このブログでは、Time Series K-means法を使って、時系列データをクラスタリングする方法について解説します。K-means法との違いにも触れ、より効果的なクラスタリングが可能となる理由を説明します。また、Pythonを使って実際に分析を行う方法も解説します。本ブログを読むことで、初学者でもTime Series K-means法を理解し、時系列データをクラスタリングすることができます。
目次
Time Series K-meansとは??
Time Series K-meansは、一般的に知られているK-meansを時系列データに特化するように応用されたK-meansアルゴリズムのことです。一般的なK-meansとの違いは、Time Series K-meansは時間の影響を考慮してクラスタリングを行う点です。 一般的なK-meansは、ユークリッド距離などを用いてデータの位置に基づいたクラスタリングを行いますが、Time Series K-meansは、DTW(Dynamic Time Warping)などを用いることで単純なデータの位置関係だけでなく、時系列特性も考慮することができます。 その結果、時系列に対して精度の高いクラスタリングを行うことができます。実際にPythonで実装してみる
今回は下記のようなChatGPTに作成させた時系列データを扱います。 まずはライブラリをインポートしていきます。下記ライブラリをインポートしてくださいました。
まずはライブラリをインポートしていきます。下記ライブラリをインポートしてくださいました。
import pandas as pd
import numpy as np
from tslearn.metrics import dtw
import matplotlib.pyplot as plt
from tslearn.clustering import TimeSeriesKMeansdistortions = []
for i in range(1,11):
ts_km = TimeSeriesKMeans(n_clusters=i,metric="dtw",random_state=42)
ts_km.fit_predict(df) distortions.append(ts_km.inertia_)
plt.plot(range(1,11),distortions,marker="o")
plt.xticks(range(1,11))
plt.xlabel("Number of clusters")
plt.ylabel("Distortion")
plt.show()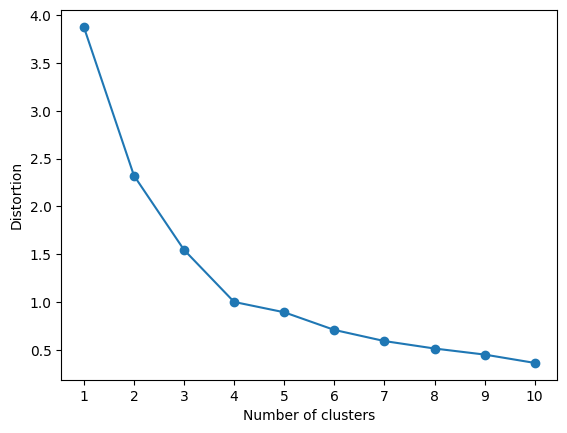 先述の結果を踏まえ、クラスターサイズを4に設定しTime Series K-meansを実装していきます。下記が実装例です。
先述の結果を踏まえ、クラスターサイズを4に設定しTime Series K-meansを実装していきます。下記が実装例です。
ts_km = TimeSeriesKMeans(n_clusters=4,metric="dtw",random_state=42)
y_pred = ts_km.fit_predict(df)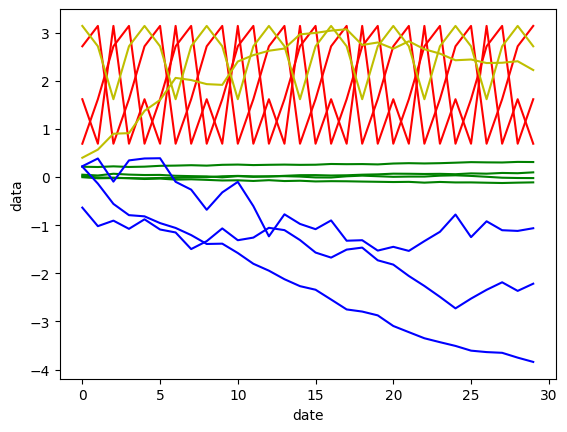 赤いクラスターは周期的な変動をしているクラスター、緑のクラスターは定常的な変動をしているクラスター、黄色は上昇傾向の変動をしているクラスター、青いクラスターは下降傾向にあるクラスターであることが確認できます。このようにTime Series K-meansを用いることで、時系列特性を踏まえてクラスタリングができます。
赤いクラスターは周期的な変動をしているクラスター、緑のクラスターは定常的な変動をしているクラスター、黄色は上昇傾向の変動をしているクラスター、青いクラスターは下降傾向にあるクラスターであることが確認できます。このようにTime Series K-meansを用いることで、時系列特性を踏まえてクラスタリングができます。








