来場3万人を超えたData + AI Summit 2026。基調講演を貫いていたのは「AIはもう十分賢い。足りないのは、自社固有の文脈(コンテキスト)だ」という主張だった。では、その文脈をAIにどう渡すのか。前提として欠かせないのが、社内の知識を「意味の地図」として整えるオントロジー。ただ、その地図が力を発揮するには、もっと手前の条件がある。社内の全データが、ちゃんと集まっていること。
ここが意外と難所だ。多くの現場で、データの取り込みは「パイプライン」と「加工ツール」の寄せ集めになっている。あちこちから配管を引き、途中で何度も道具を持ち替える。つなぎ目だらけの仕組みは、動かすのも、守るのも、誰がどこに触れたか統制するのも重い。

Summit で打ち出された答えが、データの取り込みから加工、段取りまでを一本につなぐ「Lakeflow」。AI に良質な文脈を供給するための、足元を整える装置。そう捉えると分かりやすい。
なぜ「取り込み」はこんなに複雑なのか
従来のデータ基盤は、役割ごとに別々の道具を継ぎ足してできていた。データを流す配管にKafka。流れてきたデータを加工するFlink。最終的に分析しやすい形に整えるdbt。そして全体の順番を仕切る段取り役のAirflow。それぞれ優秀だが、4つも5つも噛み合わせると、つなぎ目が増える。
つなぎ目が増えると何が起きるか。ひとつ仕様が変わるたびに複数の道具を直す。障害が出れば、どこで詰まったかを道具をまたいで追う。誰がどのデータに触れているかの管理も、道具ごとにバラバラになる。経営の言葉に直せば、運用コストがふくらみ、特定の担当者しか触れない属人化が進む。「作る」より「維持する」方に人手を取られていく構図だ。

上の図がまさにそれ。左にあるのは、メッセージキュー、業務アプリ、データベース、非構造化データ、クラウドストレージ。種類のまったく違うデータの入り口だ。これを一つひとつ別の配管でつなぐから、絵が枝分かれだらけになる。Lakeflow は、この入り口の混雑を「Connect(つなぐ)」の一語に畳み込もうとしている。
取り込みをシンプルに——Lakeflow と Zerobus
Lakeflow の取り込みは、用意されたコネクタで多様なデータ源に直接つなぐ。SaaS のアプリも、工場の設備(IoT)から絶え間なく届くデータも、その場でレイク(データの貯蔵庫)へ流し込む。コネクタは100以上。自作の配管を一本ずつ書く時代は、もう終わりに近い。既製の差込口を選んでつなぐ。それだけだ。
絶え間なく届くデータには「Zerobus」が効く。途切れず流れてくるデータの流れ(ストリーム)を、遅れを抑えてそのまま取り込む仕組みで、取り込み速度は接続あたり最大で毎秒100MB級。センサーやログのように止まらず来るデータを、いったん貯めてから一括処理するのでなく、来た端から飲み込んでいく。そんなイメージだ。
ここで覚えておきたいのは、速さや量そのものより「入り口が一本化される」点。取り込みの間口がそろうと、後工程の整え方も、統制のかけ方もそろう。バラバラだった配管を一本に束ねることが、維持の軽さに直結する。
加工をひとつに——Spark Declarative Pipelines
集めた次は、使える形に整える「変換」。ここも従来はツールが分かれていた。たまった分をまとめて一括処理するバッチ、流れながらその場で処理するストリーミング。書く言語も SQL 派と Python 派で割れる。Lakeflow はこれを「Spark Declarative Pipelines」という一つの土台に集約した。

