
今回は、Dataiku のシナリオ機能を用いてワークフロー(データパイプライン)を自動化し、定期実行するための手順を紹介します。特に「定期実行のスケジューリング」を例に、基本的な使い方や注意点をまとめました。Dataikuのプロジェクトで定期的なジョブの実行を行いたい場合に、ぜひ参考にしてください。
1. シナリオ(Scenario)とは?
Dataiku のシナリオ機能は、プロジェクト内のレシピやフローの実行・モニタリング・エラー通知など、一連の作業を自動化する仕組みです。複数のステップ(レシピの実行、コードの実行、メール通知など)をまとめて定義でき、以下のような場合に利用されます。
- 決まった時刻・周期ごとにフローを自動実行したい
- データが一定の更新条件を満たしたら処理を行いたい
- エラーが発生したときに通知・停止・再実行などを制御したい
このシナリオを活用することで、手動でフローを実行する手間が減り、ヒューマンエラーの防止や分析サイクルの高速化につながります。
2. シナリオを作成する手順
2.1 シナリオの新規作成1.プロジェクトにアクセス
Dataiku にログインし、対象のプロジェクトへ移動します。
2.[Scenarios] タブを開く
上部のメニューもしくは左メニューにある [Scenarios] をクリックします。
3.[+ New Scenario] ボタンを押下
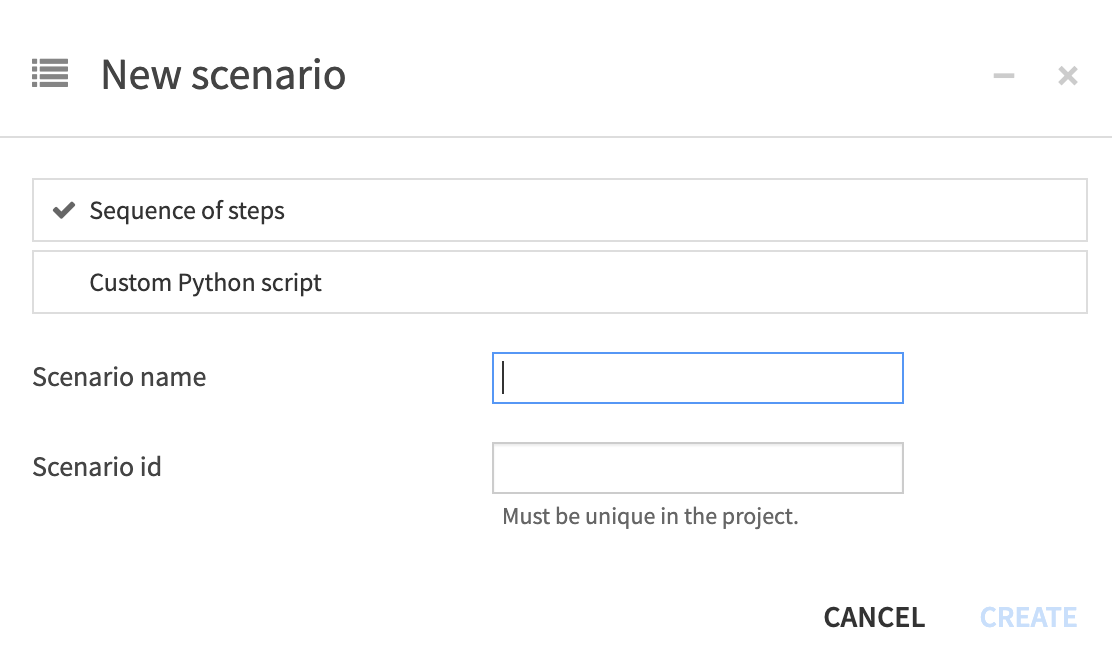
新規シナリオ作成ウィザードが立ち上がるので、シナリオ名を分かりやすく設定します。
2.2 シナリオの編集画面シナリオの編集画面では、「Triggers(トリガー)」や「Steps(ステップ)」を設定できます。トリガーによってシナリオの実行タイミングを制御し、ステップによって実際に行う処理を定義します。
1.Scenario Name
シナリオの名称・説明を設定できます。後から変更も可能です。
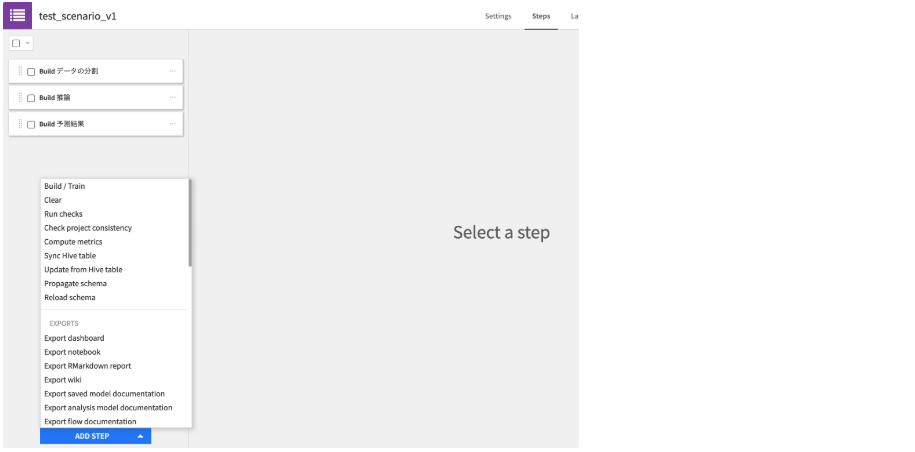
2.Steps(ステップ
「実際に何をするか」を定義します。以下のように、さまざまなアクションがあらかじめ用意されています。
3. 定期実行(スケジューリング)の詳細設定
3.1 Time-based Triggerの追加1.シナリオ編集画面の左メニューから Triggers を選択
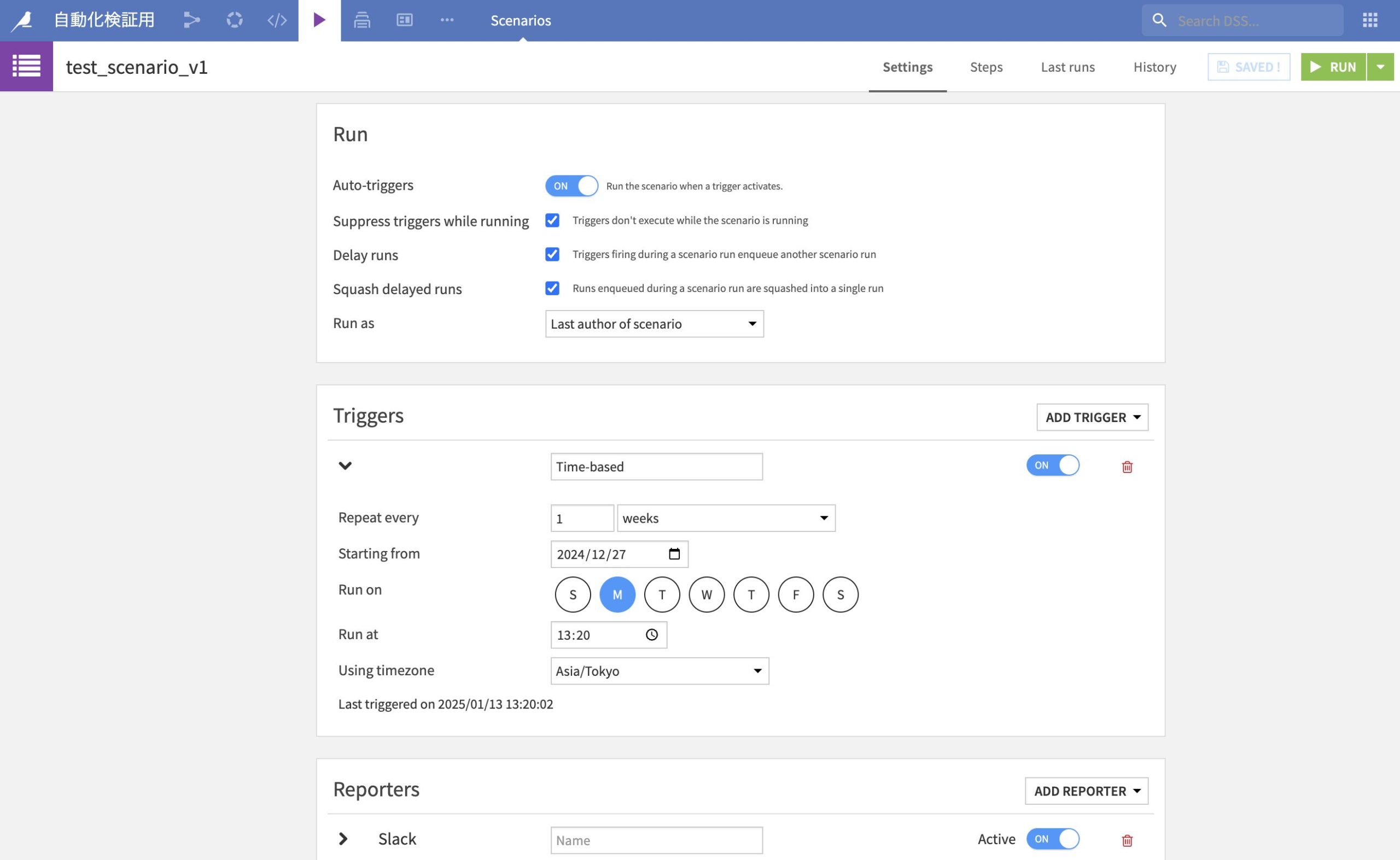
「いつ実行させるか」を設定します。主に以下の種類があります。
-
- Time-based(定時実行・スケジューリング)
- Build Dataset(特定のデータセットのビルドが完了したタイミング)
