朝の2時。スマホが鳴る。パイプラインが落ちた、という通知だ。眠い目をこすってログを追いかけ、どこで何が壊れたのかを手探りで探す。データ運用に関わる人なら、一度は通った道だと思う。
けれど、本当に怖いのはこちらかもしれない。データの誤りは、エラーも出さず、止まりもせず、「静かに」紛れ込む。間違った数字がそのまま流れ、気づかないうちに経営判断の根拠になる。Data + AI Summit 2026の基調講演では、こうした「夜中のアラート」と「静かなデータ汚染」の両方をそもそも無くしにいく新機能が披露された。名前はGenie ZeroOps。データとAIの運用を自動操縦に乗せる、という発想だ。

作るより、運用のほうが大変
データ基盤の話をすると、つい「どう作るか」に目が行く。けれど現場で時間を食うのは、作った後だ。
講演で示された数字はシンプルだ。保守に時間の53%以上を取られている。半分以上が「維持」に消えている計算だ。しかもそれだけ手をかけても、毎月60時間ほどはどこかが止まっている。せっかく集めた優秀なデータ人材が、新しい価値を生むのではなく、落ちたものを直す作業に追われている。多くの組織で、実際に起きている。
ソフトウェアとは「壊れ方」が違う
ここで大事なのは、データの運用がふつうのソフトウェア開発とは性質が違う、という点だ。
