
AutoMLとは、機械学習のプロセスを自動化する技術やフレームワークのことです。データの前処理、特徴量エンジニアリング、モデルの選定、パラメータチューニング、モデルの評価など従来、手動で行われた作業を効率的にかつ自動化して行うことが出来ます。DatabricksではAutoMLの機能が実装されており、データセットに機械学習を適用するプロセスを簡素化出来ます。今回のブログでは実際にDatabricks上でAutoMLを使用して機械学習モデルを作成し、結果を確認してみましょう。
はじめに
AutoMLとは、機械学習のプロセスを自動化する技術やフレームワークのことです。データの前処理、特徴量エンジニアリング、モデルの選定、パラメータチューニング、モデルの評価など従来、手動で行われた作業を効率的にかつ自動化して行うことが出来ます。DatabricksではAutoMLの機能が実装されており、データセットに機械学習を適用するプロセスを簡素化出来ます。今回のブログでは実際にDatabricks上でAutoMLを使用して機械学習モデルを作成し、結果を確認してみましょう。
使用データ
まず、今回使用するデータについて解説します。
今回使用するデータセットはKaggleの「Walmart Dataset」です。
このデータセットは米国の大手小売業者であるWalmartの売上データを含む、2010年2月5日から2012年11月1日までの時系列データセットです。各店舗ごとに売り上げが記載されており、気温など売り上げを予測する上で重要になりそうな特徴量が含まれています。なお含まれる特徴量は以下です。
