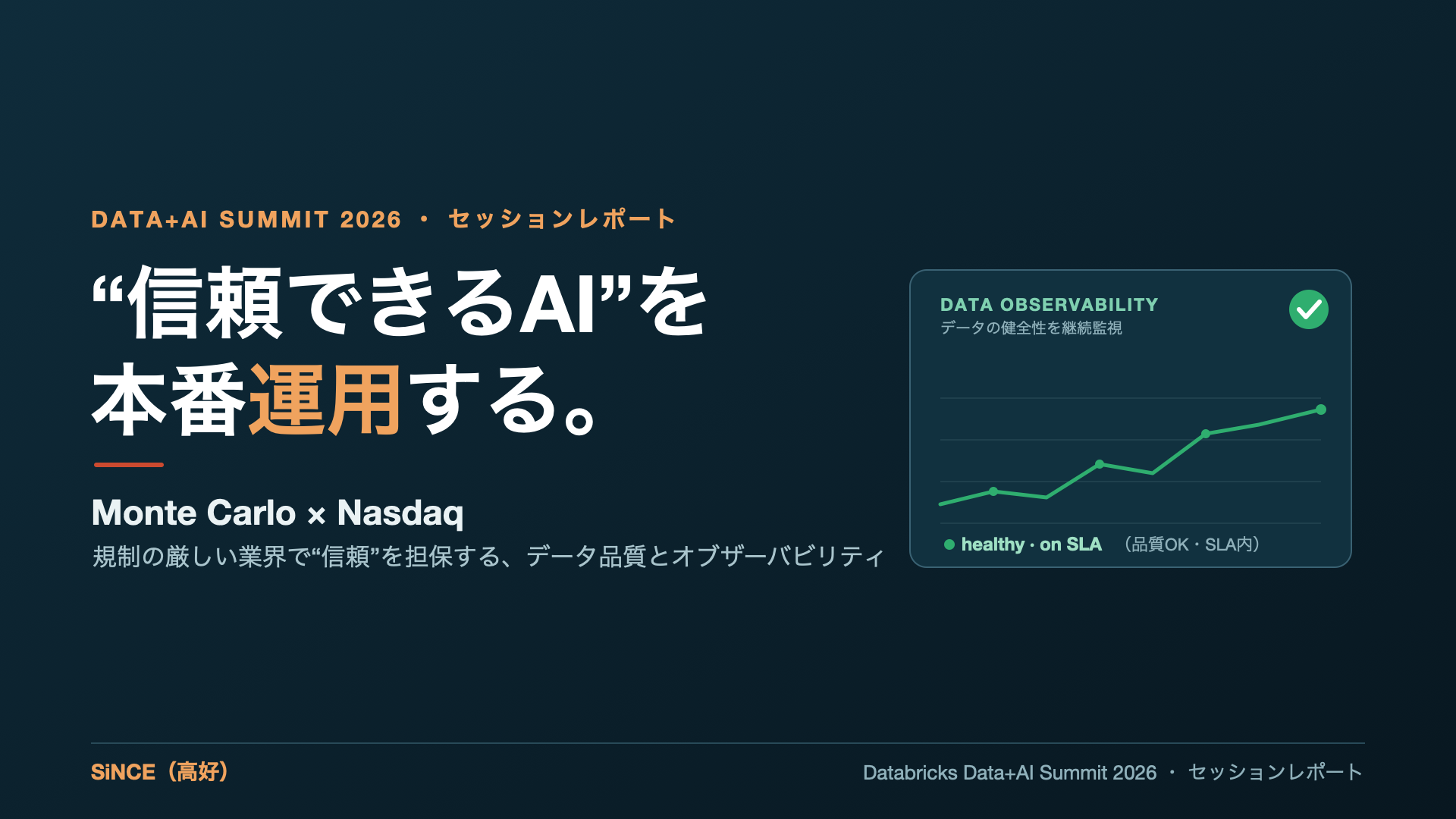
データ品質監視(データ・オブザーバビリティ)を手がけるMonte CarloのCEO Barr Moses氏と、証券取引所Nasdaqでデータ/ソフトウェアエンジニアリングを統括するLenny Rosenfeld氏が、「金融のように規制の厳しい業界で、AIを“信頼して本番運用できる”状態にするには何が必要か」をテーマに対談した。
AIへの不安と、人間・AIの役割分担
企業がAI導入に慎重になる主因は、「仕事を奪われる」という誤解と、「AIが出した結果の説明責任を誰が負うのか」という曖昧さにある。登壇者は、定型的・反復的な作業はAIに任せ、人間は付加価値の高い判断や問題解決に集中する、という役割分担を提案。「AIが仕事を奪う」のではなく「人が避けたい単調作業を引き取る」というフレーミングこそ普及の鍵だと指摘した。
実例:データ整備を自動化するエージェント(NasdaqのDMAP)
Nasdaqの「DMAP(データマッピング・エージェント)」は、新しいデータセットが入るたびにアナリストが毎回数分〜数時間かけていた“データの突き合わせ(マッピング)”を自動化する。延べ数百万時間規模の削減が見込めるという。ただし国際資産の税務処理のような複雑なビジネスロジックでは、最終判断は人間が担う設計を維持している。
規制業界でAIを本番化するための要点
- 段階的導入:PoC → プライベートプレビュー → パブリックプレビュー → GA(一般提供)と段階を踏み、いきなり全面展開しない。
- データの重要度(クリティカリティ)の見極め:機密性・重要度の高いデータほど慎重に扱う。
- 「Markdownファースト」でモデルを差し替え可能に:技術スタックは3ヶ月単位で入れ替わる(Bedrock・PGVector・LangChain・LangGraph・AI Gateway 等)。AIへの指示(コンテキスト)・ツール・スキルをMarkdown中心で管理し、基盤モデルを素早く載せ替えられるようにしておくことが、企業の中核資産(コアIP)になる。