ソフトウェアなら、バグが出ればテストで弾かれるか、エラーで止まる。失敗が目に見えるし、元に戻せる。ところがデータは違う。先に書いたとおり、誤りはエラーも出さず止まりもせず、間違った数字がそのまま下流へ流れていく。そして気づかないうちに、その数字をもとに経営判断が下される。後になって「あの集計、実は間違っていた」と分かったときには、もう手遅れ。これがデータ運用の怖さだ。
だから、コーディングを自動化するエージェントを入れただけでは、運用のインシデントは解けない。コードを書くのは入口にすぎない。難所は「直したものが本当に正しいか」を確かめる検証(verify)の部分だ。
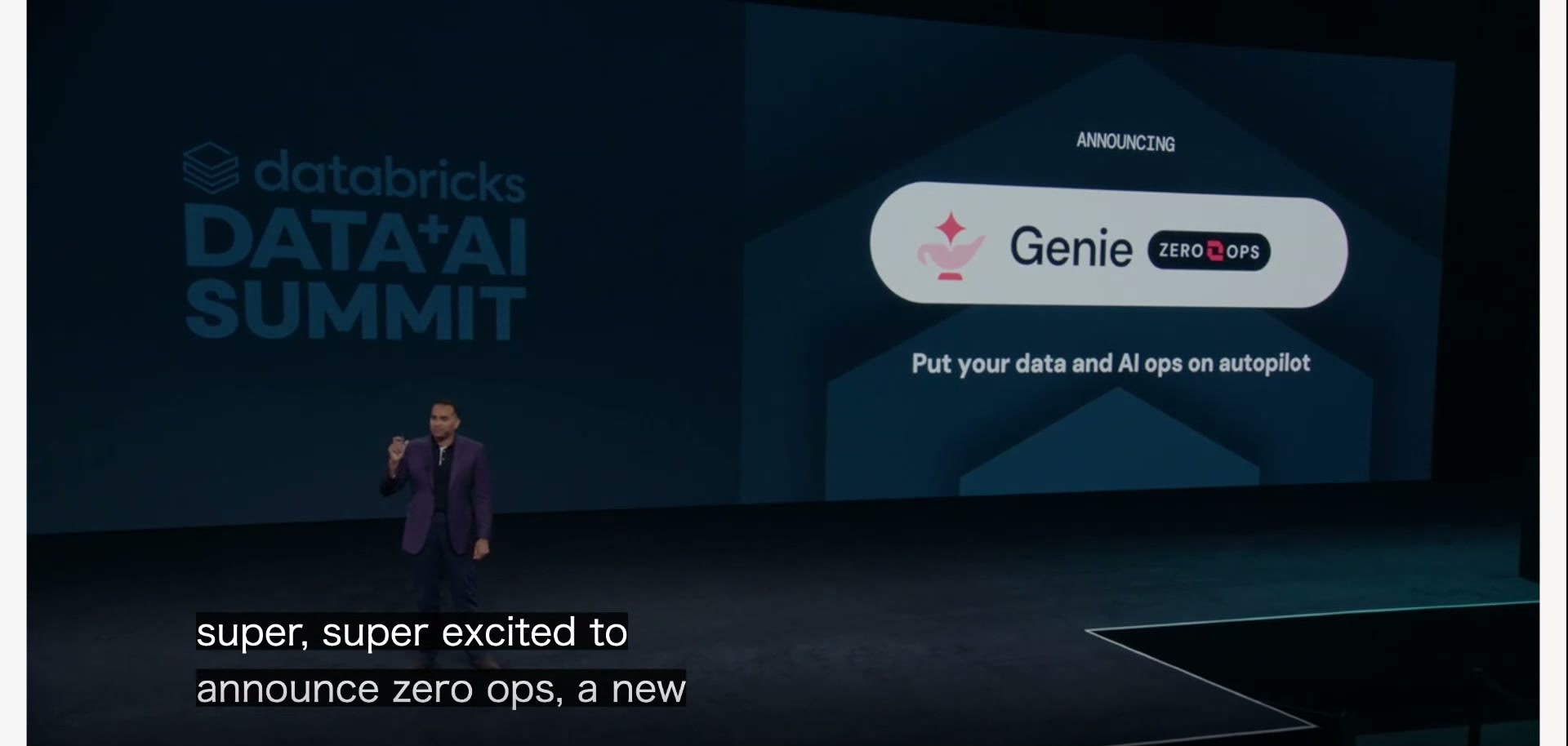
ZeroOpsが裏で回す3つの動き
では、Genie ZeroOpsは何をするのか。人が気づくより前に、裏側で次の流れを回す。
まず異常の検知。テーブルごとに「いつもの動き」を機械学習で覚えさせておき、そこから外れた動きを見つける。次に原因の究明。Unity Catalog(データやAIの来歴=リネージを追える統制基盤)をたどり、「どこが大もとで壊れたのか」という根本原因まで遡る。そして3つめが修正案の生成。「ここをこう直せば直る」という案を、エージェントが自分で書き起こす。
