
本記事では、実際に外部データを用意し、RAGの実装フローを詳しく説明し、GCP環境を使用した開発環境の構築から、システムアーキテクチャ、テキストの抽出、エンベディング処理、ベクトル検索インデックスの作成までのプロセスを解説しています。
RAGとは??
RAG(Retrieval-Augmented Generation)とは、自然言語処理(NLP)の分野で使われる技術の一つで、特に大規模言語モデル(LLM:Large Language Models)を強化するために開発されました。この技術は、言語モデルが情報を生成する際に、単に内部の知識を使うだけでなく、外部から特定の情報を「検索(Retrieval)」してきて、それを元に「生成(Generation)」することを可能にします。RAGを使用することで下記のようなメリットを受けることができます。
- 最新情報の活用: RAGは外部から情報を取得するため、大規模言語モデルが訓練された時点の知識に限らず、最新の情報を反映することが可能です。
- 情報の正確性向上: 検索によって得られた情報を基に生成するため、特定の事実やデータに基づいたより正確な回答が可能になります。
- 応用範囲の拡大: 様々なデータベースや知識源にアクセスすることで、幅広い分野に対応できるようになります。
今回実装するサンプル
今回はRAGの一連の実装フローを解説していきます。今回、外部データはAWSが提供するインスタンスの稼働状況や利用金額などが示されているCUR(Cost and Usage Reports)と呼ばれるデータのリファレンスを対象に一連のフローを実装していきます。対象のドキュメントは下記リンクのものを採用しました。
開発環境について
今回、GCP環境の下記サービスを利用してRAGの実装をしていきます。他クラウド(AWS、Azure)でも代替サービスは用意されているので参考にしてください。
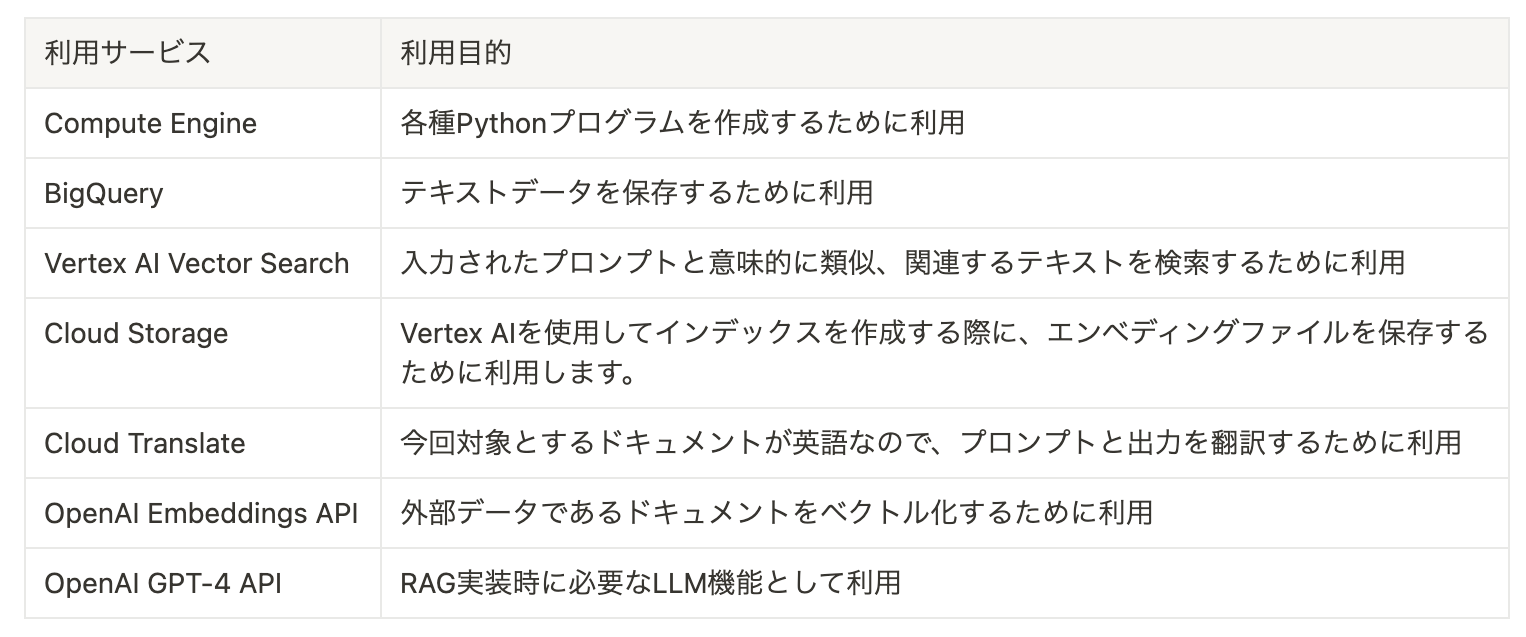
実装フロー① 〜システムアーキテクチャ〜
今回実装したフローのシステムアーキテクチャは下記になります。大きく2つのフローにより構成されています。1つ目は、外部データをベクトル化しVector DBとしてベクトル検索できるように準備するフローです。2つ目は、入力されたプロンプトとそれに関連したテキストを検索しそれらをチェインしてLLMに入力させるフローです。実際にアプリケーションとして運用する場合は、2つ目のフローのみを稼働させ、1つ目のフローは外部データを更新する時のみ実行するイメージです。
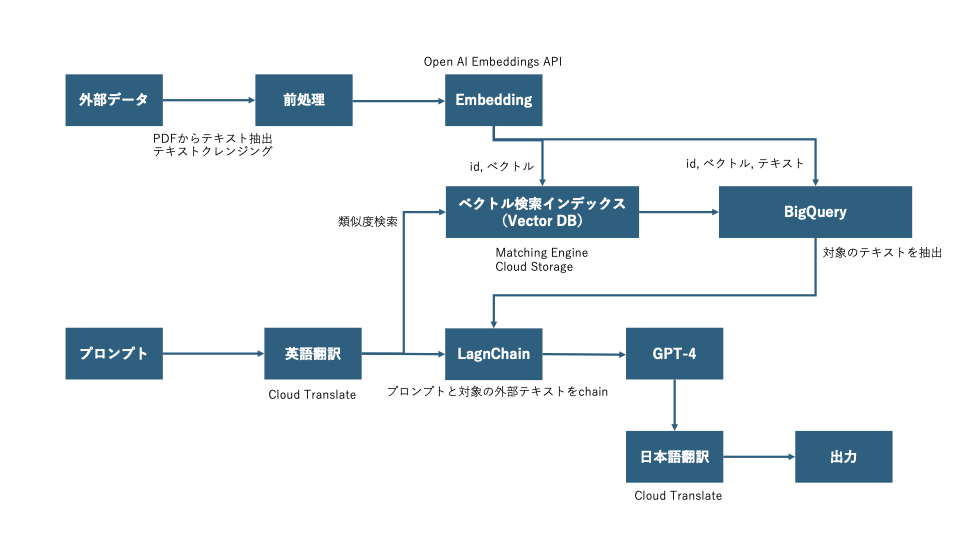
実装フロー② 〜テキストの抽出〜
まずは、ベクトル化したいドキュメントのテキストを抽出し、クレンジング処理から実装していきます。下記が実装例です。下記プログラムにより、cur-user-guide.pdfからテキストを抽出し、不要な文字列を削除しクレンジングします。
import pandas as pd
from pdfminer.high_level import extract_text
import uuid import re
# データ列解説ページを抽出
text = extract_text('../data/cur-user-guide.pdf', page_numbers=list(range(8, 261)))
# 不要な文字列の削除
def drop_text(text):
text = text.replace('\n\n', '\n')
text = text.replace('\n', ' ')
text = text.replace('AWS Data Exports', '')