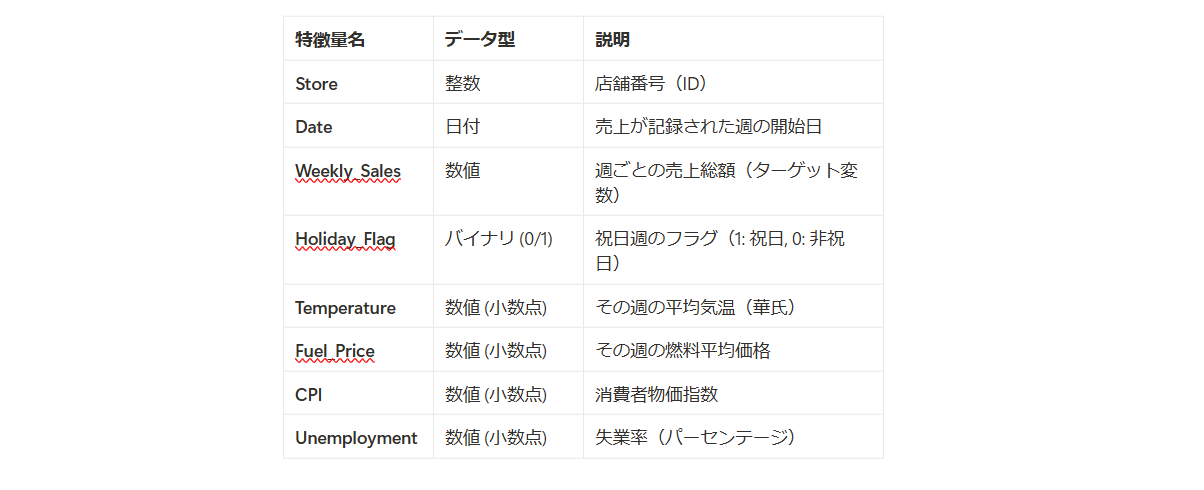
参考文献:
https://www.kaggle.com/datasets/yasserh/walmart-dataset
このデータは時系列データです。今回はこのデータに対して「Weekly_Sales」を8週間分予測してみましょう。
実験の開始
ではDatabricksでAutoMLによる機械学習モデルの作成及び、予測を行います。
AutoMLを使用したモデルの作成はUIベースのもの、ノートブックに直接コードを記載するコードベースのものがありますが今回はUIベースでモデルを作成します。
まず、Databricks上のエクスペリメントから予測を選びます。

予測ページに進み、予測に関する設定を行います。
使用学習データ、時間列、予測頻度、予測期間を入力します。
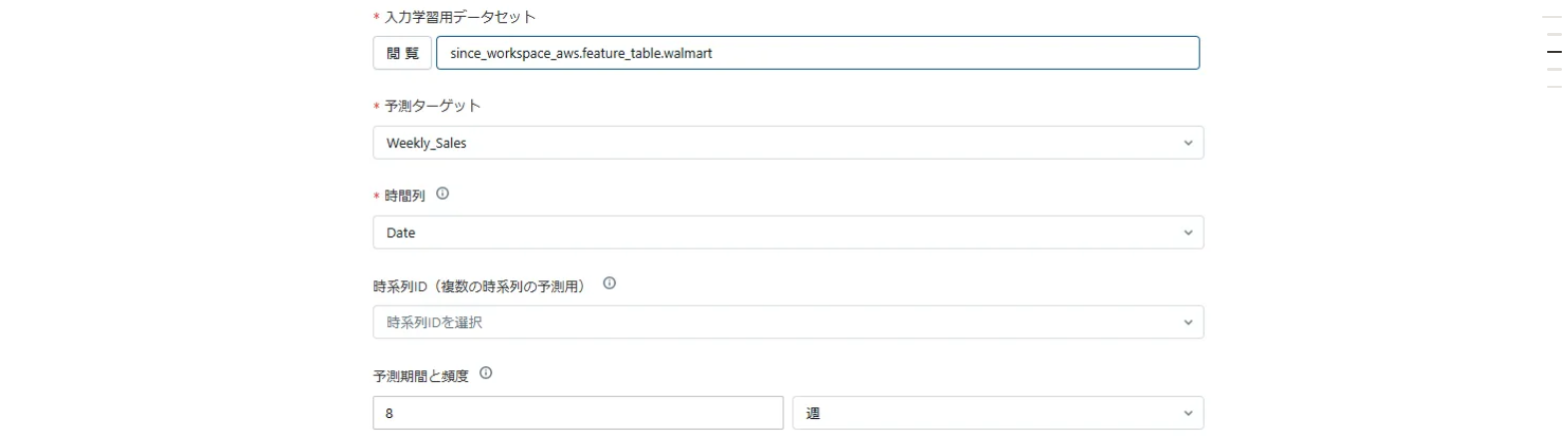
今回予測したいのは週間の売上なので、ターゲット列を「Weekly_Sales」
また、モデル作成そのものに関する設定も行います。
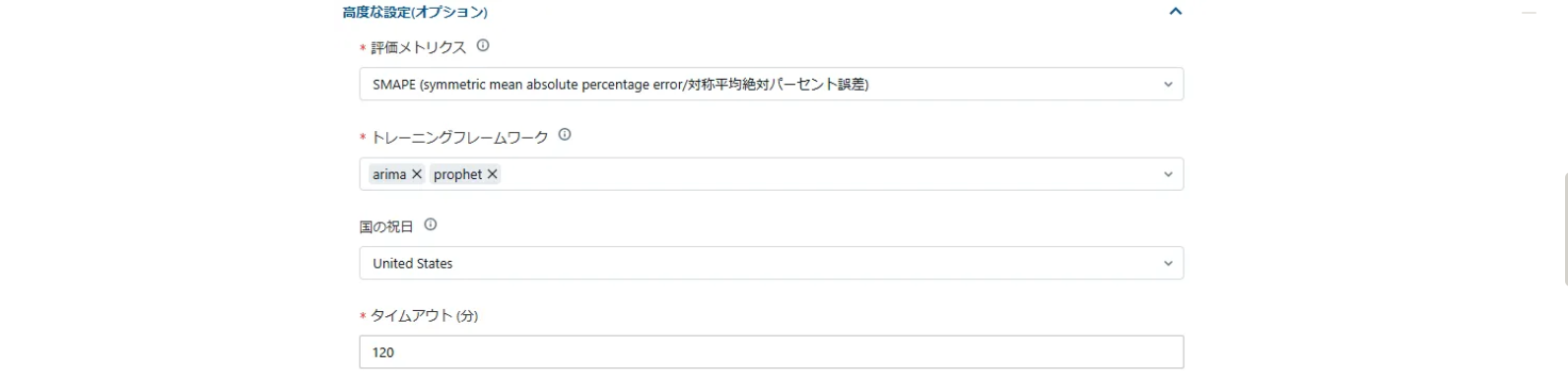
ここでは、モデルを評価する際のメトリクス、AutoMLで使用される機械学習アルゴリズムなどの設定を行います。
予測モデルには「ARIMA」「Prophet」「DeepAR」が使用され必要に応じて使用するアルゴリズムを選択できます。
また評価メトリクスには「平均絶対誤差」「平均絶対パーセント誤差」「平均二乗誤差」「二乗平均平方根誤差」「対称平均絶対パーセント誤差」があり、データセットに応じてユーザーが選択します。今回はデフォルトの「対称平均絶対パーセント誤差」を選択します。
