
Snowflakeの会話型AI分析ツール「Cortex Analyst」を実際に試し、導入手順や精度、課題までを徹底検証。ノーコード実装との比較も掲載。
Cortex Analystとは
Cortex Analyst は、Snowflake上で動作する 会話型AIによるセルフサービス分析機能 です。ユーザーが自然言語で質問すると、AIがSQLを生成・実行し、回答やダッシュボードに表示可能なデータを返します。REST API経由で外部アプリからも利用できます.
主な特徴
-
自然言語で質問 → AIが自動的にSQLを構築・実行
-
複数LLM(Meta Llama、Mistral、Azure OpenAIなど)を組み合わせて使用
→ 精度とパフォーマンスを最適化
-
Semantic Model(YAML形式) を使って、ビジネス文脈を補完し正確なSQLの生成を支援
-
REST API提供 → チャットUIやBIツール、ポータルへの連携が容易
-
会話履歴に基づく対話継続に対応(マルチターン質問)
-
Snowflakeのアクセス制御やガバナンスに準拠 → セキュリティも万全
Cortex Analyst実装手順(SQL & Pythonを用いた ver)
https://github.com/Snowflake-Labs/sfguide-getting-started-with-cortex-analyst/tree/main
0. 前提条件 Snowflake アカウントSnowflakeのアカウントにログインできる必要があります。
