こんにちは。
Databricks Data + AI Summit 2026(DAIS2026)現地レポート、第4弾です。今回取り上げるのは、共同創業者 兼 チーフアーキテクトである Reynold Xin 氏 のセッション。テーマは、これまで「バッチ寄りの分析基盤」というイメージが根強かったレイクハウスを、ミリ秒級のリアルタイム分析にまで引き上げる新機能 「Lakehouse//RT」 の発表でした。
正直に言うと、データベースの仕組みが好きな身としては、今回のSummitの中でも屈指の「ワクワクしたセッション」でした。単なる新機能の紹介ではなく、「なぜ今までこれができなかったのか」「業界はどんな”妥協”を当たり前として受け入れてきたのか」という前提から丁寧に解きほぐし、その妥協そのものを過去のものにしにいく——という構成だったからです。以下、現地で見た流れをそのままレポートしていきます。
データの世界を”宝の地図”でたどる
セッションは、いきなり製品の話から入るのではなく、ユニークな演出から始まりました。「The Known Data Realm(既知のデータ大陸)」 と題された、まるでRPGの世界地図のような”宝の地図”風スライド。ここに、OLTP・データウェアハウス・データサイエンス・データエンジニアリング・リアルタイム分析……といったデータ技術の各領域が、それぞれ「探索済みの土地」として描かれていきます。
地図というメタファーが秀逸なのは、「データの世界はすでに広く開拓されてきたが、まだ完全には繋がっていない大陸がある」という含意を、視覚的に一発で伝えてくる点です。各領域はこれまで別々に発展し、別々の専用ツールで支えられてきました。その”地図上の空白”や”分断された土地のつなぎ目”こそ、今回のセッションが照準を合わせるポイントなのだ——という伏線が、冒頭から張られていたわけです。
その流れを受けて、Reynold Xin 氏が登壇しました。

「最高のデータウェアハウスはレイクハウスである」
Xin 氏がまず強調したのは、レイクハウスがすでに DWH(データウェアハウス)として確固たる地位を築いている という事実です。「レイクハウスはデータサイエンス用」というかつてのイメージは、もう実態と合っていません。
具体的な数字として挙がったのが、Fortune 500 の60%以上が Databricks をウェアハウス用途で利用しているという点。さらに、Gartner Magic Quadrant や Forrester Wave といった第三者評価でもリーダーのポジションに位置づけられている、と。つまり「the best data warehouse is a lakehouse(最高のデータウェアハウスはレイクハウスである)」というメッセージは、もはやベンダーの主張というより、市場の評価として裏付けられている——という土台固めから入ったわけです。
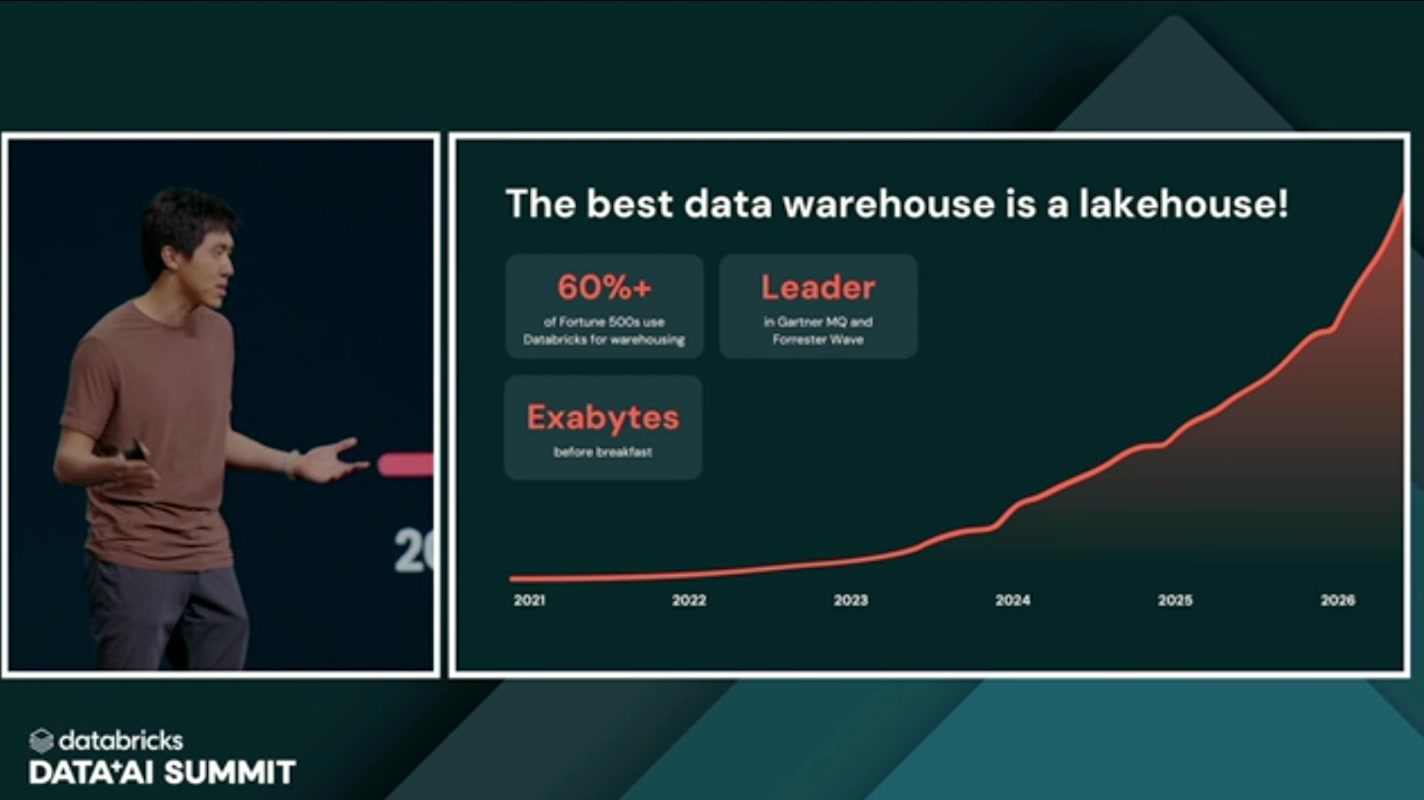
ここまでは「レイクハウスは強い」という、いわば順調な前振り。ところが、ここから話は一気に問題提起へと折り返していきます。
しかし「約1秒の壁」がある