- マルチエージェント構成:1つのエージェントに全コンテキストを持たせず、小さなエージェント群をオーケストレーション(指揮・連携)する。エージェントと各データプロダクトの接続には、MCP(Model Context Protocol=AIと外部ツールやデータをつなぐ共通インターフェース仕様)を用いる。
最大のリスクは「自信を持った誤答」
- AI最大の危険はハルシネーション(誤った内容を、もっともらしく自信を持って提示する現象)。
- さらにサイレント障害(コード変更や環境変化により、データ処理が“静かに”失敗し、気づけない)にも注意が必要。
- だからこそ本番運用では、インストルメンテーション(状態を計測可能にする計器づけ)とモニタリング/オブザーバビリティ(データの健全性を継続的に監視する仕組み)が不可欠。金融では、データ品質の失敗が「コンプライアンス違反・モデルへの不信・信用失墜」に直結する。
- Q&A型システムは、まず50〜100問の“模範解答集(ゴールドレコード)”を用意し、段階的にガードレール(逸脱を防ぐ制約)を増やすのが定石。
セキュリティ:AIにも「最小権限」を
人間に与えない権限(例:全データストレージへのフルアクセス)はAIエージェントにも与えない。「最小権限の原則」を、従来の情報セキュリティと同じ厳格さでAIにも適用する。
技術より難しい「文化変革」
Nasdaqはまずエンジニアから教育を始め、次にプロダクトチームへ展開している。AIは技術ツールであると同時に、組織の働き方を変えるチェンジマネジメント(変革推進)のツールでもある。登壇者の実践的助言は明快だった——「自宅の雑用をAIに頼んでみる」「社内で“業務の10%をAI化する”小規模プロジェクトを設ける」。個人が自分の業務でAIを試す経験の積み重ねが、組織全体の意識を変える。
持ち帰り:データ活用の現場視点
基調講演の「コンテキスト(企業固有の文脈)が最重要」という主張と完全に地続きの内容だった。すなわち「AIの土台はデータの品質と信頼性にある」。派手なモデル選定よりも、データを健全な状態に保ち、誰が何に使えるかを統制することこそが、規制業界での本番化の鍵となる。