「Declarative(宣言的)」とは、手順を一つずつ指示するのでなく「こういう結果が欲しい」とだけ書けば、中身の段取りは基盤側が組んでくれる、という意味。バッチもストリーミングも、SQL も Python も、さらに遅れを極力抑えて処理する Real-Time Mode も、同じ土台の上で扱える。道具の持ち替えが、ここで消える。
道具を一本化すると、整形のルールも一箇所に集まる。仕様変更のたびに複数のツールを直す手間が消え、どのデータがどう加工されたかも追いやすくなる。
しかも、書くのにコードがいらない選択肢もある。
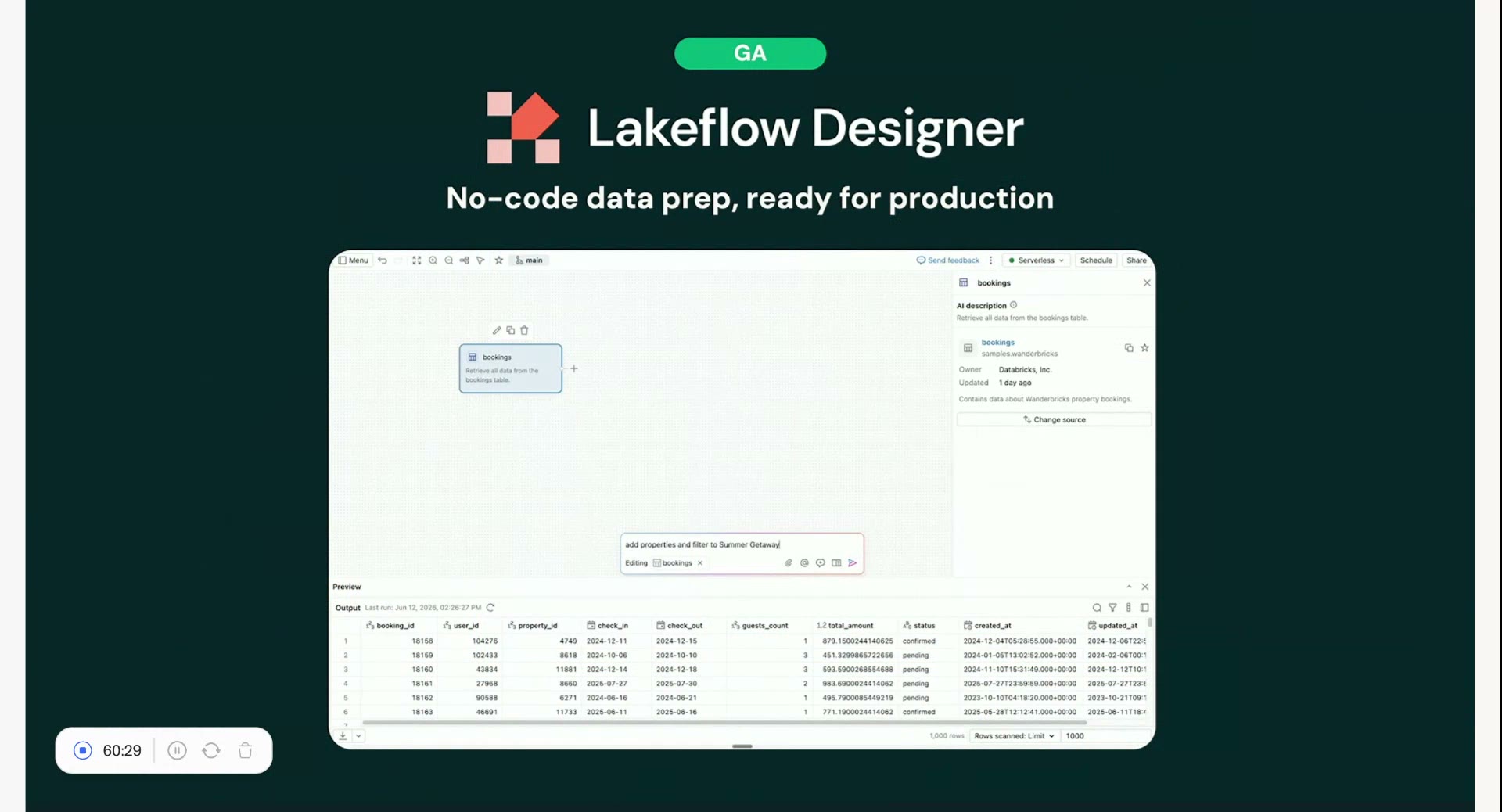
ノーコードの「Lakeflow Designer」は、画面上で部品をつなぐように加工の流れを組める。Summitのデモでは、自然言語で「項目を足して絞り込みを追加して」と打つだけで、出力テーブルがその場でプレビューされた。GA(正式提供)として発表されている。これまでデータエンジニアに頼むしかなかった整形作業の一部を、現場の担当者が自分の言葉で進められるようになる。

この土台の実力は、規模の数字に出ている。Spark Declarative Pipelines(SDP)が日々さばくのは、1日あたり200兆行。ジョブの実行は月に17億回。さらに顧客の半数は、サーバーレス(自前でサーバーを管理せず、使った分だけ動かす形)で動かしている。
数字の大きさに圧倒される必要はない。要点は別にある。すでに本番の重い負荷で回っている土台だ、という事実だ。実験段階のツールではなく、日々の業務がこの上で動いている。
段取りも束ねる——既存を捨てさせない
加工の次は、いつ・どの順で動かすかという段取り(オーケストレーション)。ここでも既存の Airflow 系と50以上の統合が用意され、別物に乗り換えなくても束ねられる。今あるものを捨てさせず、上から束ねる。この姿勢は、基調講演を通して一貫していた。
土台のデータ形式には Apache Iceberg というオープンな形式を採用。特定ベンダーの倉庫に閉じ込めず、形式をオープンに保つことで、後から別の道具に乗り換える自由を残す。ロックイン(囲い込み)を避ける、という考え方だ。集めて整える段階で囲い込まれてしまうと、その先の AI 活用まで身動きが取れなくなる。手前で逃げ道を断たない設計、と言い換えてもいい。
パイプラインを「AIが書く」時代へ
そして、この整える作業そのものを、AI が担い始めている。自律的にパイプラインを組む「Genie Code」は、Lakeflow のパイプラインの60%を、わずか3ヶ月で生成したという。
パイプライン構築は、長らく熟練のデータエンジニアの手仕事だった。それを AI が下書きし、人が確かめて仕上げる。データを集めて整えるという、地味だが欠かせない工程が、人手の総量から少しずつ解き放たれつつある。
押さえどころ
オントロジー(意味の地図)や Genie のような AI の同僚が華やかに見えても、それらが「根拠のある答え」を返せるかどうかは、もっと手前で決まっている。良質な文脈の元になるのは、社内のあちこちに散らばったデータ。それが滞りなく集まり、きれいに整い、誰が触れたか分かる状態になっているか。勝負は、そこだ。
問い直すべきは、こうだ。自社のデータは、AIに渡せる状態まで「集まって、整って」いるか。それとも、つなぎ目だらけの配管の維持に、いまも人手を取られ続けているか。派手なモデル選びの前に、足元を整えることが効いてくる。
関連:生成AIに「自社の文脈」を渡すサービス「Ontology Boost」
Lakeflowで足元のデータを集めて整えるのは手段であって、目的は「AIに自社の文脈を渡す」こと——これは、私たちSiNCEが提供を開始したサービス 「Ontology Boost」 がまさに取り組む領域です。生成AI(ChatGPT・Claude・Geminiなど)が、御社固有の用語・KPI・業務ルールに沿って”根拠のある”回答を返せるよう、知識基盤(オントロジー)の構築・接続・運用までを一貫支援します。