SnowflakeのGUIで権限を付与する方法
さらに、以下の操作ができるロール(役割)を持っている必要があります:
- データベースの作成
- スキーマの作成
- テーブルの作成
- ステージの作成
- ユーザー定義関数(UDF)の作成
- ストアドプロシージャの作成
もしこのようなロールがなければ、Snowflake の無料トライアルアカウントを作成するか、必要な権限を持つ別のロールを使う必要があります。
1. Snowflake オブジェクトの作成 実行スクリプト 変更箇所
-- 元の記述
USE ROLE SECURITYADMIN;
-- 以下に変更
USE ROLE ACCOUNTADMIN;
ユーザー名 <your_username> を適切に変更する。
ユーザー名の確認コマンド:
SELECT CURRENT_USER();
2. 使用するファイル(GitHub リポジトリに含まれる)
daily_revenue.csvregion.csvproduct.csvrevenue_timeseries.yaml
daily_revenue.csvregion.csvproduct.csvrevenue_timeseries.yaml
ファイルをSnowflakeにアップロードする手順
- Snowsight にログインし、上部メニューから「Data」タブを選択
- 「Add Data」をクリック
- 「Load files into a stage」を選択
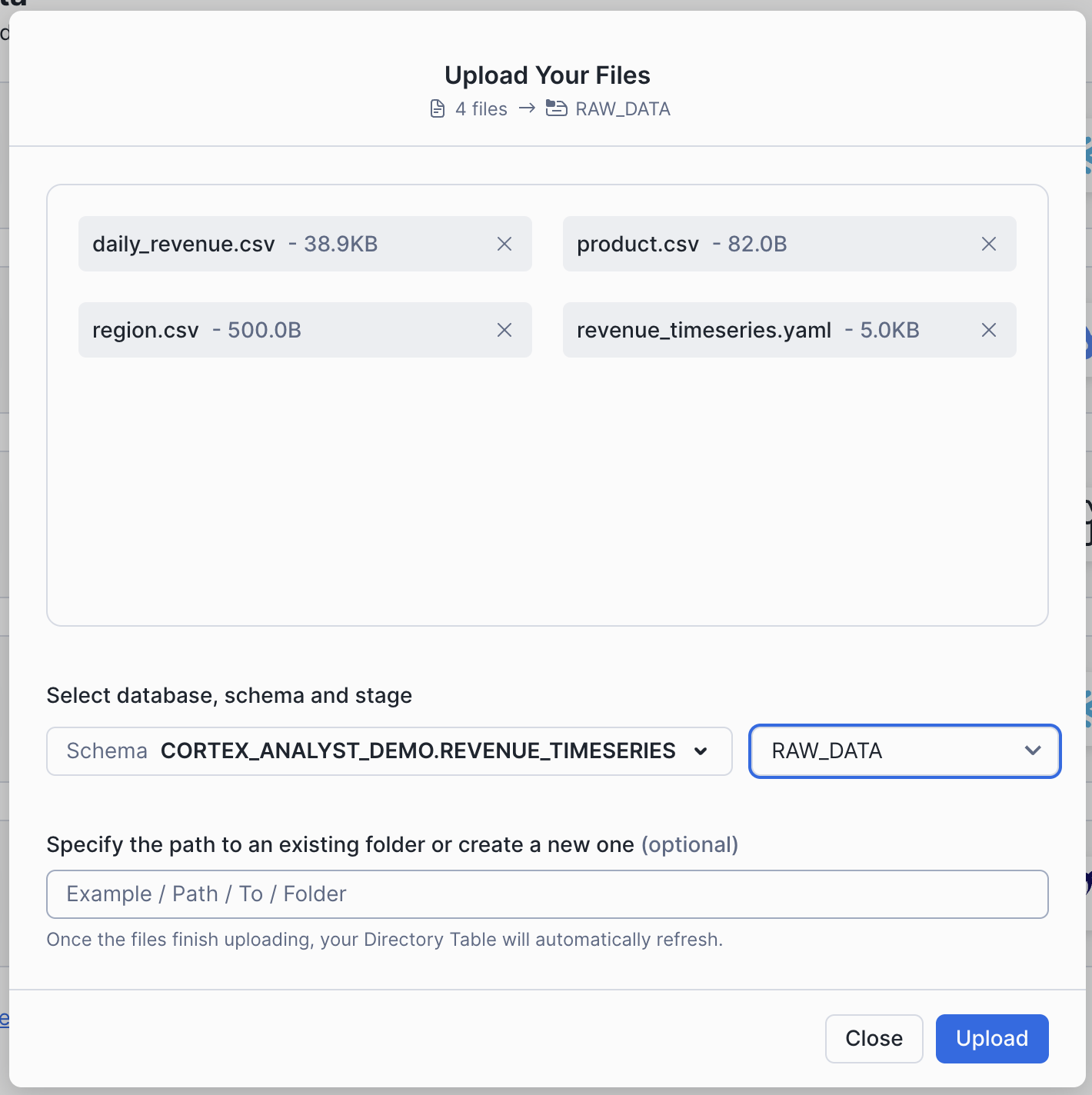
- 上記の4ファイルを選んでアップロード対象にする