どれだけクエリエンジンを高速化しても、従来型のウェアハウスは最終的に 「約1秒の壁(hit a wall at ~1 second)」 にぶつかる、と Xin 氏は指摘します。集計・JOIN・スキャンを徹底的に最適化しても、レイテンシは1秒前後で頭打ちになり、それ以上はなかなか縮まらない、という構造的な限界です。
バッチ的なレポーティングであれば、1秒は十分に速い。問題は、用途がそこに留まらなくなってきていることです。ユーザーが操作するたびに即座に反応してほしいインタラクティブなダッシュボード、エンドユーザー向けに数値を返すデータアプリ——こうしたリアルタイム用途では、この「1秒」が体感品質を決定的に損ないます。人は数百ミリ秒の遅延を「もたつき」として知覚するため、1秒は”許容できる範囲”ではなく”致命的な壁”になるわけです。
業界が受け入れてきた”当たり前”――なぜ二重持ちは高くつくのか
では、現場はこの壁をどう乗り越えてきたのか。Xin 氏が「Accepted wisdom: copy your data(データをコピーするのが常識)」と表現したのが、業界に広く根づいた回避策でした。
その構図はこうです。ウェアハウス(1〜2秒のレイテンシ)はそのまま据え置きつつ、リアルタイム配信専用のレイヤーを別途用意する。具体的には ClickHouse / Tableau Hyper / VertiPaq / Pinot といった、100ms未満の応答を狙える専用エンジンへ、同じデータをもう一度コピーして持たせる——というものです。
これは一見すると合理的な”使い分け”に見えますが、現場で運用してみると、なかなか手強いコストとして効いてきます。少しだけ、なぜこのパターンが高くつくのかを補足しておきます。
- データの二重持ちそのものがコストになる。同じ事実を2か所に保管するため、ストレージはもちろん、ETL/同期パイプラインの構築・維持コストがまるごと上乗せされます。
- 鮮度のズレ(整合性)という運用上の頭痛が生まれる。配信レイヤーへのコピーには必ずタイムラグが伴うため、「ウェアハウス上の数字」と「リアルタイムレイヤー上の数字」が食い違う瞬間が常に存在します。どちらが正なのかを巡る問い合わせ対応は、地味に体力を削ります。
- ガバナンスとセキュリティが分断する。アクセス権限・行レベル制御・監査ログといった統制を、複数のシステムに対して二重に設計・維持しなければなりません。コピー先が増えるほど、統制の抜け漏れリスクは積み上がっていきます。
- パイプラインが壊れやすい(fragile)。同期ジョブが一つ詰まれば配信レイヤーの鮮度が落ち、スキーマ変更のたびに連鎖的に修正が必要になります。アーキテクチャの可動部品が増えるほど、障害点も増えるという当たり前の帰結です。
つまり「コピーするのが常識」というのは、本来やりたくない妥協を、業界が長年「仕方ないもの」として飲み込んできた結果にほかならない——という整理です。

これに対して Xin 氏が投げかけたのが、セッションの核心をなす、シンプルかつ強烈な問いでした。
“What if your data never had to move?”
