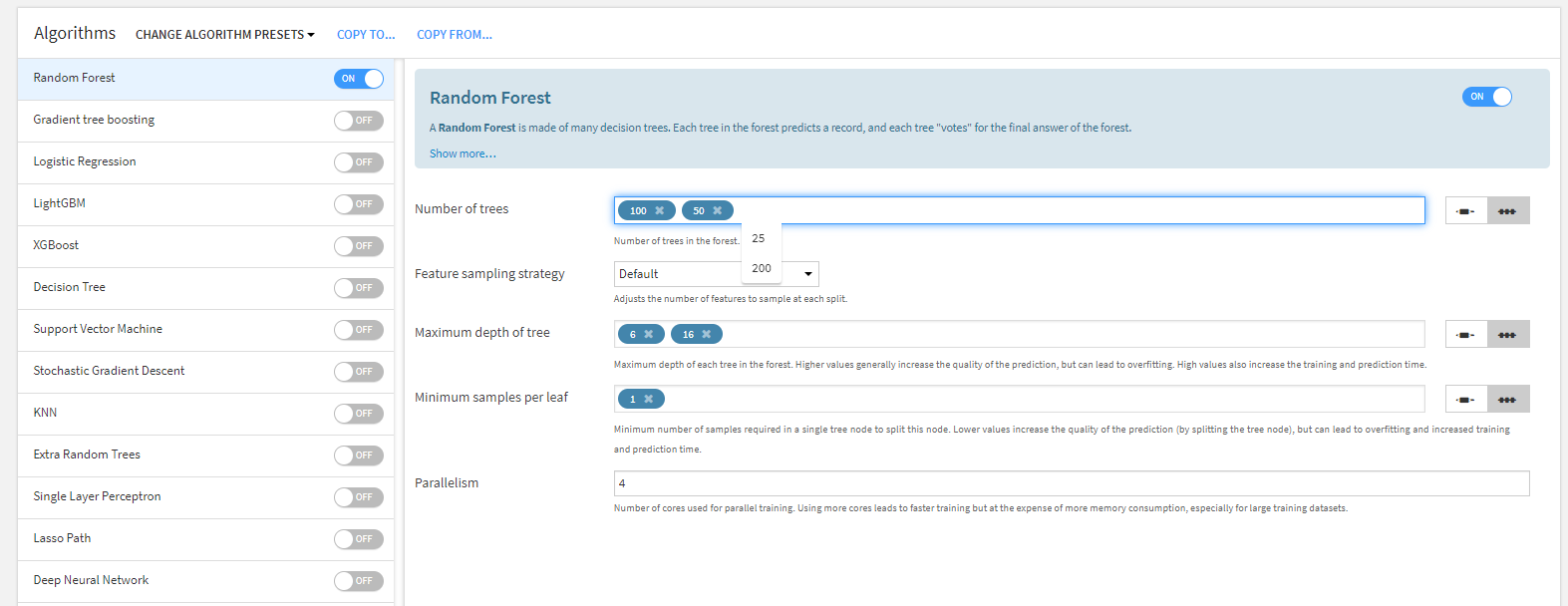
やったこと⑤-パラネーター調整
方法はグリッドサーチで好きなパラネーター範囲を決定して、学習させます。
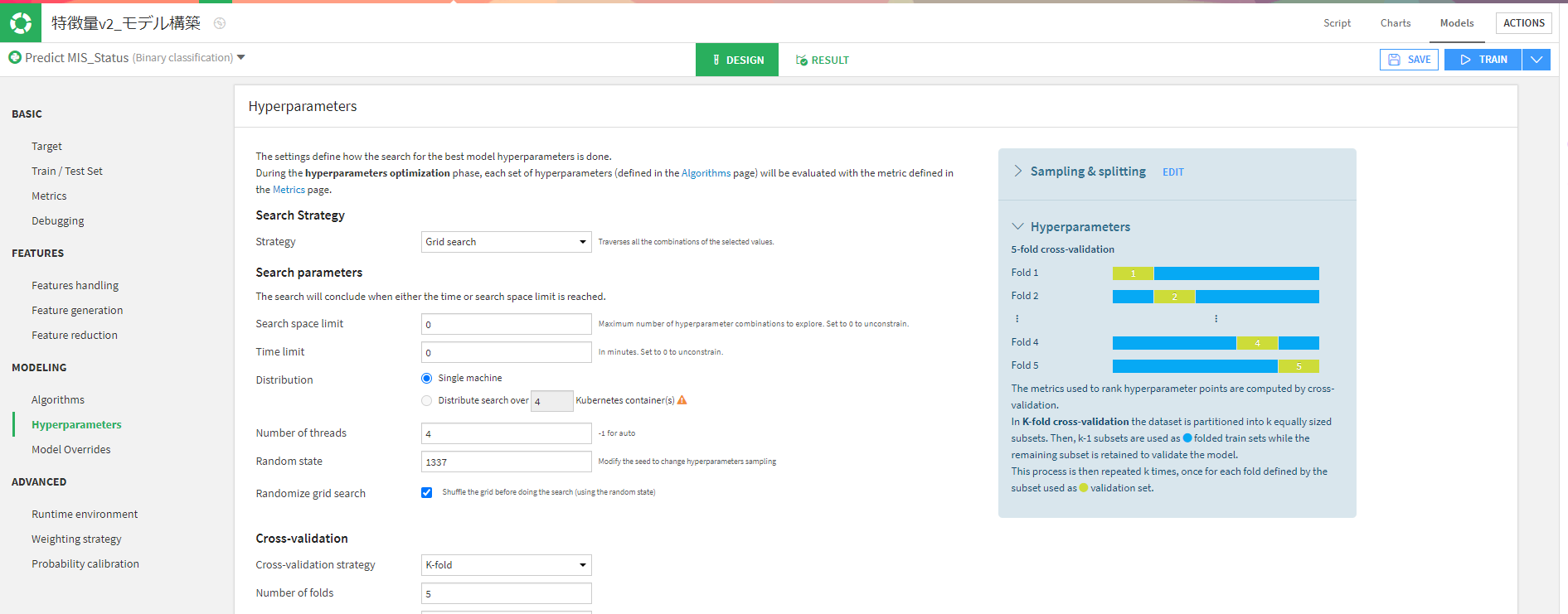
やったこと⑥-アンサンブル
作成したモデルでアンサンブルを行いました。
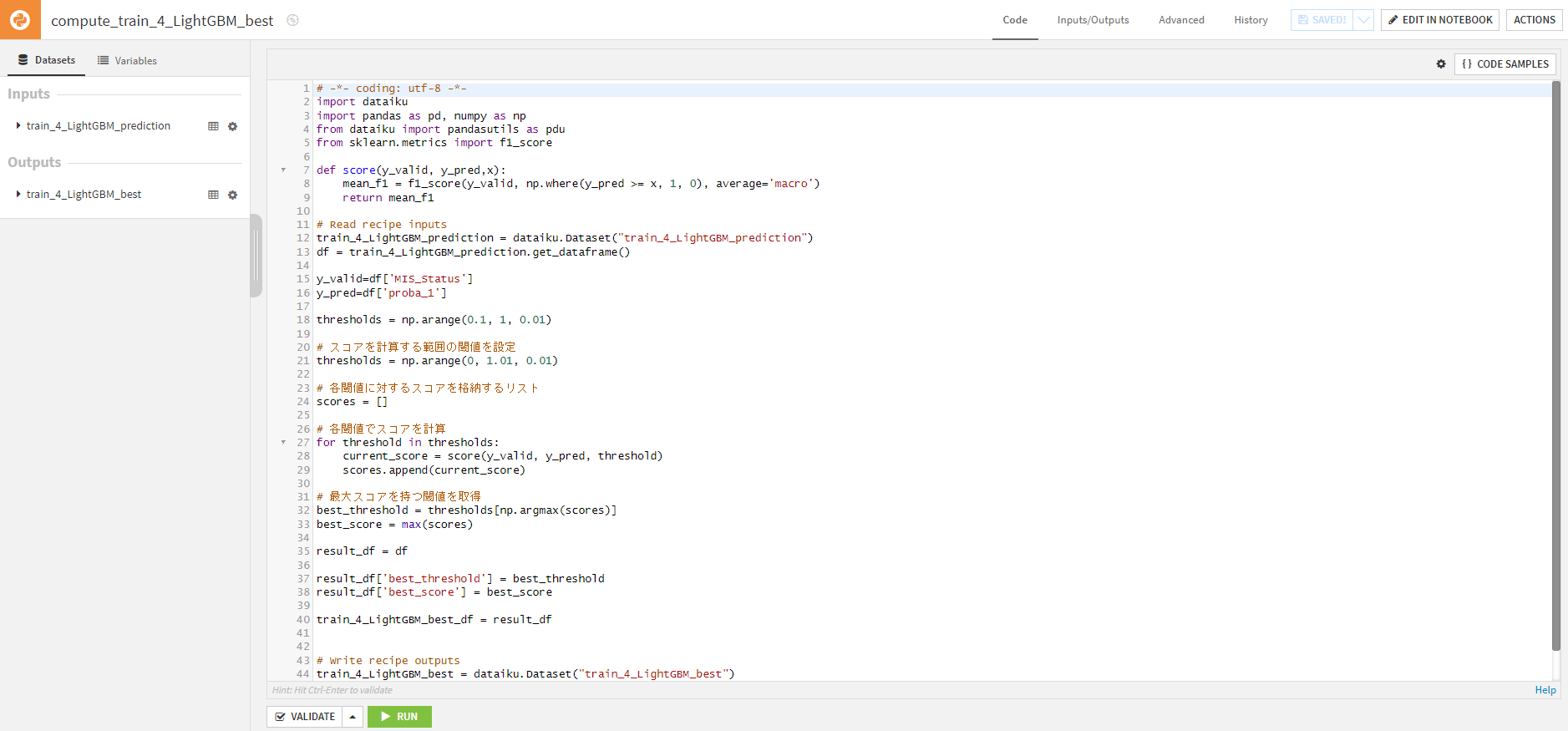
