
はじめに — 学びを“使える力”へ 現場で分析を回すと、最初にぶつかる壁はモデルづくりではなく“データの整える力”。なかでも欠損値への向き合い方は、分析の質を静かに左右します。2022年のKaggle調査では、データサイエンティストが作業時間の約20%を欠損や矛盾データの処理に費やすという結果も。地味に見えて、ここが勝負所です。 本稿では、欠損の考え方 → 代表的な対処 → Dataikuでの手順を、初学者目線で一気に整理します。読み終えたら、そのまま手が動くはず。
なぜ欠損値対応が重要か
- 分析の偏り:欠損の発生に傾きがあると結論が歪む
- モデルの学習停止・精度低下:多くのアルゴリズムは欠損を嫌う
- 検出力の低下:行ごと削るとサンプルが痩せて関係性を見落とす
実際にプロジェクトに参画して思うこと:
精度が伸びない原因の1つに前処理がまず挙げられます。欠損の見える化→理由→対処と段階を踏むだけで、モデルの精度が飛躍的に向上する。
欠損の仕組みを3分類で捉える(選ぶ手法の土台)
- MCAR(完全にランダム):紛失など完全偶然。バイアス小。行削除も許容。
- MAR(他の観測変数に依存):性別など別変数を条件にすると“ランダム”。条件付きの補完が筋。
- MNAR(値そのものに依存):症状が重いほど無回答など。最難。単純補完は過小評価の危険。設計レベルで追加データや仮定が必要。
代表的な対処法(短所もセットで理解)
3.1 行を削除(リストワイズ)- 速い・簡単。
- 代償:サンプル消失&MCARでないとバイアス。乱用注意。
- 平均:手軽。ただし外れ値に弱い。
- 中央値:外れ値に強い。数値の初手で安定。
- 最頻値:カテゴリ向け。“欠けていること自体に意味”がある場合は別設計(「不明」タグ化)も有効。
- KNN補完など。他特徴量から推定。
- メリット:関係性を活かせる。デメリット:計算コスト高/リークに注意。
よくある落とし穴:
目的変数や将来情報に触れた特徴で補完すると情報リーク。本番では学習用統計量のみで変換しましょう。
4.1 欠損の“見える化”
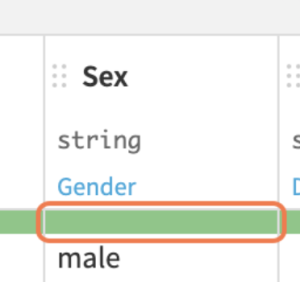
データセットを開くと各列ヘッダの品質バーが表示:緑=有効(その列に設定された“意味に値が適合している状態)
ただ、「Age」に関しては注意すべきのようです↓
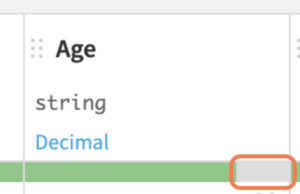
灰=「欠損あり」の状態なので、後ほど欠損値処理を行います。
そして、もう1つ、よくあるエラーです↓
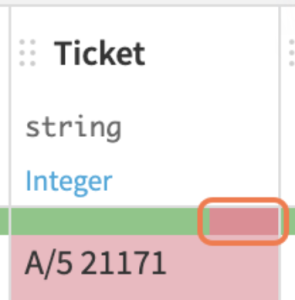
最後に赤色=無効(invalid)データがある(型に合わない値など)
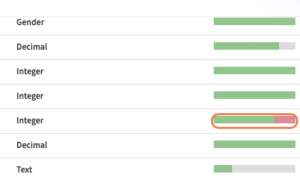
画面右上 「列」 を選択→ 欠損している項目が一発で分かります。
次にやること:欠損値がある項目を特定したので、欠損値を処理する(今回は平均値で埋める方法を実践してみたいと思います)。
Prepareレシピで処理しましょう(生データに直接は触らない)。
4.2 「Age」を平均で埋める
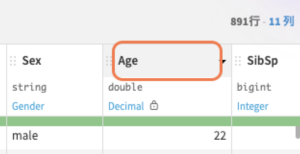