text = text.replace('User Guide', '')
text = text.replace('A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | VWXYZ', '')
text = text.replace('Topic', '') text = text.replace('Note', '') text = text.replace('Importtant', '')
text = text.replace('\x0c', '') text = re.sub(r' {3,4}', ' ', text) text = re.sub(r'(?<=\w) (?=\w)', '', text)
return text
text = drop_text(text)
# 抽出したテキストをピリオドを基準に1文ずつ切り出してリストに格納
cur_guide_text = [part + '.' for part in text.split('.') if part]
# 意味のないテキストを削除するために文字数が10字以上のテキスト以外は削除
cur_guide_text = [s for s in cur_guide_text if len(s) > 10]
# ベクトル検索インデックス作成時に必要なid列を作成
df = pd.DataFrame() df['ID'] = [str(uuid.uuid4()) for _ in range(len(cur_guide_text))]
df['cur_guide_text'] = cur_guide_text
df.to_pickle('../data/cur_guide_eng_df.pkl')
上記プログラムのポイントは、データクレンジングの最後にid列を作成している点です。Vertex AI Vector Searchを利用してベクトル検索インデックスを作成する場合、idとベクトル配列で対応されたjsonデータが必要です。そのため、データクレンジング後に重複が出ないようUUIDでidを作成しています。
実装フロー③ 〜エンべディング処理〜
テキストの抽出と前処理が終わったら、次はエンべディング処理を実装していきます。まずは下記ライブラリをインポートします。
from openai import OpenAI
import pandas as pd
from google.oauth2 import service_account
from google.cloud import bigquery
import numpy as np
from tqdm import tqdm
import json
from typing import List
import os次に、下記のようにAPIキーの設定とデータセットのインポートを行います。
# APIキーを設定
api_key = '< OpenAIのAPIキーを設定 >'
os.environ["OPENAI_API_KEY"] = api_key
# OpenAIのインスタンス作成
openai_client = OpenAI()
# idと前処理を施したテキストのデータセットをインポート
df = pd.read_pickle('../data/cur_guide_eng_df.pkl')次にエンべディング部分を実装していきます。ここでもVertex AI Vector Searchの利用に向けたデータフォーマットに加工して実装します。最終的にidとベクトル配列が対応したjsonを出力したいので、下記のように実装しました。
with open('../output/cur_guide_eng_vectors.json', 'w') as f:
for loop_num in tqdm(range(df.shape[0])):
detail_text = df['cur_guide_text'][loop_num]
id = df['ID'][loop_num]
# この部分でテキストをベクトル化している
vector = openai_client.embeddings.create(model="text-embedding-3-large", input=detail_text).data[0].embedding
json_record = {'id':id, 'embedding': vector}
f.write(json.dumps(json_record))
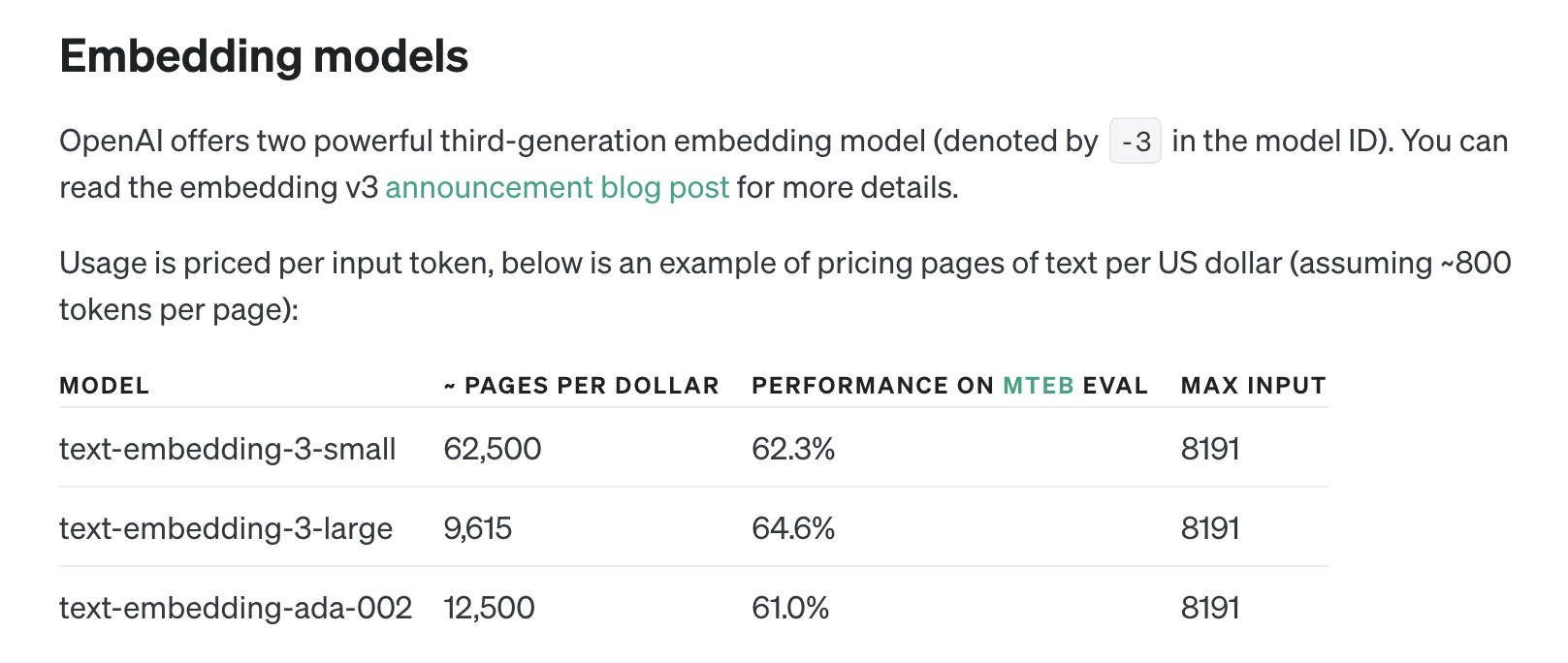
f.write('\n')OpenAIのEmbeddings APIではsmallとlargeの2つのモデルが用意されています。今回は精度の高いlargeモデルを採用していますが、必要に応じて使い分けて下さい。
引用元:https://platform.openai.com/docs/guides/embeddings/use-cases
先述のコードで、Vertex AI Vector Searchで必要なjsonファイルの準備はできました。しかし、このjsonファイルにはidとベクトル値しかありません。そのため、入力のプロンプトと類似しているベクトルがどのテキストと対応しているのか探せるように、id、ベクトル、テキストが対応したデータセットをBigQueryに保存します。下記のようにBigQueryにデータセットを保存します。
def save_df_to_bq(df, table_id):
service_account_key = '< BigQueryにアクセス権のあるサービスアカウントのcredentialを定義 >'
credentials = service_account.Credentials.from_service_account_file(service_account_key)
bq_client = bigquery.Client(credentials=credentials)
job_config = bigquery.QueryJobConfig(write_disposition='WRITE_APPEND')
job = bq_client.load_table_from_dataframe(df, table_id)
job.result()
table_id = '< データの保存先のテーブルidを指定 >'
save_df_to_bq(df, table_id)
実装フロー④ 〜ベクトル検索インデックスの作成〜
続いて、Vertex AI Vector Searchを使ってベクトル検索インデックスを作成していきます。まずは、下記ライブラリをインポートします。
import pandas as pd
from google.oauth2 import service_account
import json
import subprocess
from google.cloud import aiplatform
from google.cloud import storageベクトル検索インデックスの作成は、GCPのVertex AI Vector SearchとCloud Storageを利用します。そのため、まずGCP環境の初期設定を行います。具体的にはサービスアカウントのアクティベイトとGCP環境のproject_idとlocationの取得を行います。下記を実行することでproject_id, location, credentialsが取得できます。