手順6.最適な閾値設定を行う
最終的に提出するモデルを決定したら、閾値設定を行いました。
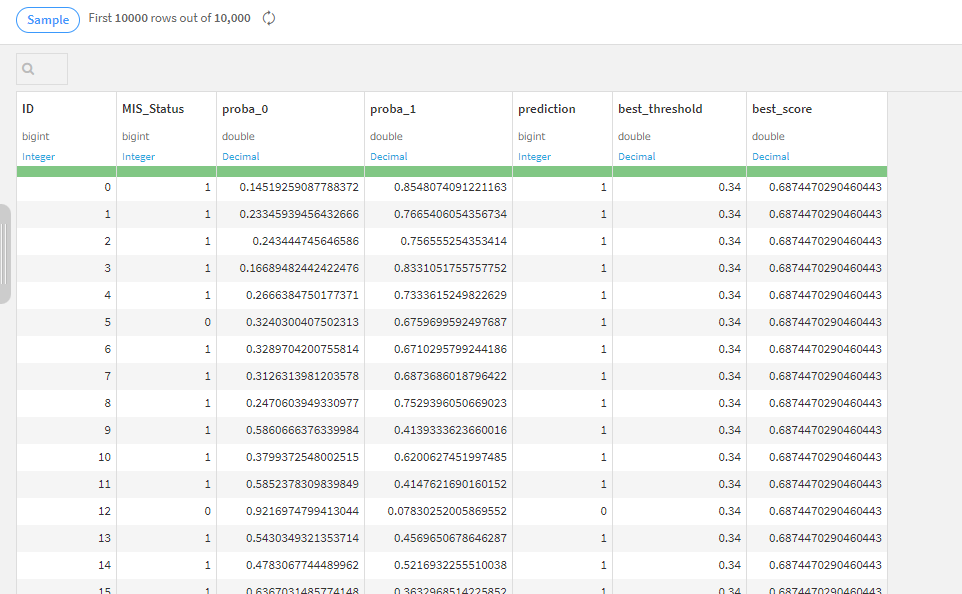
mean1scoreが最も高くなる閾値を探すコードを書きました。
そうすることでベストな閾値が分かります。
その他使用した機能やTIPS
手順には載せていませんが他の機能も試していました。
機能①-プラグイン