- アップロード先を指定:
- Database:
CORTEX_ANALYST_DEMO - Schema:
REVENUE_TIMESERIES - Stage:
RAW_DATA
- Database:
- 「Upload」をクリック
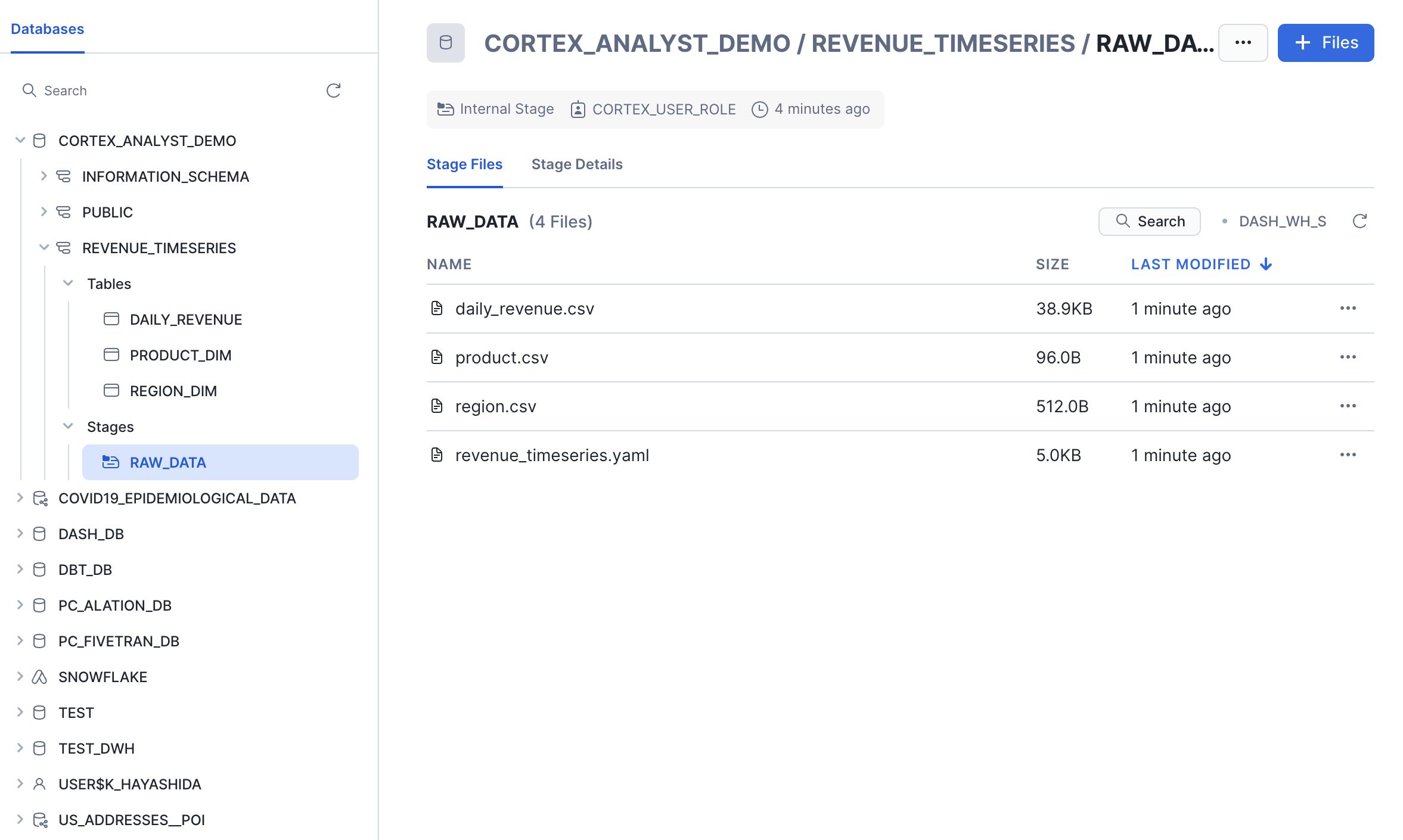
- 「Data > Databases」へ移動
CORTEX_ANALYST_DEMOデータベース →REVENUE_TIMESERIESスキーマを選択- 左の「Stages」から
RAW_DATAを選択 - 「Enable Directory Table」が表示されたら有効化し、
CORTEX_ANALYST_WHを選択して更新 - ステージ内に以下の4ファイルが表示されていればOK:
daily_revenue.csvregion.csvproduct.csvrevenue_timeseries.yaml
次これ実行,
load_data.sql を使って CSVファイルをテーブルにロードする
ここでは、Cortex Searchを統合してリテラル文字列検索を改善し、Cortex Analystがより正確なSQLクエリを生成できるようにします。質問に回答するための正しいSQLクエリを作成するには、フィルタリングする正確なリテラル値を知る必要がある場合があります。これらの値は必ずしも質問から直接抽出できるとは限らないため、何らかの検索が必要になる場合があります。