このように設定しトレーニングを開始すると自動で実験が開始され、実験が終了次第、実験の結果を確認することが出来ます。
結果の確認
実験が完了すると以下のようなページを確認できます。

このページでは実験を行ったモデルの結果の確認、最適モデルのデプロイ、実際に実行したコードをノードブック形式などで確認できます。
今回の実験では
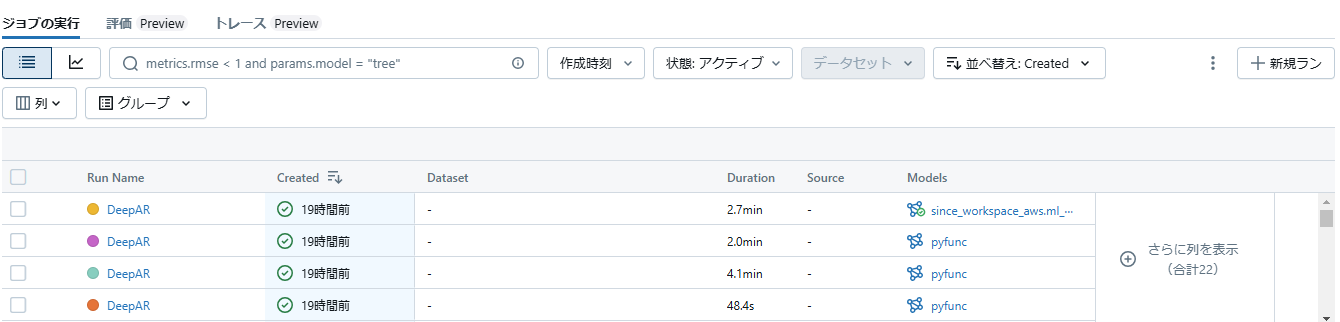
上記のように様々なrun(エクスペリメントの単位)を確認でき、最上位の「DeepAR」が評価の高いモデルとなっています。
最も評価の高いモデルの詳細を確認してみましょう。
モデルのページに遷移すると、使用したパラメータ、メトリクスの値などを確認することが出来ます。
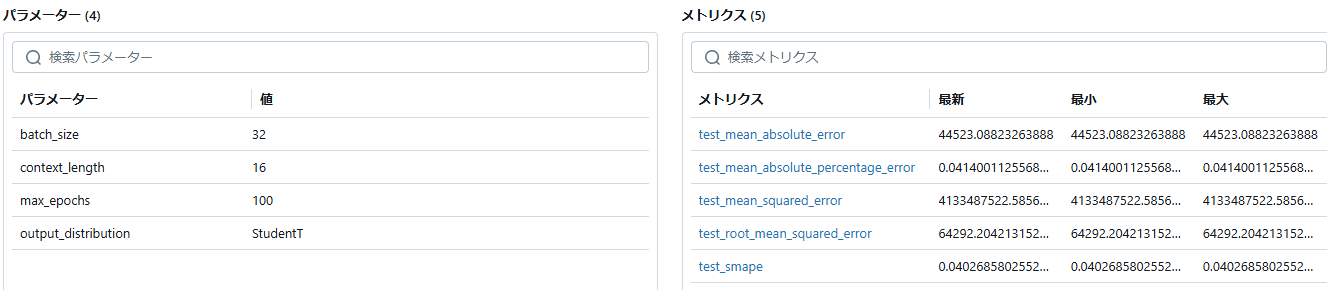
今回、最適モデルに使用するメトリクスは「smape」を用いましたがメトリクスには「smape」以外の項目も記載されています。なお、今回の最良モデルはsmapeが4%ほどであるので、高性能なモデルが作成されているといえます。
終わりに
今回はDatabricks上でAutoMLを使用し最も良いモデルに対する評価値を確認しました。実際にモデルを使用する場合は作成したモデルに対しての性能、評価に使用しなかったデータに対しても柔軟に対応できるモデルなのかなど確認するべき項目が多くあります。機械学習モデルを作成する際の一つの手段として使用すると良いと思います!