def load_credentials():
key_file_path = '< サービスアカウントのcredentialを定義 >'
credentials = service_account.Credentials.from_service_account_file(key_file_path)
return key_file_path, credentials
def init_gcp():
key_file_path, credentials = load_credentials()
# サービスアカウントのアクティベイト
cmd = ['gcloud', 'auth', 'activate-service-account', '--key-file={}'.format(key_file_path)]
result = subprocess.run(cmd, check=True, capture_output=True, text=True)
# PROJECT IDの取得 cmd = ['gcloud', 'config', 'get-value', 'project']
PROJECT_ID = subprocess.run(cmd, check=True, capture_output=True, text=True).stdout.strip()
LOCATION = "asia-northeast1"
return PROJECT_ID, LOCATION, credentials
project_id, location, credentials = init_gcp()続いて、今回利用するツールのAPIを有効化します。下記コードを実行することでVertex AIとCloud StorageをAPIで呼び出すことができます。
cmd = ['gcloud', 'services', 'enable', 'compute.googleapis.com', 'aiplatform.googleapis.com', 'storage.googleapis.com', '--project', project_id]
result = subprocess.run(cmd, check=True, capture_output=True, text=True)続いて、先ほど作成したidとテキストのベクトルが対応したjsonファイルをCloud Storageの指定のバケットにアップロードします。下記コードを実行することで先ほど作成したjsonファイルを指定のバケット内にアップロードすることができます。
def upload_blob(bucket_name, source_file_name, destination_blob_name, credentials):
storage_client = storage.Client(credentials= credentials)
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(destination_blob_name)
if blob.exists():
blob.delete()
generation_match_precondition = 0
blob.upload_from_filename(source_file_name, if_generation_match=generation_match_precondition)
print(f"File {source_file_name} uploaded to {destination_blob_name}.")