Snowflake SQL ワークシートに戻り、次のcortex_search_create.sqlコードを実行してデータをテーブルにロードします。
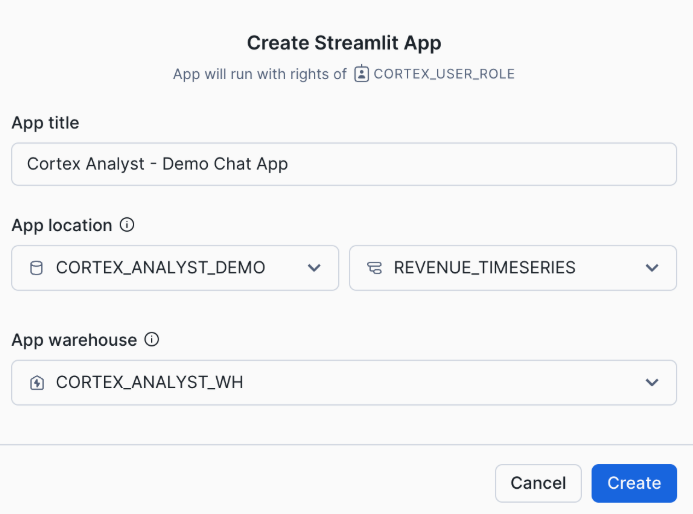
Step 1: Streamlit アプリを Snowflake 上で作成- Snowsight にログイン
- 左メニュー下部の「Apps」をクリック
- 「+ Streamlit App」をクリック
-
提供されたサンプルコードファイル:
cortex_analyst_sis_demo_app.py -
このファイルをローカルのエディタ(例:VS Code)などで開く
Step 3: コードを Snowsight の Streamlit エディタに貼り付け
- Snowsight で作成したアプリを開く
- エディタ画面が表示されるので、既存コードをすべて削除して、
cortex_analyst_sis_demo_app.pyの中身を まるごと貼り付ける- 「Save」または「Run」をクリック
Step 4: アプリを実行して質問する
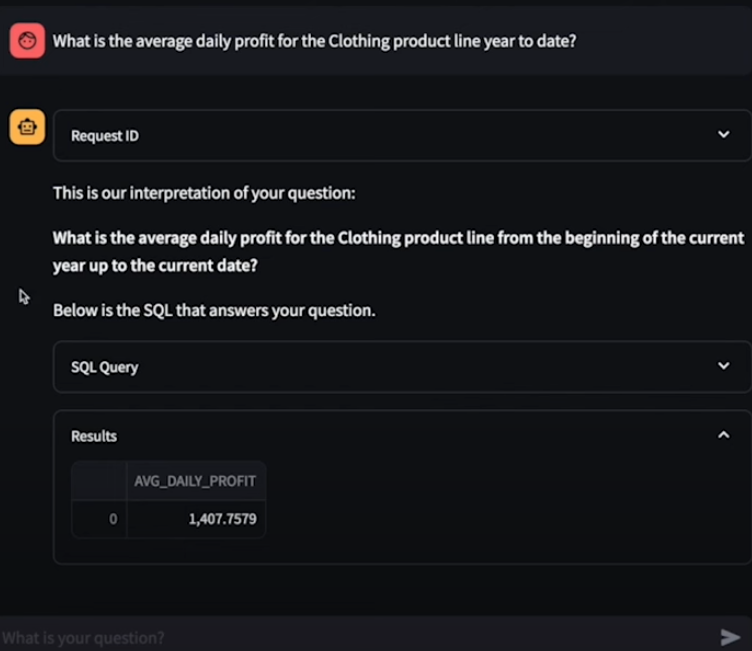
- チャットUIが起動するので、「例:What was the top product line by revenue in March?」のように自然言語で質問してみる
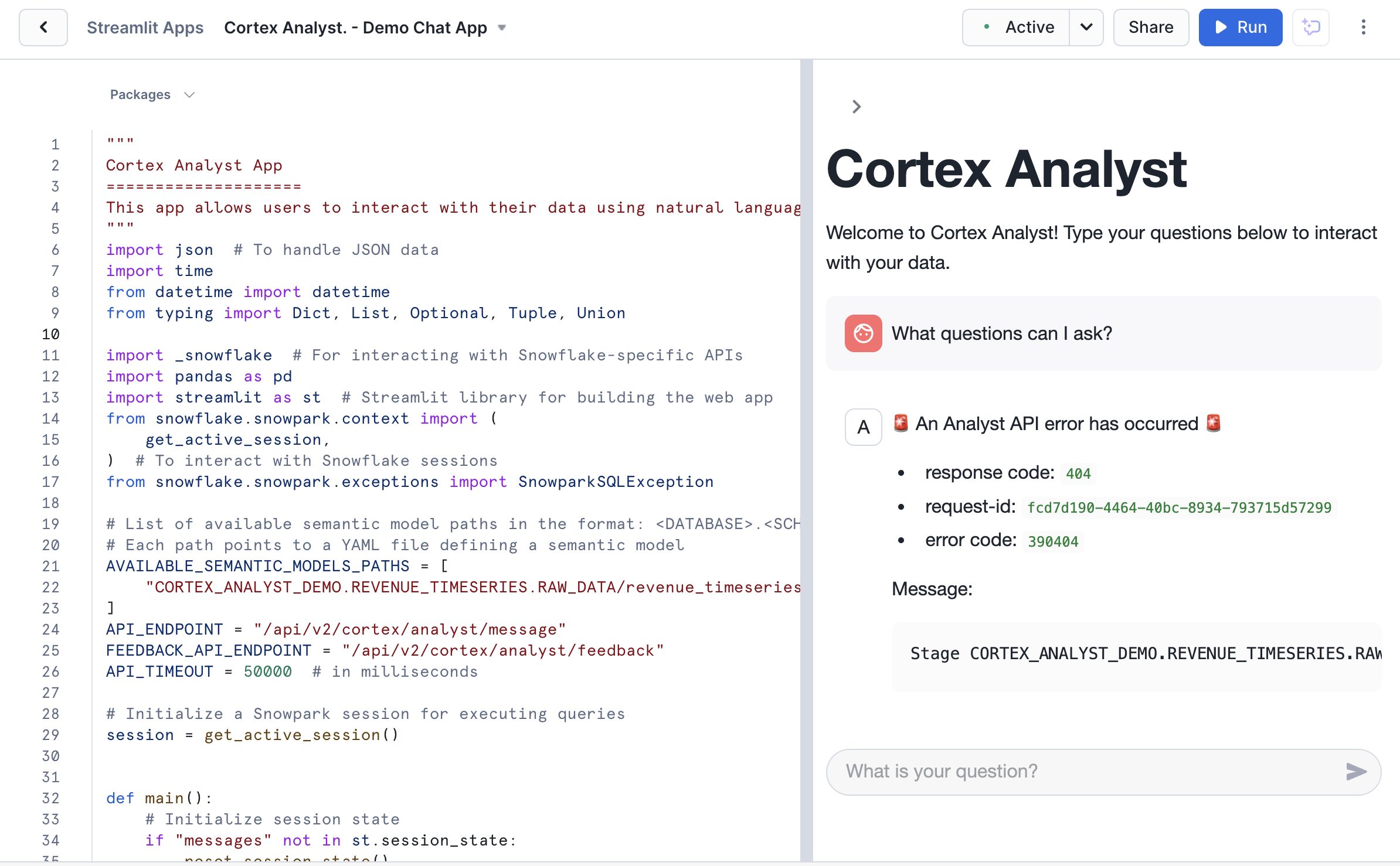
- 権限エラーが出ていて解決できていない
- Pythonのエラーっぽいので.pyの内容を確認するのがいいのかも?