(もし、データを一切動かさなくてよかったら?)
データを別の場所へ引っ越させること自体が諸悪の根源なのだとしたら、引っ越しをやめてしまえばいい。問いの立て方そのものが、これまでの”常識”を根っこから疑うものになっていて、会場の空気がぐっと前のめりになったのが印象的でした。

データベース研究の蓄積から答えを出す
ここからが、いかにも Databricks らしい展開です。「データを動かさずにミリ秒で返す」という難題に対し、流行りのアーキテクチャ論ではなく、データベース研究の積み重ねから答えを導いていきます。
引き合いに出されたのが、チューリング賞受賞者である Stonebraker の名論文 「’One Size Fits All’: An Idea Whose Time Has Come and Gone」 などです。ここで整理された難題は、突き詰めると次の2点に集約されます。
- 1つのエンジンで全ワークロードを最適化するのは難しい。 トランザクション・大規模集計・低レイテンシ配信では、最適なデータ構造もアルゴリズムもまるで違う。万能の単一エンジンという発想自体に無理がある、という指摘です。
- 新しい最適化技術は結果が予測不能。 ある最適化を入れると、あるワークロードは速くなる一方で、別のワークロードはむしろ遅くなる——というトレードオフが頻繁に起きる。手動でチューニングし切るのは、もはや人間の手に負えない複雑さになっている、という現実です。

“エンジンの工場”――ML駆動のエンジン選択とは何を意味するのか
この難題に対する Databricks の回答が、膨大なワークロード履歴を学習し、適切なアルゴリズムとデータ構造をMLが自動で選び取る”データベースエンジンの工場(factory of database engines)” というアプローチでした。
学習の燃料となるのは、Databricks がプラットフォーム全体で蓄積してきた、文字通り桁違いの実行履歴です。スライドで示されたスケール感は、ゼタバイト規模のスキャン、京(quadrillion)単位の実行トレース、兆単位のクエリ。これだけの「実際に走ったクエリの履歴」があれば、どんなデータ分布・どんなアクセスパターンに対して、どのインデックス・どの並べ替え・どの圧縮・どの実行計画が効くのかを、経験則ではなくデータから学べる、というわけです。