bucket_name = '< バケット名 >'
source_file_name = ' <アップロードしたいファイルのパス> '
destination_blob_name = '< アップロード先のパス >'
upload_blob(bucket_name, source_file_name, destination_blob_name, credentials)続いて、Vertex AI Vector Searchを使ってベクトル検索インデックスを作成していきます。まずは今回利用するVertex AIのAI platformの初期化を行います。下記コードを実行して初期化を行なって下さい。
# AI platformの初期化
aiplatform.init(project=project_id, location=location, credentials=credentials)次に、インデックスを作成します。下記コードを実行するとインデックスを作成できます(少し時間がかかります)。aiplatform.MatchingEngineIndex.create_tree_ah_indexの引数のポイントはdimensionsとapproximate_neighbors_countになります。dimensionsはアップロードしたjsonのベクトルが何次元のものなのかを定義します。今回はOpenAIのEmbeddings APIのlargeモデルを利用したので出力は3072次元になります。そのため、ここでも次元数は3072と定義します。approximate_neighbors_countは類似度検索する際、類似した要素を何個出力するかを定義します。今回は10で定義しているので、類似度検索した結果の中から類似度の高い要素を10個出力する仕様になっています。ここの数値を変えることで、出力数を制御することができます。
display_name = f"< GCPのGUI上の表記名 >"
# インデックスの作成
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = display_name,
contents_delta_uri = '< 先ほどjsonファイルをアップロードしたCloud Storageのgsutil URI >',
dimensions = 3072, # ベクトルの次元数
approximate_neighbors_count = 10) # 類似度検索の出力数 インデックスの作成ができたら、次はエンドポイントを作成しデプロイします。下記コードを実行し、エンドポイントの作成とデプロイを行なって下さい(少し時間がかかります)。この実行が完了すると、ベクトル検索インデックスが利用できる状態になります。
# IndexEndpointの作成
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = display_name,
public_endpoint_enabled = True
)
# Index Endpointのデプロイ
my_index_endpoint.deploy_index(
index = my_index,
deployed_index_id = display_name
)実装フロー⑤ 〜LangChainの実装〜
テキストのベクトル化とベクトル検索インデックスの作成が済んだのでいよいよLangChain部分の実装をしていきます。まず、下記コードを実行し必要なライブラリをインポートして下さい。
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.documents import Document
from google.cloud import aiplatform
from google.cloud import translate
import json次に、先ほどデプロイしたベクトル検索インデックスのエンドポイントをロードします。下記コードを実行してエンドポイントを呼び出して下さい。my_index_endpoint_idはGCPのコンソール画面で確認することができます。
def load_index_endpoint():
# 先述の関数を利用しています。
project_id, location, credentials = init_gcp()
# AI platformの初期化
aiplatform.init(project=project_id, location=location, credentials=credentials)
my_index_endpoint_id = "< デプロイしたインデックスポイントのid >"
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint(my_index_endpoint_id)
return my_index_endpoint
# エンドポイントの呼び出し
my_index_endpoint = load_index_endpoint()次に、入力プロンプトの翻訳処理を実装します。今回ベクトル化した外部データは英語のドキュメントのため、日本語よりも英語の方が類似度検索が上手く機能すると考えこのような仕様にしました。また、今回入力プロンプトとするのは「AWSのCURに関する質問です。価格を意味するデータ列にBlendedCostとunBlendedCostがあると思いますが、これらはどのような違いがあるのでしょうか?」にします。
本関数のポイントはsource_language_codeとtarget_language_codeです。これらは、翻訳したいテキストの現言語と、どの言語に翻訳したいのかを定義します。今回は日本語のプロンプトを英語に翻訳したいので、source_language_codeをja、target_language_codeをen-USと定義しています。
query = 'AWSのCURに関する質問です。価格を意味するデータ列にBlendedCostとunBlendedCostがあると思いますが、これらはどのような違いがあるのでしょうか?'