Age (欠損処理をしたい列)をクリックする。
そして、「データクレンジング」の項目に

「空の行を補充」をクリックする
- 方法=Average (Mean)を選択
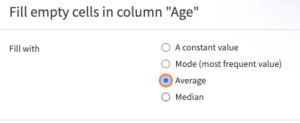
今回の場合は平均で埋めますが、欠損値の処理の仕方を場合によって選ぶことができる。「最頻値」「中央値」などで埋めることができる
「OK」を押して、欠損値が補充されたかを確認する
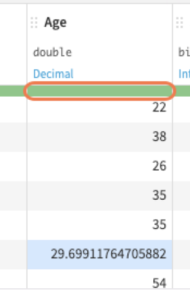
緑のバーが端まで表示されているの欠損値なしの状態です
実務Tip:
外れ値が多いときは Median(中央値) を選択。説明欄に「外れ値多→中央値」と一言メモ。
4.3 補充した「Age」の平均値を四捨五入して整数にする処理
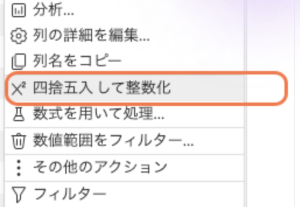
同じPrepareで「Age」を選択→ 「四捨五入して整数化」をクリック
※ここまでの欠損値処理は実際にはまだ完了していません。あくまでもプレビューなので、次のステップで欠損値処理を完了させます
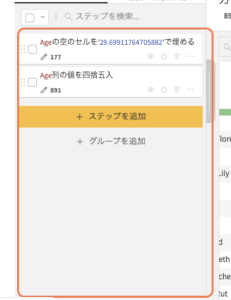
左の側の実行ステップを確認する
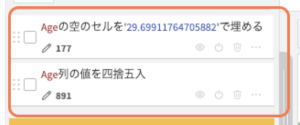
この2つの項目が今回の欠損値処理の内容です
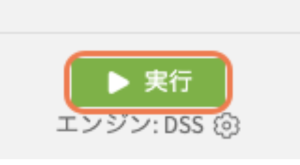
一番下の「実行」を押して
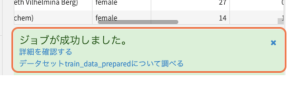
↑この表示が出れば、欠損値処理が完了
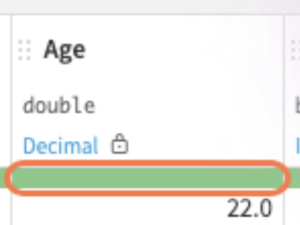
↑欠損値がない状態を示しています
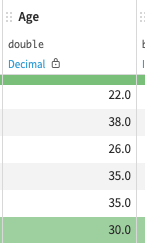
↑欠損値が「平均値」で補完されています
「Age」の欠損値が「平均値」で補完されたことが一目でわかります:
※左側の実行ステップは、最終的に「実行」をクリックすることで、上か順に実行される。
5. どの方法を“いつ”選ぶ?
- 欠損率:高すぎる列は列ごと削除するか検討or欠損フラグ化
- データ型:数値→平均/中央値、カテゴリ→最頻値/「不明」
- 外れ値:多いなら中央値
- 欠損機構:MNARの気配が強いなら、回収設計や補助変数を検討
- 再現性:学習/本番の同一トランスフォーム、統計量の学習データ固定
- 説明責任:なぜそう補完したか、1行メモを残す
まとめ — “整える力”がモデル精度改善へと繋がる
欠損値対応は、信頼できる結論と安定したモデルの土台です。Dataikuなら、可視化→意思決定→処理をノーコードで一気通貫。まずはPrepareレシピで小さく始め、判断のログを残す。これだけで前処理はチームの再現可能な“資産”になります。
データの海に出る準備は完了。次は実データで、あなたの現場に合った“欠損の作法”を育てていきましょう。
おまけ
分析力と実装力が0.1ずつ伸びました(気がしますw)
毎日、コツコツ伸ばしていきたいと思います!