ここで「ML駆動のエンジン選択」が何を意味するのかを、もう少し噛み砕いておきます。従来のチューニングは、人間(あるいは固定的なルールベースのオプティマイザ)が「このワークロードならこの構造が効くはず」と当て込む世界でした。Stonebraker の論文が突きつけたとおり、この当て込みは複雑化したワークロードの前で破綻します。これに対して”工場”のアプローチは、ワークロードの特性そのものを入力として受け取り、その都度ふさわしいエンジン構成を生成・選択する——いわば「単一の万能エンジンを作る」のではなく「ワークロードごとに最適なエンジンを量産するメタな仕組み」を作る、という発想の転換です。「One Size Fits All ではない」という指摘を、真正面から受けて立つ設計だと言えます。
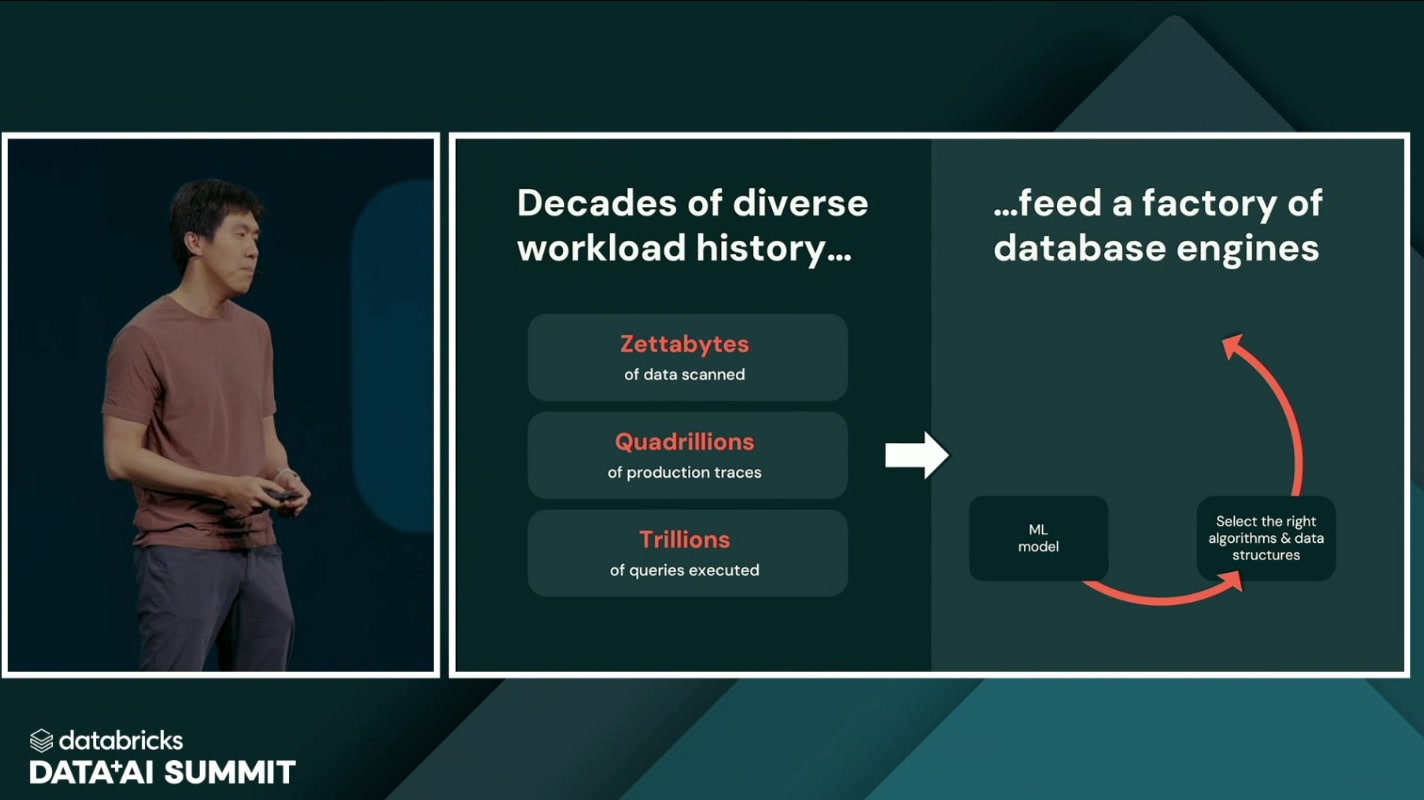
このML駆動の新しいSQLウェアハウスエンジン(スライド上の表記は “Reyden”。あくまでスライドに書かれていた呼称なので、正式名称かどうかはこのレポートの段階では断定しません)が、リアルタイム配信用の別スタックを丸ごと不要にする、というのがストーリーの帰結です。「データを動かさなくてよくなる」のは、レイクハウス上のエンジン自身が、配信レイヤーの仕事までこなせるだけの賢さと速さを手に入れたから——という筋立てになっています。
ベンチマークが圧巻
ここまでは設計思想の話。では、実際の性能はどうなのか。続くパートでは、具体的な数字が次々と提示されていきました。
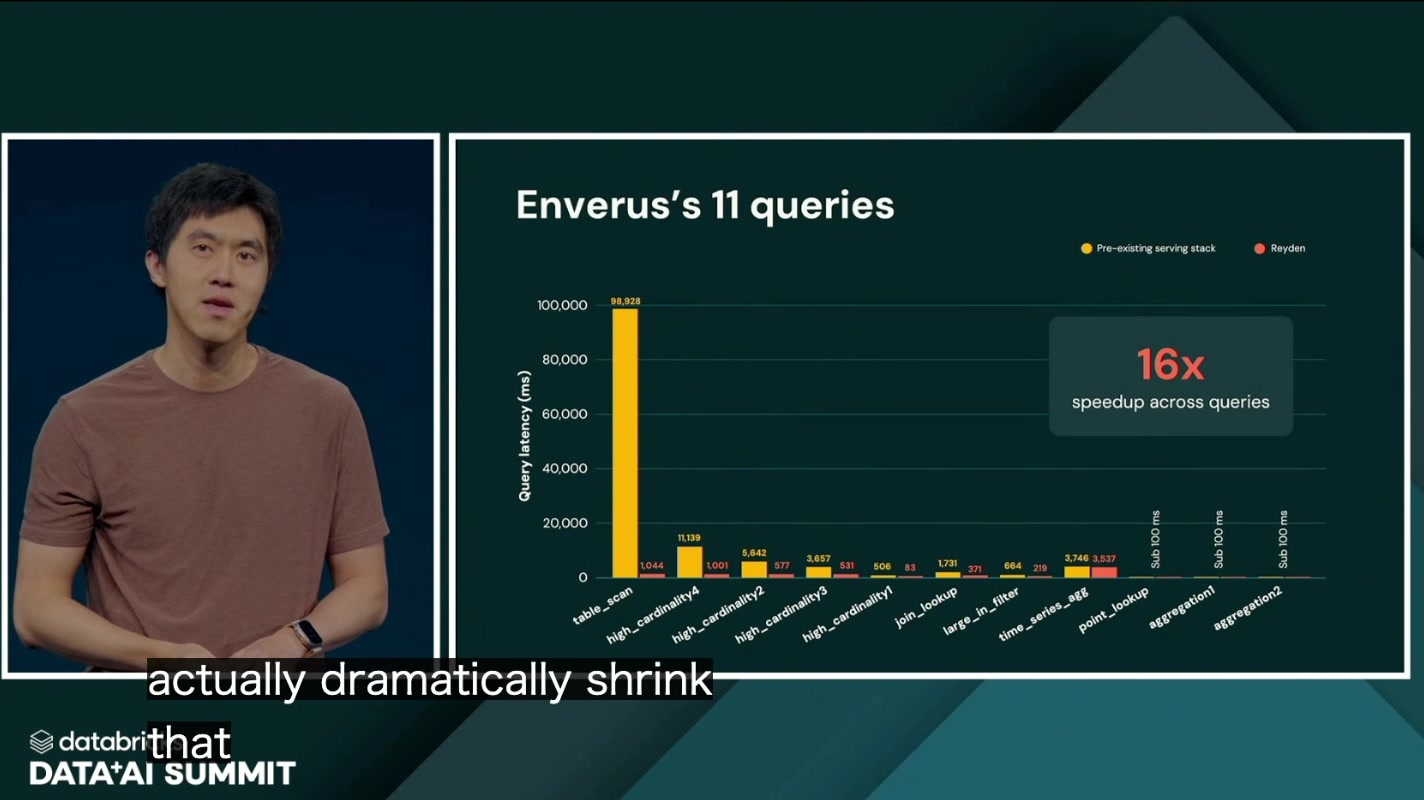
まず紹介されたのが、Enverus(エネルギー業界のデータ/AIプラットフォーム) の事例です。既存の配信スタックと比較して、16倍の高速化を達成したとのこと。「専用の配信エンジンに引っ越させてようやく出していた速度」を、引っ越しなしで、しかも桁違いに上回ってきた、という実ユーザーでの結果は説得力がありました。
そしてサマリーとして示されたのが、Best-in-class performance を裏付ける一連の数字です。