公式デモの動作
Cortex Analyst実装手順(ノーコード ver)
参考記事:CCC MKホールディングス技術ブログ(2025年4月30日)
概要
Snowflake の AI & ML Studio から Cortex Analyst を使って、自然言語によるデータ分析の基盤となるセマンティックモデルを作成します。
注意点
- 現時点では 精度に限界があり、意図通りのクエリが生成されないこともある
- ただし、生成された YAML ファイルは後で手動編集が可能 なため、調整により精度を改善できる
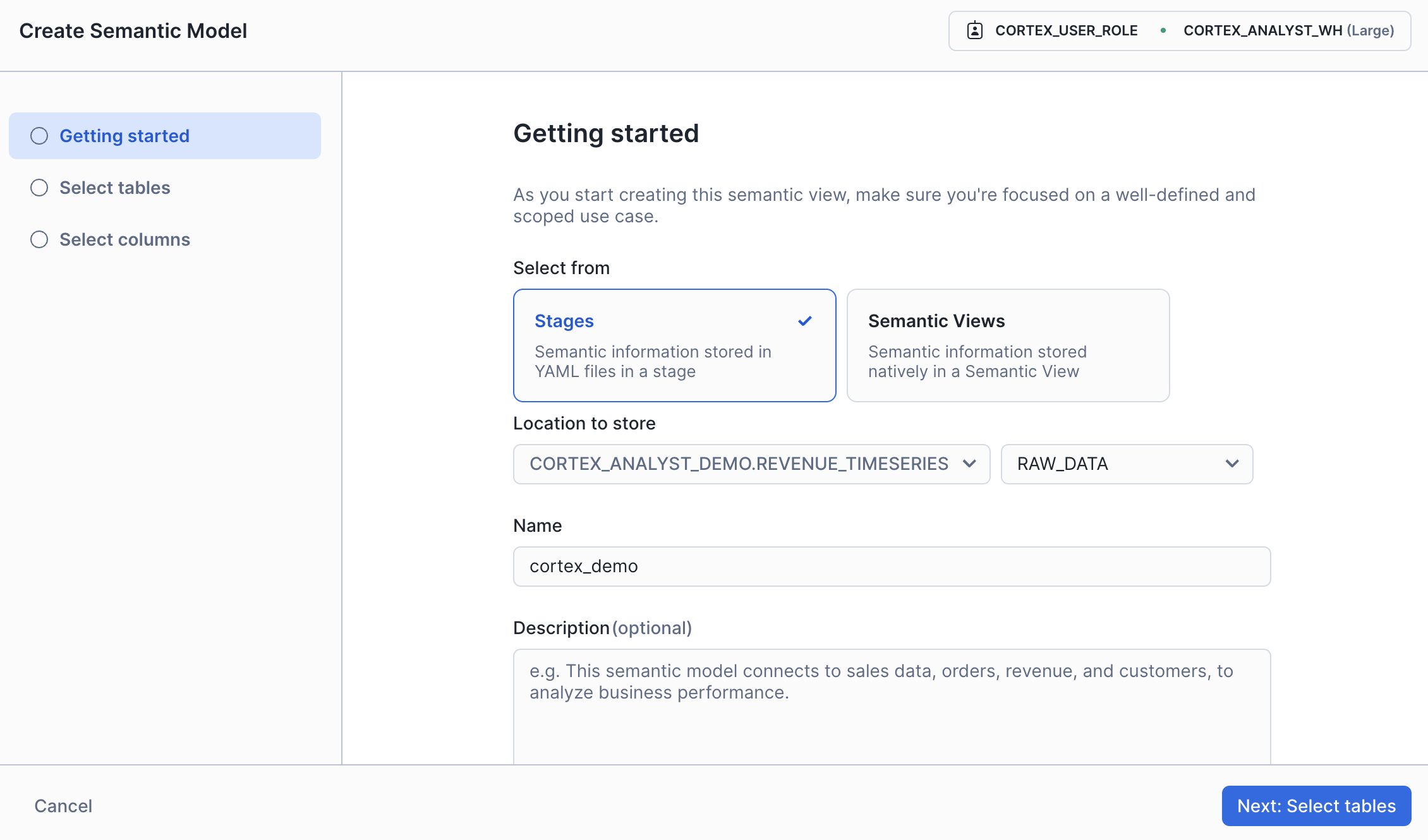
- Snowflake の AI & ML Studio にアクセス