def text_translate(text, source_language_code, target_language_code):
# 先述の関数を使用
project_id, _, credentials = init_gcp()
client = translate.TranslationServiceClient(credentials=credentials)
location = "global"
parent = f"projects/{project_id}/locations/{location}"
response = client.translate_text(
request={
"parent": parent,
"contents": [text],
"mime_type": "text/plain",
"source_language_code": source_language_code,
"target_language_code": target_language_code
}
)
return response.translations[0].translated_text
query = text_translate(query, 'ja', 'en-US')次に、英訳した入力プロンプトで外部データにベクトル検索するために、英訳したプロンプトをベクトル化します。下記を実行して、プロンプトをベクトル化します。この部分の仕様は以前外部データをベクトル化した時と同じです。
# APIキーを設定
api_key = '< OpenAIのAPIキー >'
def convert_query_vector(api_key, query):
os.environ["OPENAI_API_KEY"] = api_key
openai_client = OpenAI()
query_vector = openai_client.embeddings.create(model="text-embedding-3-large", input=query).data[0].embedding
return query_vector
query_vector = convert_query_vector(api_key, query)次に、入力プロンプトと類似しているテキストのidを取得していきます。下記コードを実行し、入力ポイントと類似度の高い上位10個のテキストのidを取得することができます。
deployed_index_id = f" デプロイしたエンドポイントの表記名 "
# ベクトル検索の結果が返ってくる
response = my_index_endpoint.find_neighbors(
deployed_index_id = deployed_index_id,
queries = [query_vector],
num_neighbors = 10
)
# 入力プロンプトと類似度の高いテキストのidをid_listに格納する
id_list = ()
for id, neighbor in enumerate(response[0]):
id_list = (id_list +(neighbor.id,))上記では、入力プロンプトと類似度の高いテキストのidは取得できますが、そのテキストがどんなテキストなのかは取得できません。そのため、先ほどBigqueryに保存したテーブルからid_listのテキストぶんを取得してきます。下記コードを実行しテキストを取得していきます。
bq_query = f""" SELECT * FROM < データセットを保存したテーブルのパス > WHERE ID IN {id_list} """
def load_data(query):
_, credentials = load_credentials()
bq_client = bigquery.Client(credentials=credentials)
return bq_client.query(query).to_dataframe()
df = load_data(bq_query)
# 取得してきたテキストをlist化
context = list(df.cur_guide_text)
# LangChainに向けて、10個のテキスト文を1つの文字列に変換
context = [sentence + "." if not sentence.endswith(".") else sentence for sentence in context]
context = " ".join(context)いよいよLangChainのコア部分の実装をしていきます。大まかな流れは下記のようになります。

下記コードを実行することで、RAGによる文章生成が可能になります。
# 使用するLLMモデルを定義 gpt_model = 'gpt-4-0125-preview' # LangChain用のインスタンスの作成 llm = ChatOpenAI(model_name=gpt_model, openai_api_key=api_key) # プロンプトのフォーマットを定義 prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:{context} Question: {input} """ ) # LLMとプロンプトをchain document_chain = create_stuff_documents_chain(llm, prompt) # 入力プロンプトと類似度の高かったテキストデータを先ほどのプロンプトのフォーマットに埋め込み実行 response_rag = document_chain.invoke({ "input": query, # 入力プロンプト "context": [Document(page_content=context)] # 類似度の高かったテキストデータ } ) # 返ってきた出力を英語から日本語に翻訳 response_rag = text_translate(response_rag, 'en-US', 'ja')
検証
今回の入力プロンプトをRAGありバージョンとRAGなしバージョンで出力しました。
入力プロンプト:AWSのCURに関する質問です。価格を意味するデータ列にBlendedCostとunBlendedCostがあると思いますが、これらはどのような違いがあるのでしょうか?