プラグインではUSの州の名前から緯度経度に変換してくれるものがありました。
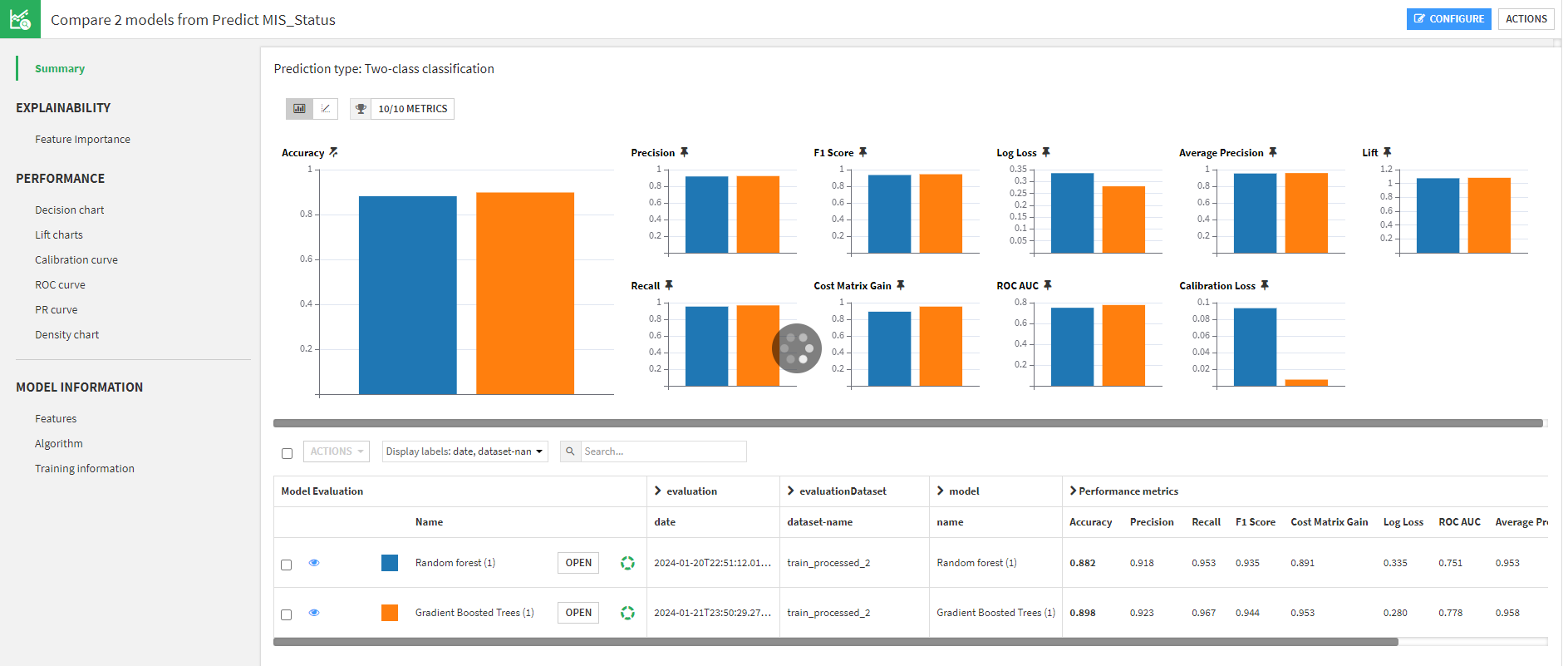
機能②-モデル比較
モデル比較のレポートもまとめてくれます。
機能②-ToDo
プロジェクトのホーム画面にToDoがあります。
機能③-プレビュー
データをすぐプレビューできます。
TIPS①-過去に実験したラボは整理する(名前を綺麗につける)
適当にlabを大量生産していると、煩雑になるので私は特徴量パターンごとにlabを作るのが一番気に入っています。
TIPS②-フローはZONEに分けて整理
ZONEというフローを分けてまとめることができるので、絶対使った方がいいです
まとめ
今回私は無料デスクトップ版を使用してこれらの機能を使えたので是非使いたい人はダウンロードしてみて下さい!また、もし分からないことなどありましたら以下のサイトを参考にすると便利です。