- Cortex Analyst → 「Try」をクリック
- 「+ Create new」ボタンを押す
画面にて、以下を入力:
- Stage(保存先)
- ファイル名(例:
cortex_demo) - 説明文(任意)
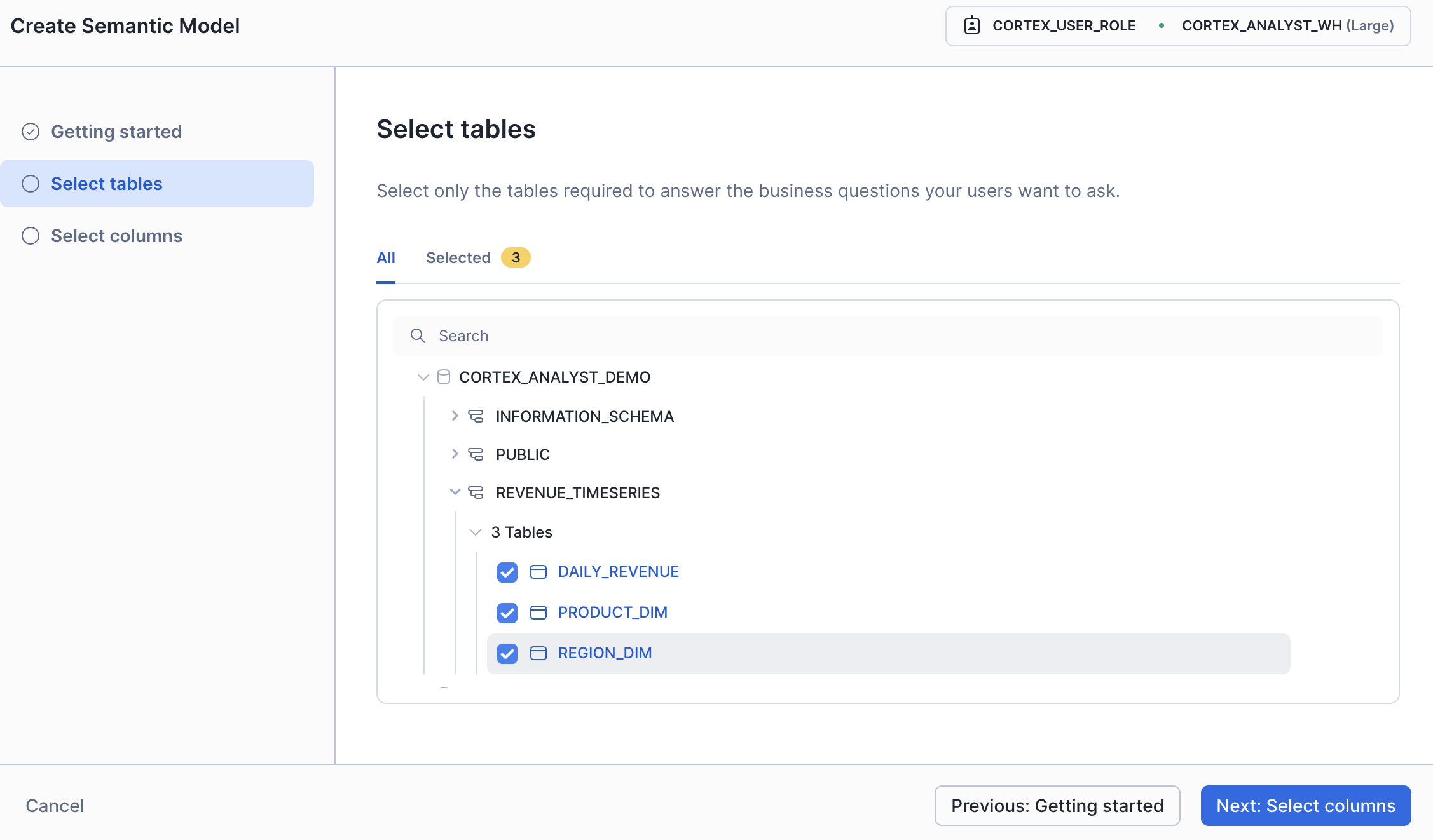
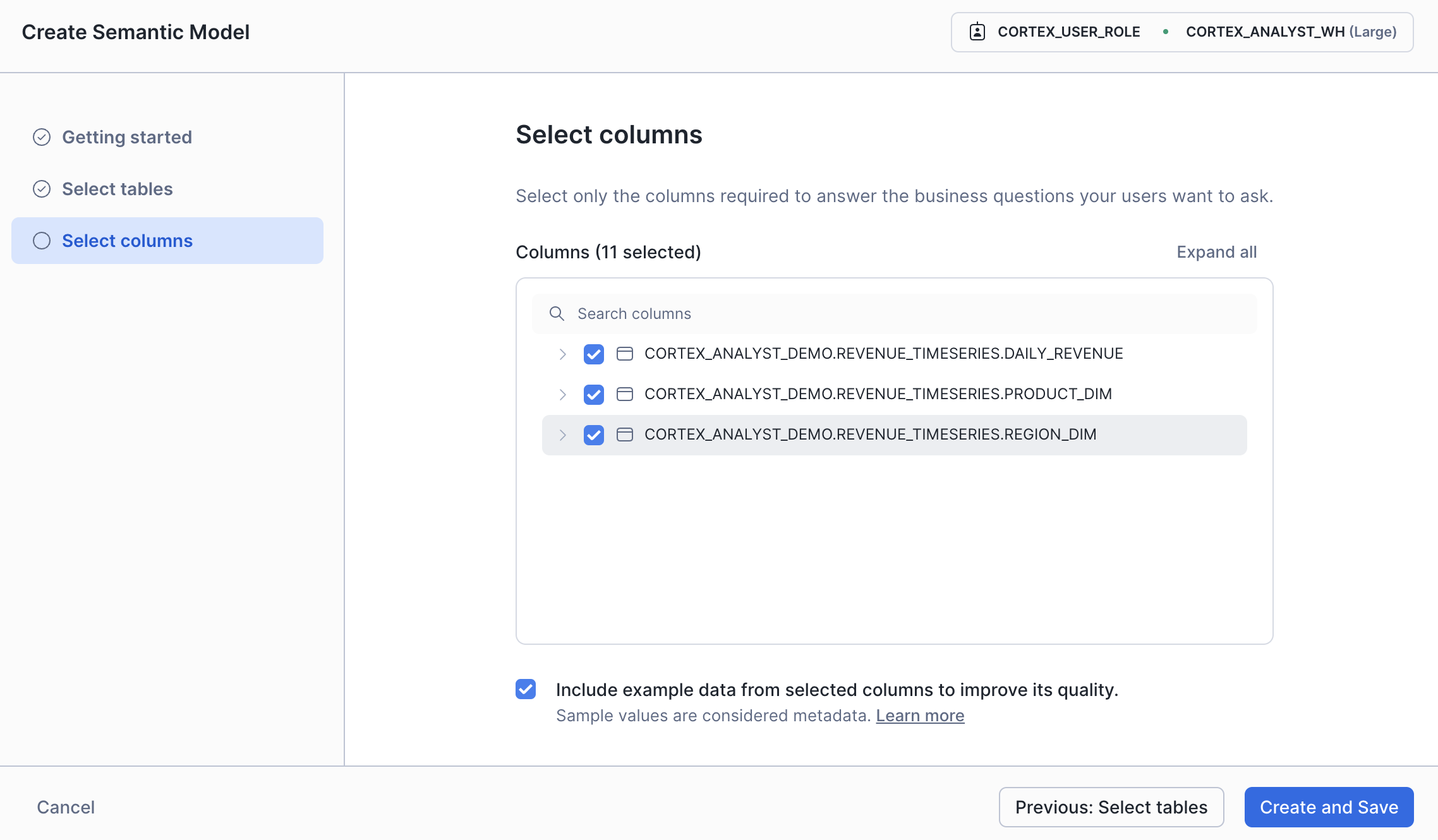
セマンティックモデルで参照するテーブルを選択します。
テーブル内の使用するカラムを選択します。
分析に必要な項目だけで絞ることも可能です。
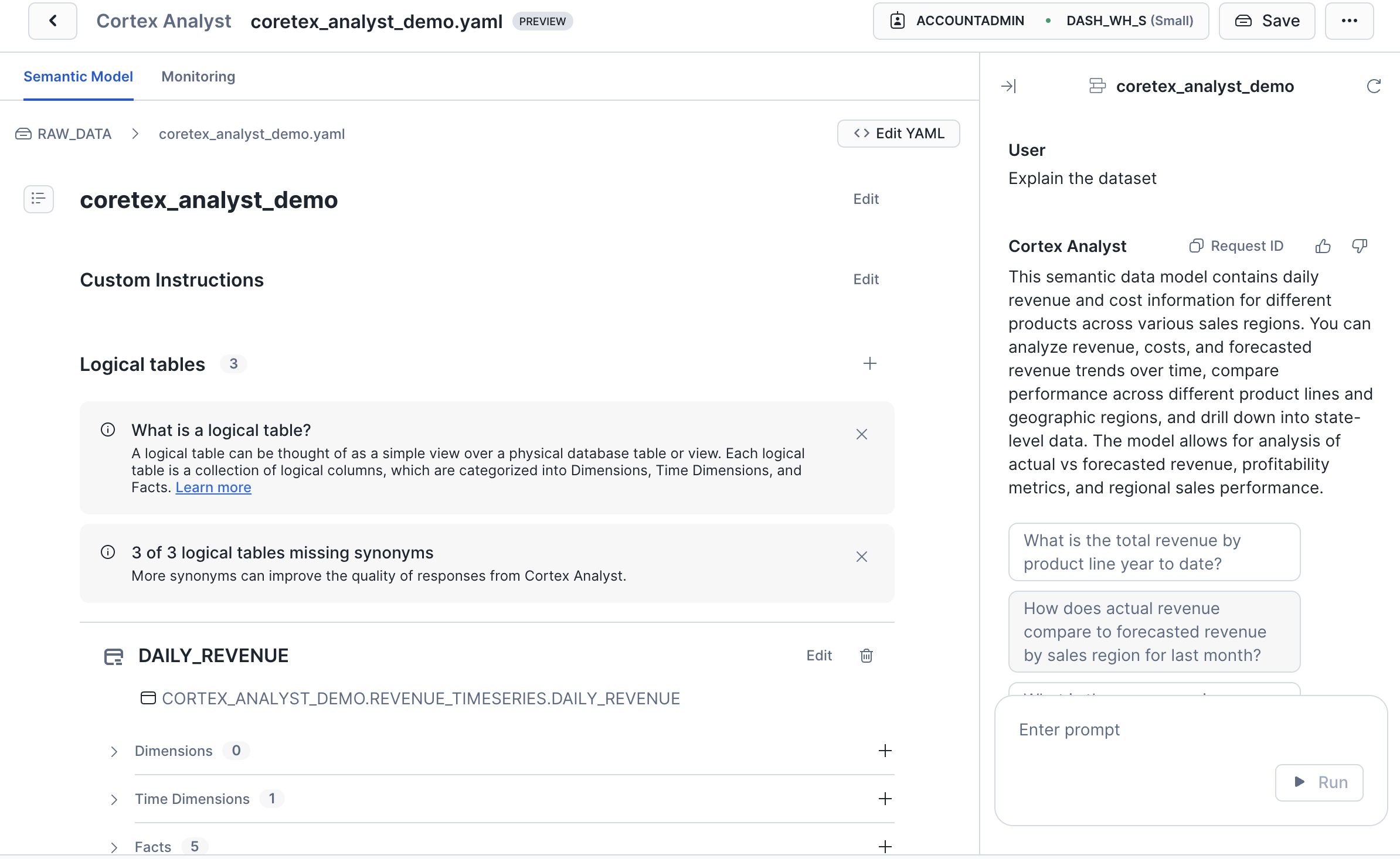