RAGありバージョンの出力
AWS CUR (コストと使用状況レポート) では、BlendedCost と unBlendedCost の違いは、一括請求を使用して AWS Organizations 内のアカウントのコストが計算される方法に関係します。
BlendedCost: これは、AWS 組織内のすべてのアカウントで使用される AWS サービスの平均コストを表します。一括請求を使用する場合、AWS はすべてのアカウントにわたるサービス (EC2 インスタンスなど) のコストを平均して BlendedCost を計算します。これは、組織内の異なるアカウントが同じサービスに対して異なる料金を支払っている場合 (ボリューム ディスカウント、予約インスタンスなどにより)、混合コストには、すべてのアカウントにわたるそのサービスの平均料金が反映されることを意味します。これは、組織の AWS 使用の全体的な費用対効果を理解するのに役立ちます。
unBlendedCost: 対照的に、unBlendedCost は、組織全体で平均することなく、各個別のアカウントで使用される AWS サービスの実際のコストを指します。このコストには、各アカウントに適用される特定の料金と割引が反映されており、AWS サービスに対してそのアカウントに実際に請求されている金額をより正確に把握できます。これは、混合コストに見られる平均化効果なしで、特定のアカウントの使用に関連する直接コストを確認するのに役立ちます。
これら 2 種類のコストの違いを理解することは、組織が AWS 支出をより効果的に分析し、コストが発生している場所と、コストを節約するために AWS の使用を最適化する方法を特定するのに役立ちます。
RAGなしバージョンの出力
AWS のコストと使用状況レポート (CUR) は、AWS サービスの使用とそのコストに関する詳細なデータを提供します。 AWS の請求書または CUR を分析するとき、「BlendedCost」や「UnblendedCost」などのさまざまなコスト関連の用語が登場します。 AWS の支出を正確に分析するには、これらの用語の違いを理解することが重要です。
UnblendedCost定義: UnblendedCost は、割引、リザーブドインスタンス、または節約プランを考慮せずに、各 AWS サービスの使用にかかる直接コストを表します。基本的には、「定価」に使用量を乗じた金額になります。
使用例: 価格モデルや割引適用の影響を受けずに、AWS リソースに関してどれだけ消費しているかを把握するのに特に役立ちます。この値は、割引や特別な価格調整が適用される前に、実際の使用コストを評価するのに役立ちます。
blendedCost定義:
一方、BlendedCost では、一括請求ファミリー内のアカウント間の割引と価格の平均化が考慮されます。リザーブドインスタンス (RI) または節約プランを使用している組織の場合、AWS は混合料金を適用します。これは、組織内のアカウント全体でリザーブドインスタンスとオンデマンドインスタンスのコストを平均します。
使用例: これは、一括請求ファミリーのすべてのアカウントにわたるリザーブド インスタンスと節約プランのコスト効率と影響を分析するのに役立ちます。これは、AWS 支出の全体的な費用対効果を理解するのに役立ちます。
主な違い:価格に関する考慮事項: BlendedCost では、統合請求先アカウント全体でのリザーブド インスタンス、節約プラン、その他の割引メカニズムの影響が考慮されますが、UnblendedCost では、そのような考慮事項が考慮されていないコストが表示されます。
請求の最適化での使用: UnblendedCost は、サービスの実際の使用コストを特定するために重要です。これは、割引を適用する前に、最適化またはコスト削減の可能性のある領域を特定するのに役立ちます。 BlendedCost は、組織全体での RI や貯蓄プランの使用状況など、コスト最適化戦略の全体的な有効性を評価するのに役立ちます。
コスト分析への効果: 多くの RI または節約プランを使用している組織の場合、BlendedCost は、コスト共有戦略の利点を含め、組織内の全員が貢献している実際のコストのより正確な情報を提供します。ただし、詳細なサービス レベル分析の場合、または新しい予約や割引プランを検討する場合は、UnblendedCosts を調べて、さらなる割引の機会を理解することもできます。
要約すると、BlendedCost と UnblendedCost の両方が AWS のコスト管理と最適化において役割を果たします。どちらを使用するかを選択するのは、実際の使用コストを分析するか、支出を最適化するか、一括請求ファミリー全体での節約戦略の有効性を評価するかなど、特定のニーズによって異なります。
出力結果のレビュー
両者ともに、質問に対してしっかり回答はできています。ただ、RAGありの方が下記観点で出力精度が高いのではないかと考えています。
- RAGなしの場合は、質問に対して余分な言及が多く見受けられた。一方RAGありの場合は、質問に対してダイレクトな回答のみを出力しているため、質問に対しての回答の要点がまとまっている。
- RAGなしの場合は、文言が定義付けられた文章感があり、ドキュメントに記載されている文章をそのまま出力しているような出力になっている(「定義」の部分)。一方RAGありの場合は、ドキュメントにある知見を基に2つのcostの違いを述べているため、回答が自然な会話のように感じた。
このような背景から、既にLLM内にあるような知識であっても、RAGを実装することで、より自然でユーザーが理解しやすい回答を生成することができるのではないかと考えています。









