こんにちは。
サンフランシスコ・Moscone Center で開催された Databricks Data + AI Summit 2026(以下、DAIS2026) に参加してきました。データ/AI に携わる人間にとっては年に一度の”お祭り”であり、世界最大級の規模を誇るこのカンファレンス。会場に足を踏み入れた瞬間から、登録カウンターの長蛇の列、Expo Hall を埋め尽くすパートナー企業のブース、そこかしこで交わされる技術談義と、とにかく熱量がすごい。本記事はその Day 1 キーノート(基調講演)を、新機能発表の速報を交えながらお届けする現地レポートの第1弾です。
発表があまりに盛りだくさんだったため、テーマごとに記事を分けてシリーズでお届けします。本記事はその全体像をつかむ「総括編」であり、各記事へのインデックスも兼ねています。「まずここだけ読めば全体の流れがわかる」という構成を目指しました。
登壇したのは Ali Ghodsi 氏(共同創業者 & CEO)
開演時刻になると客電が落ち、大型スクリーンにシネマティックなオープニング映像が流れ始めます。高速で切り替わるコード、ダッシュボード、現場で働く人々の映像に、「show it what’s real. Real is every decision.(本物を見せろ。本物とはあらゆる意思決定のことだ)」「The real breakthrough is what you build with it.(本当のブレイクスルーは、それで”何を作るか”だ)」といったメッセージが重なり、会場のボルテージが一気に上がります。
そして拍手に包まれてステージに登場したのが、共同創業者 兼 CEO の Ali Ghodsi 氏。毎年このキーノートの口火を切る、Databricks の顔とも言える人物です。

※ステージのスクリーン(タイトルカード)の表記どおり、正しくは Ali Ghodsi です。
まずは規模感 — 100,000人・174カ国超という熱狂
Ghodsi 氏はまず、このサミットそのもののスケールを紹介するところから始めました。スクリーンに映し出された数字は、年々過去最高を更新し続けています。

- 100,000 参加者(バーチャル参加を含む)
- 800+ セッション/ハンズオントレーニング
- 174+ カ国からの参加
- 240+ 出展者・スポンサー
- 350+ 顧客による事例セッション
単なる製品発表会ではなく、世界中のデータ/AI 実務者が一堂に会する”業界の総会”のような場になっていることが、この数字からも伝わってきます。