指定された情報に基づいて、Cortex がセマンティックモデル(YAML形式)を自動生成します。
このモデルはエディタから編集・調整が可能です。
現在の制限事項・課題
パフォーマンスの問題- SQL生成が遅い – 複雑なクエリの場合、応答時間が長くなる傾向
- 自動でLLMが選択されるため精度が安定しない – 同じ質問でも異なるLLMが選ばれる可能性
- 同じ指示でも出力結果が安定しない – AIの特性上、再現性に課題あり
- 自然言語の理解力が限定的 – 細かく指示しないと正しい出力が得られない場合がある
- 日本語・英語が混在 – 業務利用時に統一性に欠ける
- 日本語特有の表現や文脈の理解に制約がある
まとめ
Cortex Analyst は、Snowflake 上で自然言語によるデータ分析を可能にする強力なツールです。SQL を書かずに質問できる点は魅力ですが、生成されるクエリの内容を理解・検証するには 一定のSQL知識が必要 であり、エラー対応や意図とのズレを修正する場面では 非エンジニアには難易度が高い と感じました。
ノーコードでも試せますが、本番利用には精度・再現性・権限周りの調整が不可欠です。現時点では、PoC や社内検証用途に向いており、業務で安定運用するには今後の成熟を待つ必要があると考えます。とはいえ、将来性のある機能であり、業務データ活用の入口としてのポテンシャルは十分に感じられました。










