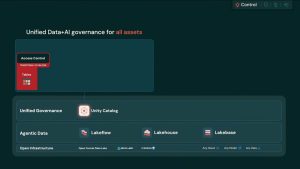
この記事の芯──Day2で繰り返された2語「コンテキスト」と「ガバナンス」が、ここでは製品そのものになっている。Context=Unity Catalog/Genie Ontology、Control(=ガバナンス)=Unity AI Gateway・権限・トレース。つまり本記事は「エージェントを“統治しながら”本番で回す」話です。
2日目キーノートの軸は「AIエージェントを“数千規模”で本番運用する基盤」。
鍵は、エージェントを作る AgentBricks と、コストと統制を担う Unity AI Gateway だった(登壇には共同創業者 Matei Zaharia も)。
なぜ難しいか:エージェント開発の3つの壁
- フロンティアモデルの激変:モデルは週単位で更新され、作り込んだソリューションがすぐ陳腐化する。
- データアクセスの複雑さ:データはPDF・外部APIなど多様なソース/フォーマットに分散し、「どの文脈を渡すか」の選択が難しい。
- セキュリティ:エージェントが機密データや本番DBに不正アクセスするリスク。
AgentBricks:Choice・Context・Control の3本柱

- Choice(選択肢):主要フロンティアモデル(Claude Opus 4.8/GPT-5.5/Gemini 3.5/Qwen 3.5/Kimi 2.7/Grok 4)にネイティブ対応。構築フレームワークも OpenAI SDK/LangGraph 等から自由に選べる。統一インターフェースでモデル差し替えが容易になり、“載せ替えコスト”を削減。
- Context(コンテクスト):Unity Catalogで全文脈を一元管理。Genie Ontologyでアセットにメタデータを付与し文脈選択の精度を上げ、Document IntelligenceでPDF等を抽出・構造化。MCPで外部データを安全に接続、エージェントメモリーでユーザー単位のパーソナライズも。
- Control(制御=ガバナンス):Databricks Sandbox(約1秒起動・VM単位の細粒度権限)で安全にコード実行。Unity AI Gateway/エージェントレジストリで全エージェント・MCP・スキルを一元管理。データの種類(PII等)に応じてポリシーを動的に変えるコンテキスト的セキュリティ、トークン上限・Smart Routing、エージェントトレーシング(MLflow Tracing)まで標準。
導入事例として 7‑Eleven(高速更新・在庫管理)、Mastercard(数百万トランザクション)、AstraZeneca(コマーシャルインサイトの迅速化)が紹介された。
エージェントを“組み合わせる”:Matei Zaharia のコンポジション論
共同創業者の Matei Zaharia は、エージェントの整合(calibration)と構成(composition)を論点に挙げた。複数エージェントを組み合わせて品質を上げる「ループ」パターンがコーディング領域で広がる一方、各社が独自実装だと整合が崩れる。さらに現場ではエージェントのウィンドウ・Slack・Google Docsを行き来してコピペする運用が常態化し、セッションやコンテキストを人・ツール間で引き継ぐ仕組みが課題だと指摘した。
OpenAI Codexデモ:マルチエージェントの協調開発
- セッションフォーク:
start_codexで会話履歴を引き継ぎ、別エージェントのセッションを開始。 - マルチエージェント並列:ClaudeとCodexを同一フォルダで同時に走らせる“コンポジション”。
- スーパーバイザー:複数エージェントの出力を比較・評価。
- 予算管理/チームポリシー:サブエージェント単位で予算(例:$1)を設定、チーム全体の利用ポリシーを中央管理。
Unity AI Gatewayデモ:積極導入とコスト抑制を両立
「トップ1%のエンジニアが年間9万ドル消費」という現実を背景に、3つの実演があった。
- 予算管理:開発者に1日$50などの上限を設定し、コーディングツール(Codex等)をそのまま接続してMCP経由で使用量を追跡。
- スマートルーティング:タスクの難度に応じて最適モデルを自動選択(簡単な質問は安価・高速モデル、複雑な調査は中高価格帯)。
- エージェントトレーシング:分散しがちなセッションのトレースを Unity Catalog に自動集約。ABAC/タグで「正しい人だけ」が閲覧可能に。
ガバナンスの肝は、データの種類に応じて動的にポリシーを変えること。たとえばエージェントがPIIに触れて操作を要求した際、ALLOW(許可)/ASK HUMAN(人間承認)/DENY(拒否)をSQLで定義した規則に従って判定する。
蓄積データの分析で「あるチームは90%のセッションで過剰スペックのモデルを使っていた」と判明。
狙いは「トークン最大化」から「価値最大化(Value Maxing)」への転換。
持ち帰り:データ活用の現場視点
エージェントは「作る」より「組み合わせて・統治して・本番で回す」段階に入った。
Choice/Context/Controlは、内製化支援でそのまま設計チェックリストになる。とくにUnity Catalog=文脈と権限の中心という構図は、Day1の主張(コンテキストが最重要)と完全に地続きである。