さらに Ghodsi 氏は、Databricks を支えるエコシステムの広がりにも言及しました。20,000社の顧客が Databricks を採用し、そのうち Fortune 500 の 75% が利用しているとのこと。スクリーンには名だたるグローバル企業のロゴが一面に並びました。

加えて、オープンソースとしての影響力の大きさも強調されました。Apache Spark は年間30億回超、Delta Lake は20億回超、Apache Iceberg は5億回超、MLflow は4億回超というダウンロード規模。さらに Unity Catalog のオープンソース化(2025年)、PostgreSQL への積極的なコミット(2025年以降315コミット)、先週オープンソース化されたばかりの「Omnigent」など、”作って終わり”ではなく標準そのものを作りにいく姿勢が示されました。そして 8,200を超えるパートナーエコシステム(System Integrators / Built-On / Connected / Data Sharing の4カテゴリ。Anthropic、NVIDIA、OpenAI、SAP、Accenture、Deloitte など)。プラットフォームとしての土台の厚さを、これでもかと印象づける立ち上がりでした。
キーメッセージ「AGIはすでにここにある」
スケール紹介で会場を温めたあと、Ghodsi 氏は今年の基調講演を貫く一つのテーゼを掲げます。それが “AGI is here today”(AGIはすでにここにある) でした。
ここで引き合いに出されたのが、「Humanity’s Last Exam(人類最後の試験)」と呼ばれる超難問ベンチマークです。スクリーンには、専門家でも頭を抱えるような数学・物理の難問(スピン・ボルディズムや例外型リー群 G2 に関する設問)が一例として映し出され、「これを解けるのは誰か?」と問いかけます。そして、このベンチマークに対する AI のスコアが、GPT-4o → Gemini 2.5 Pro → GPT-5 → Gemini 3 Pro → Opus 4.7 → Fable 5 と、ごく短期間で右肩上がりに急上昇している様子がグラフで示されました。

Ghodsi 氏の主張は明快です。「もはやモデルが賢いかどうかは論点ではない」。モデルの能力は十分に高い水準に達した。だからこそ、エンタープライズが向き合うべき本当の課題は、まったく別のところにある——という流れで、講演は本題へと入っていきます。