- 低レイテンシ:レイテンシは as low as 10 ms。冒頭で語られた「約1秒の壁」が、文字通り二桁ミリ秒の世界まで押し下げられています。
- 高い同時実行性:up to 12,000 QPS。少人数が眺めるダッシュボードではなく、大量のリクエストが同時に殺到する配信用途を正面から想定した数字です。
- 実ワークロードで最大100倍:理論値ではなく、実際のワークロードで 最大100倍 の改善。
- 複雑なEDWでもベストインクラス:低レイテンシ配信に振り切った結果、重たい分析が犠牲になるわけではなく、TPC-H / TPC-DS のような複雑なEDWワークロードでもベストインクラスを謳っています。
低レイテンシ・高同時実行・複雑な分析という、本来トレードオフになりがちな3つを同時に満たしにきている点が、まさに前段の「エンジンの工場」アプローチの成果として効いてくる構成になっていました。

「Lakehouse//RT」発表
そして、ここまでの伏線がすべて束ねられる本命の発表。Lakehouse//RT です。

打ち出された価値は、シンプルに3つ。
- Millisecond performance(ミリ秒の性能) ——「約1秒の壁」を越えた、ミリ秒級のレイテンシ。
- Massive concurrency(大規模な同時実行) ——大量の並行アクセスを捌ける同時実行性。
- Directly on your lake(データレイク上で直接) ——データをコピーせず、オープンフォーマットのまま、データレイク上で直接動かす。
要するに、「データをコピーして別のリアルタイムDBを立てる」必要がなくなる、という一点に尽きます。オープンフォーマットのデータレイクに対して直接、100ms未満のクエリを大量同時実行できる——前段で挙げた二重持ちのコスト・鮮度のズレ・ガバナンスの分断・パイプラインの脆さといった問題が、引っ越しをやめることで丸ごと消える、という構図です。
提供ステータスは Beta available。スライドには「Get early access today!(今すぐ早期アクセスを。担当アカウントチームへ)」とあり、すでに試せる段階に入っていることが示されていました。

まとめ
