dbt Cloud使ってをBigQuery上のDWHデータに対してトランスフォーム(変換)を行うための簡単な手法を紹介しています。
はじめに
データパイプラインのELTにおけるT(Transform)の役割を担うdbt (data build tool) は、SQLのスキルのみでデータ変換、テスト、ドキュメント生成を行える強力なツールです。今回は、DWHのデータをBigQuery上でトランスフォームするため簡単な手法を、dbt Cloudを使用して紹介します。
ステップ1: データのインポート
まず、BigQueryに任意のデータセットを作成しデータをアップロードします。
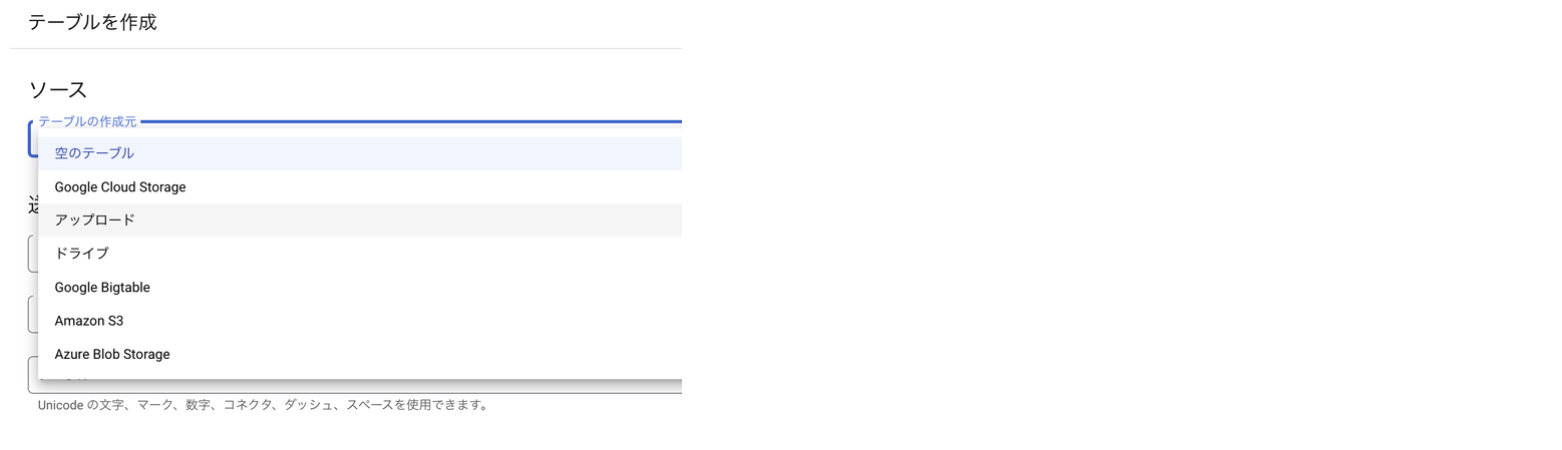
ここではkaggle datasets公開されているスターバックスのドリンクデータを使います。
ステップ2: dbt Cloudのセットアップ
・dbt Cloudにサインアップまたはログインします。
・新しいプロジェクトを作成し、ナビゲーションに従ってBigQueryを接続します。
ステップ3: モデル作成
models配下にsources.ymlとstarbucks_drinks.sqlファイルを作成します。