- Custom Python trigger(Pythonコードによる独自条件)
- その他、フィルターベース(データの増分など) 今回は Time-based(時間ベースのスケジュール)を設定します。
2.[+ Add Trigger] ボタンを押し、Time-based を選択
3.実行スケジュールをCron形式、またはウィザード形式で設定
-
- Cron:
0 2 * * *というような形式(例:毎日02:00に実行) - Repeat every:インターバルを分・時間単位などで指定,
- [SAVED] をクリックし、設定を保存
- Cron:
1.シナリオ編集画面の左メニューから Steps を選択
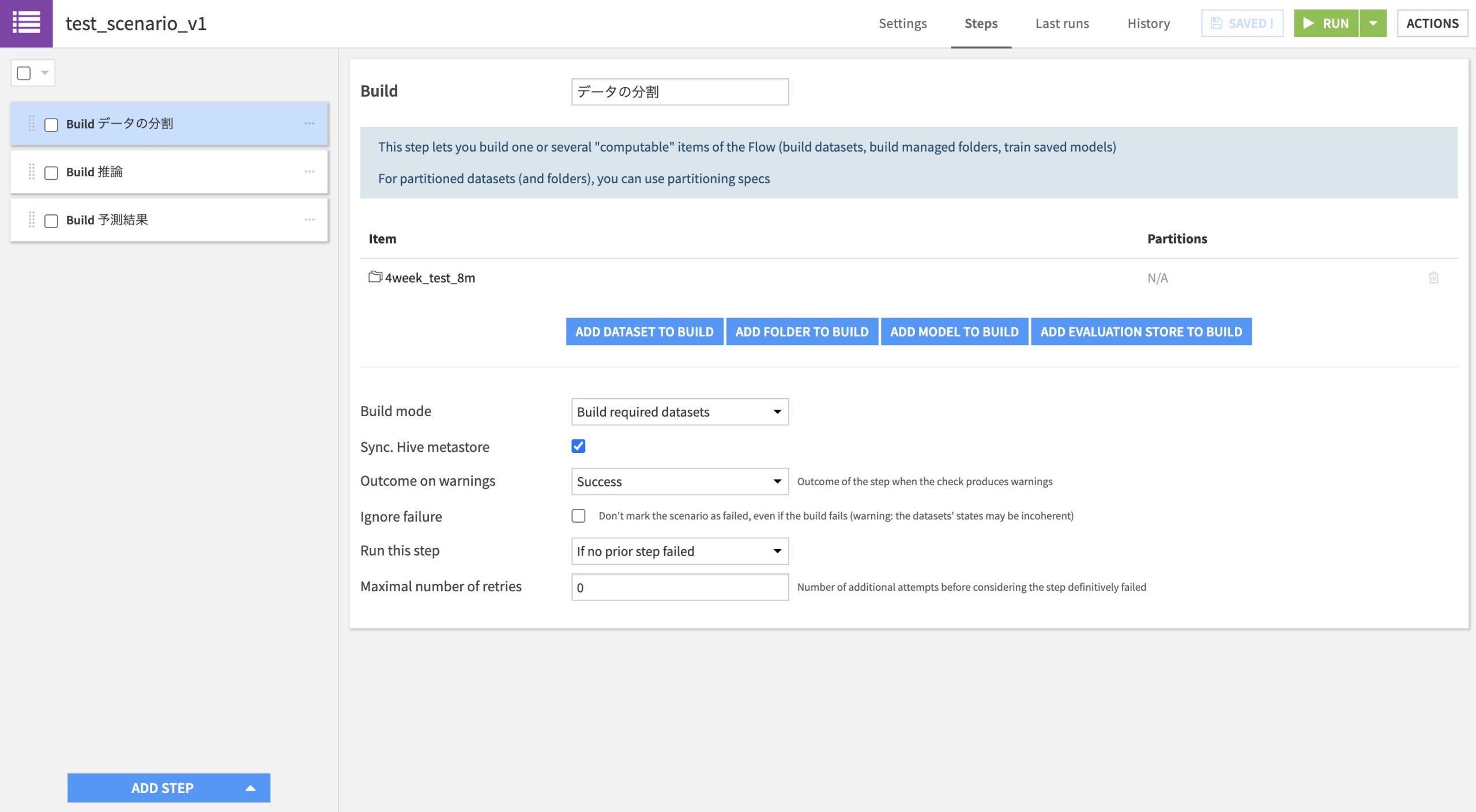
2.[+ Add Step] ボタンを押す
3.実行したい処理を選択(Build/Refresh dataset、Run recipe など)
4.対象のデータセットやレシピ、実行オプション(フロー全体の再ビルド、依存関係の再構築など)を設定
5.必要に応じてステップを追加し、処理を順番に整理
3.3 エラー処理・通知の設定1.[Scenario Settings] -> [Reporters] からエラー時の挙動を選択
-
-