なお、講演の随所では具体的な顧客事例も紹介されました。ウェアラブル端末(持続血糖モニターなど)のデータから一人ひとりに最適化した運動・食事を提案するヘルスケアの事例や、Merck のゲノム解析・創薬(「どの遺伝子が効くかを予測する」)の事例など、データ × AI が実世界のインパクトに直結している様子が、抽象論ではなく具体例で語られたのが印象的でした。
立ちはだかる2つの課題 —「データへの接続」と「コスト」
では、その”本当の課題”とは何か。Ghodsi 氏が挙げたのは、次の2つでした。これがこの後に続くすべての製品発表を貫く伏線になります。
課題1:AIを自社データに接続するのは難しい(Connecting AI to data is difficult)
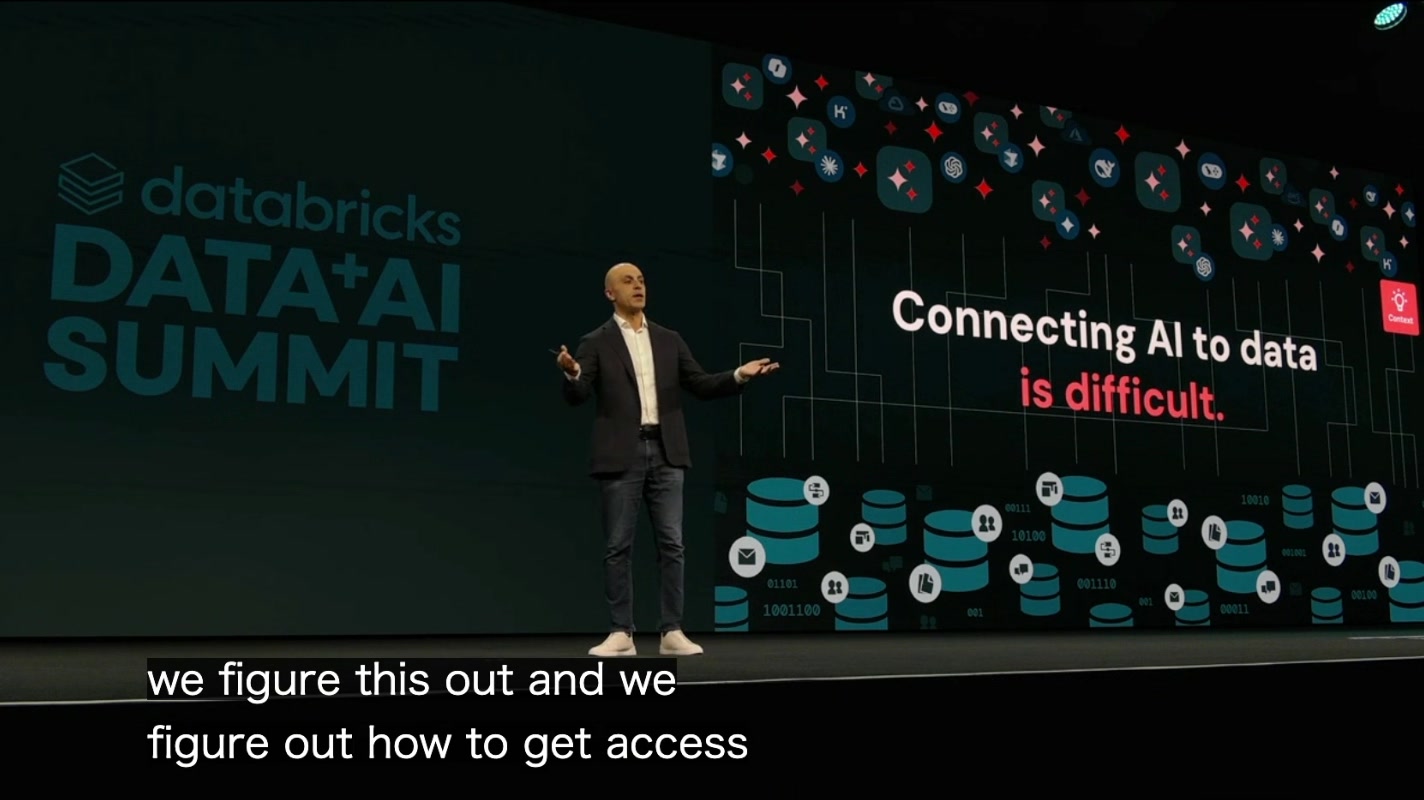
どれだけ賢いモデルでも、自社に散らばったサイロ化データや業務コンテキストに正しくつながらなければ、現実の業務では使い物にならない。「賢いモデル」と「使えるAI」の間には深い溝がある、という問題提起です。後の Genie One(第2回)の発表は、まさにこの溝を埋める話になります。
課題2:コスト管理はもっと難しい(Managing cost is harder)

そしてもう一つが、コスト。エージェントが自律的にループしながら大量のトークンを消費し、気づけば請求額が青天井——という「エージェント時代」ならではの新しい痛みです。性能を出すこととコストを抑えることのトレードオフをどう解くか。後の Unity AI Gateway(第6回)や Lakebase の scale-to-zero(第5回)といった発表は、この課題への回答として位置づけられます。
この2つの課題を、単発の機能ではなくプラットフォーム全体でどう解いていくのか——それが今年の発表群に通底するストーリーラインでした。
全体像:すべては「Agent System of Record」へ
個別の発表に入る前に、Databricks が掲げた大きな構想を押さえておきます。それが 「Agent System of Record(エージェントの記録システム)」 です。
これは、データ基盤・統合ガバナンス・エージェント開発・エージェントアプリまでを一気通貫でつなぎ、Sales / Support / Engineering / Ops / IT / Finance / Security / Marketing といったあらゆる部門の業務を、エージェントが安全かつ低コストで支える、という壮大なビジョンです。従来「System of Record」と言えば基幹システム(ERP/CRM など)を指しましたが、これからはエージェントが起こしたアクションそのものが記録・統治される時代になる——という世界観が提示されました。