Lakehouse//RT は、「リアルタイムのためにデータを複製する」という長年の業界の常識を、正面から壊しにいく発表でした。冒頭の “What if your data never had to move?” という問いに対する、Databricks なりの明確な回答だったと思います。
改めて要点を整理すると——
- 約1秒の壁を越え、ミリ秒級のレイテンシと大規模同時実行を両立した
- 別のリアルタイムDBへデータをコピーせず、オープンフォーマットのレイクハウス上で直接動く
- その裏側は、ワークロード履歴を学習しML駆動で最適なエンジンを選ぶ”エンジンの工場”という仕組みで支えられている
所感
データベース屋として一番しびれたのは、課題設定の鋭さでした。「データの引っ越し」という、誰もが薄々「面倒だな」と思いながら受け入れてきた妥協を、はっきり”敵”として名指しし、Stonebraker の古典まで遡って「なぜ万能エンジンでは無理なのか」を論理で詰めたうえで、ML駆動のエンジン選択という現代的な答えにつなげる。流行りの言葉で押し切るのではなく、データベース研究の蓄積をきちんと踏み台にしている点に、Databricks らしさを強く感じました。
実務目線でも示唆は大きいと感じます。配信用に ClickHouse や Pinot 等の別スタックを抱えている現場は珍しくなく、その同期パイプラインの保守・鮮度ズレの説明・二重のガバナンス設計に、実際に少なくない工数を払っているはずです。もしそれが「レイクハウス上で直接」で置き換えられるなら、削れるのは単なるインフラ費だけでなく、運用チームの認知負荷そのものでもあります。
そして何より、ダッシュボードやデータアプリに加えて、エージェントが大量に並行アクセスしてくる「エージェント時代」のワークロードを、レイクハウス1つで支えにきた——という構えが象徴的でした。低レイテンシ × 大規模同時実行という Lakehouse//RT の性格は、まさにこれから来る負荷の形にぴたりと合っています。提供は Beta、早期アクセスを受付中とのことなので、リアルタイム用途を抱えている方は早めに触れておく価値があると思います。
次回は、トランザクション処理(OLTP)側の主役 Lakebase をレポートします。
参考リンク
*#DAIS2026 #Databricks #LakehouseRT #リアルタイム分析 #現地レポート*