ステップ4: データのトランスフォーム(変換)
今回はドリンクのカロリーが350kcal以上のドリンクをフィルタリングして、BigQuery上のデータを変換していきます。
【materialized】について
dbtではmaterializedを使用して、どのようにデータセットを物理的に保存・更新するかを指定することができます。materializedには、以下の4種類があります。
view:
・通常のデータベースのビューと同様。
・クエリが実行されるたびにリアルタイムでデータが再計算される。
table:
・実際のテーブルとしてデータが物理的に保存される。
・dbt runが実行されるたびに、テーブルは再作成される。
incremental:
・大量のデータを効率的に更新するためのマテリアライズ。
・既存のテーブルに新しいデータを追加することができ、全データを再作成する必要はない。
・フィルター条件やキーを設定することで、最新のデータのみを追加・更新することができる。
ephemeral:
・実際のデータベースオブジェクトとしては保存されない。
・他のモデルの中間ステップとして使用されることを目的としている。
・dbtの中でのみ存在し、外部からはアクセスできない。
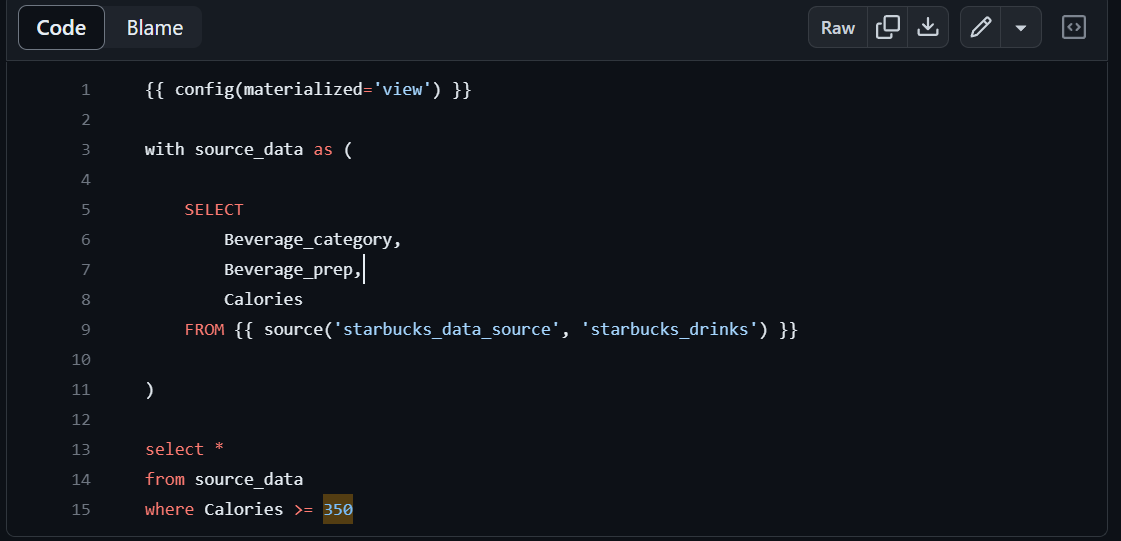
今回は実際のテーブルに対して変更を加えるためtableを使用していきます。
{{ config(materialized='table') }}
with source_data as (
SELECT
Beverage_category,
Beverage_prep,
Calories
FROM {{ source('starbucks_data_source', 'starbucks_drinks') }}
)
select *
from source_data
where Calories >= 350ステップ5: ソースの設定
dbtプロジェクトにおいて、外部のデータソースに接続するための設定を行うことが重要です。このステップでは、BigQueryの特定のデータセットとテーブルを指定して、そのデータソースをdbtで利用可能にする方法を紹介します。
・sources.ymlの編集:
dbtプロジェクトのルートディレクトリにあるsources.ymlファイルをエディタで開きます。
・ソースの定義:
ファイルの下部に、以下の内容を追記します。この設定では、BigQueryのdbt-datapipeline-testプロジェクトのstarbucks_dataデータセットに存在するstarbucks_drinksテーブルを指定しています。
version: 2
sources:
- name: starbucks_data_source
database: dbt-datapipeline-test
schema: starbucks_data
tables:
- name: starbucks_drinks
ステップ6: デプロイ
トランスフォームとテストが成功したら、変更を本番環境にデプロイします。
・dbt Cloudのダッシュボードで、作成したモデルを選択します。
・dbt runでデプロイを完了します。

・Big Query側を確認するとデータに変更が加えられ350キロカロリー以上のドリンクに絞られていることが確認できます。

まとめ
dbt CloudとBigQueryは、モダンデータスタックにおいて非常に強力なツールとして認識されています。これらのツールを組み合わせることで、SQLの知識だけでデータの変換やデプロイを効率的に行うことができます。
また今回はクエリのテストをに関する詳細は省いていますがdbtはテスト機能を内蔵しており、データ変換の過程で品質の確保が可能です。
さらに変更などのトラッキングやモデルの管理にはGitHubと連携することでバージョン管理も容易に行うことができます。
![]()
このような機能の組み合わせにより、データの品質と整合性を保ちながら、迅速かつ確実にデータ変換を進めることができます。