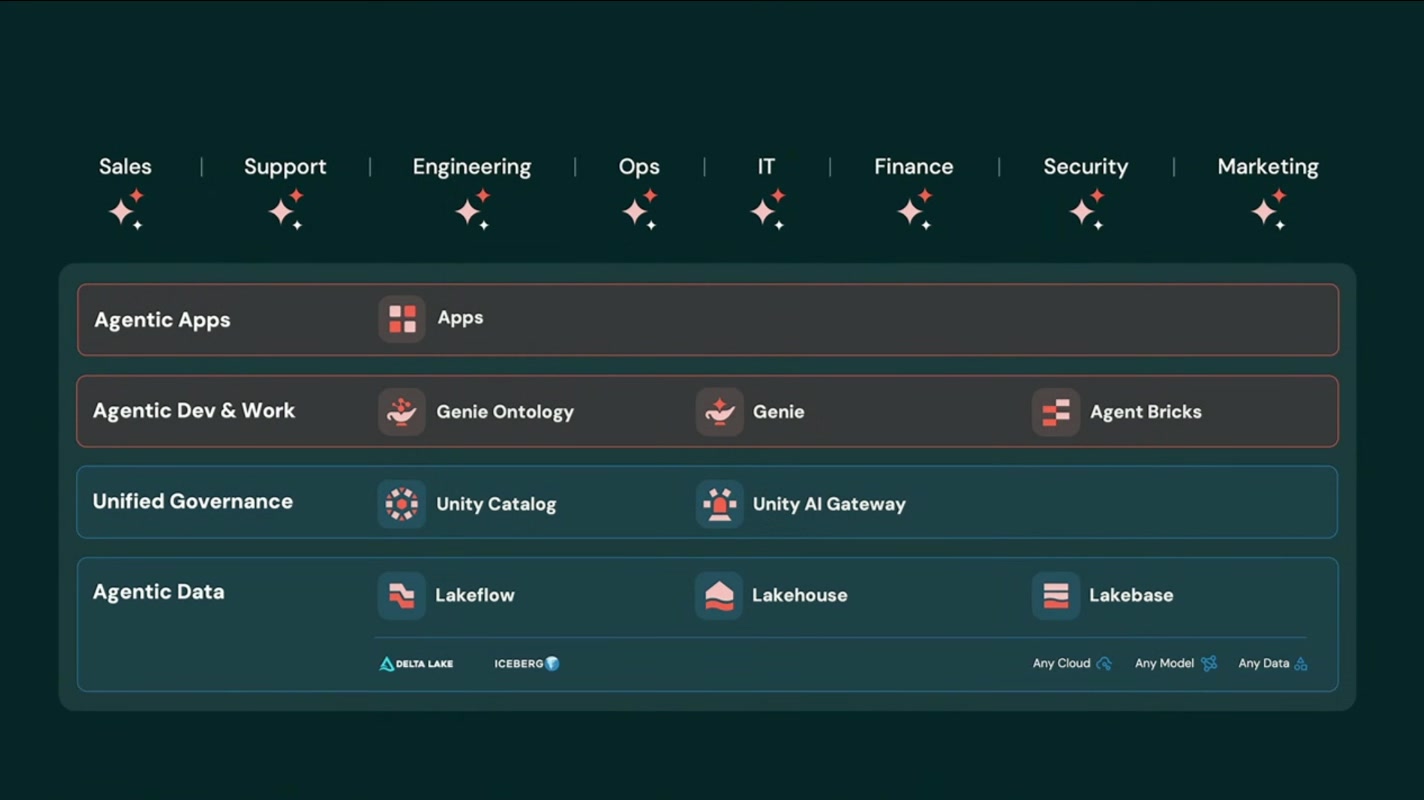
今回の発表ハイライト(記事インデックス)
基調講演で発表された主な内容を、以下の記事に分けて詳報します。各記事へは順番に公開していく予定です。
- 本記事:基調講演まとめ(総括編)
- Genie One:データを理解するAIの同僚(Genie Ontology / OntoRank / ライブデモ徹底解説)
- Lakeflow & Genie ZeroOps:データエンジニアリングの簡素化と運用の”自動運転”
- Lakehouse//RT:レイクハウスがミリ秒のリアルタイム分析へ(Reynold Xin 氏セッション)
- Lakebase:AIエージェント時代のサーバーレス Postgres と LTAP
- 統合ガバナンス & エコシステム:Unity Catalog / Unity AI Gateway / Delta Sharing / Panther / CustomerLake
- OpenAI Greg Brockman 氏 対談:Databricks × OpenAI が描くエージェントの未来
このほか、セキュリティ領域での Panther 社買収(Security Lakehouse)、マーケティング領域での CustomerLake(Agentic CDP) といった発表もありました(詳細は第6回で)。
所感
ここ数年の Databricks のキーノートは「Lakehouse でデータを一つに」というメッセージが中心でしたが、今年は明確に 「エージェント」 へと軸足が移ったと感じました。面白いのは、その語り口が「すごいモデルができました」ではなく、終始 「賢いモデルを”実務で使えるもの”にするには、データ接続とコストという地味だが本質的な問題を解く必要がある」 という、極めて実務家寄りの視点で貫かれていたことです。
裏を返せば、モデルの性能競争は一段落し、勝負の土俵は「いかに自社データと安全・低コストにつなぐか」という”運用と統治”のレイヤーに移った、という宣言にも聞こえました。次回以降、その具体策となる各製品を一つずつ掘り下げていきます。
参考リンク
- Databricks Data + AI Summit 2026 公式サイト
- Databricks Announces 2026 Data + AI Summit Keynote Lineup(公式ニュースルーム)
*#DAIS2026 #Databricks #データブリックス #現地レポート*