エラー時にシナリオを停止する
-
エラー発生箇所をスキップして残りのステップを実行する
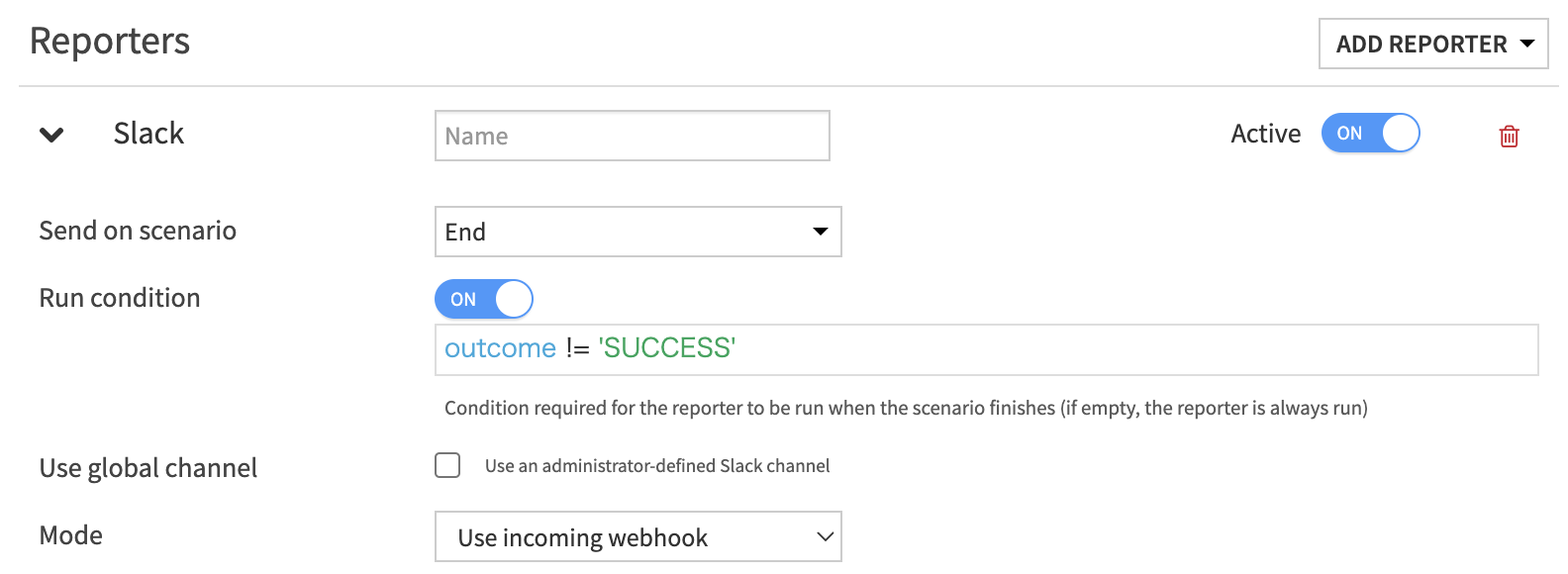
[Scenario Settings] -> [ADD REPOTER] からSlackを設定
- シナリオが成功/失敗した際に通知を送る
-
4. シナリオのテストと実行
4.1 シナリオのテスト実行シナリオ編集画面の右上にある [Run] ボタンや [Test Run] ボタンから、設定したステップが正しく動作するかをテストできます。実際にスケジュールされたタイミングを待たずに手動で試せるため、設定ミスや依存関係エラーの早期発見に有用です。
4.2 実行結果の確認シナリオ一覧画面やシナリオのログを確認し、実行結果のステータス(成功/失敗)、詳細メッセージ、実行時間などをモニタリングします。問題があればログを参考に原因を調査し、シナリオのステップ設定を修正しましょう。
5. 運用・管理のポイント
-
スケジュール管理
複数のシナリオを運用する際は、同じ時刻に実行が集中しないよう調整が必要です。また、インフラリソースを考慮したうえで、実行時間帯を工夫するとパフォーマンスの低下を防げます。
-
ステップの再利用
一度作成したシナリオをコピーし、ステップの一部だけ修正して流用することで、新しい分析フローへの転用が簡単になります。
-
失敗時の通知と再実行
定期実行では失敗時に気付くのが遅れるリスクがあります。通知設定を細かく行い、失敗した際には早めに対処できる仕組みを整えると安心です。
-
ログ・監視体制
定期実行ジョブが急に遅くなる、失敗が続く、などの異常をいち早くキャッチするために、シナリオログやDataikuの監視機能(Automation Monitoring)を有効活用しましょう。

まとめ
本記事では、Dataiku のシナリオ機能を使ってワークフロー(データパイプライン)を自動化し、定期実行を設定する手順を紹介しました。データ処理や分析フローを決まった時刻に実行し、自動でレポートや通知を送ることで、運用コストを削減し分析に集中できる環境を作れます。
DataikuはGUIが充実しているため、ノンコーディングでも柔軟にシナリオの実行条件やステップを設定可能です。高度な要件がある場合には、Pythonスクリプトなどのカスタムステップと組み合わせることで、より複雑な自動化や高度なエラーハンドリングを実現できます。
今後さらに業務が拡大しても、シナリオを複数作り分け、依存関係や実行条件を整理すればスケーラブルな分析基盤として運用できます。ぜひプロジェクトで活用し、分析効率の向上に役立ててください。a