画面イメージも独特だった。ずらりとグラフが並ぶダッシュボードではなく、メールの受信箱のようなUIで、深刻度の高い順にインシデントが並ぶ。「いま危ないのはこれ」が一目で分かる作りだ。
ただし、本当の難所はこの先にある。書いた直しが正しいと、どう確かめるか。検知・原因究明・修正案の3つを回した後、ZeroOpsはもうひと手間かける。
本番を壊さない仕掛け——隔離サンドボックス
ここがいちばん肝心なところだと感じた。修正案を作れるAIは他にもあるかもしれない。問題は「その直しが本番のデータを壊さないと、どう保証するか」だ。
ZeroOpsは、提案した修正をいきなり本番に当てない。まず隔離されたサンドボックス(試し場)で検証する。仕組みはゼロコピークローン。データを物理的に複製せずに、瞬時にそっくりな環境を用意する技術だ。その複製の上で実際に修正を走らせ、出てくる数字が正しいかを確かめる。
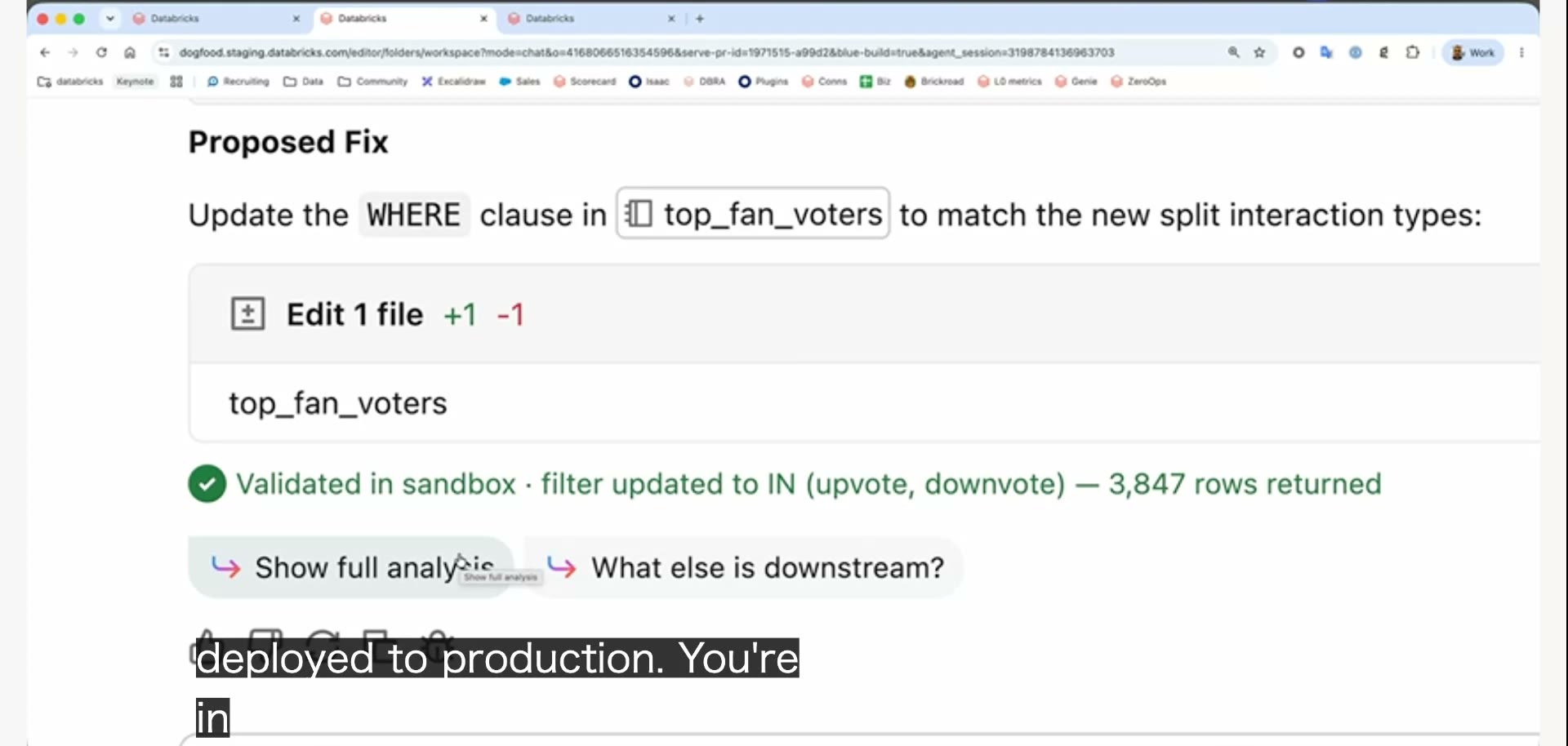
そして、ここは強調しておきたい。本番への適用には必ず人の承認が要る。エージェントが勝手に本番へ書き込むことはない。「直す」「確かめる」までを自動で進め、「反映する」の最後のボタンは人が押す。任せきりにせず、けれど面倒な部分は肩代わりさせる。その線引きがはっきりしている。
検証の威力がよく分かるのが、個人情報(PII)の露出を直す例だ。
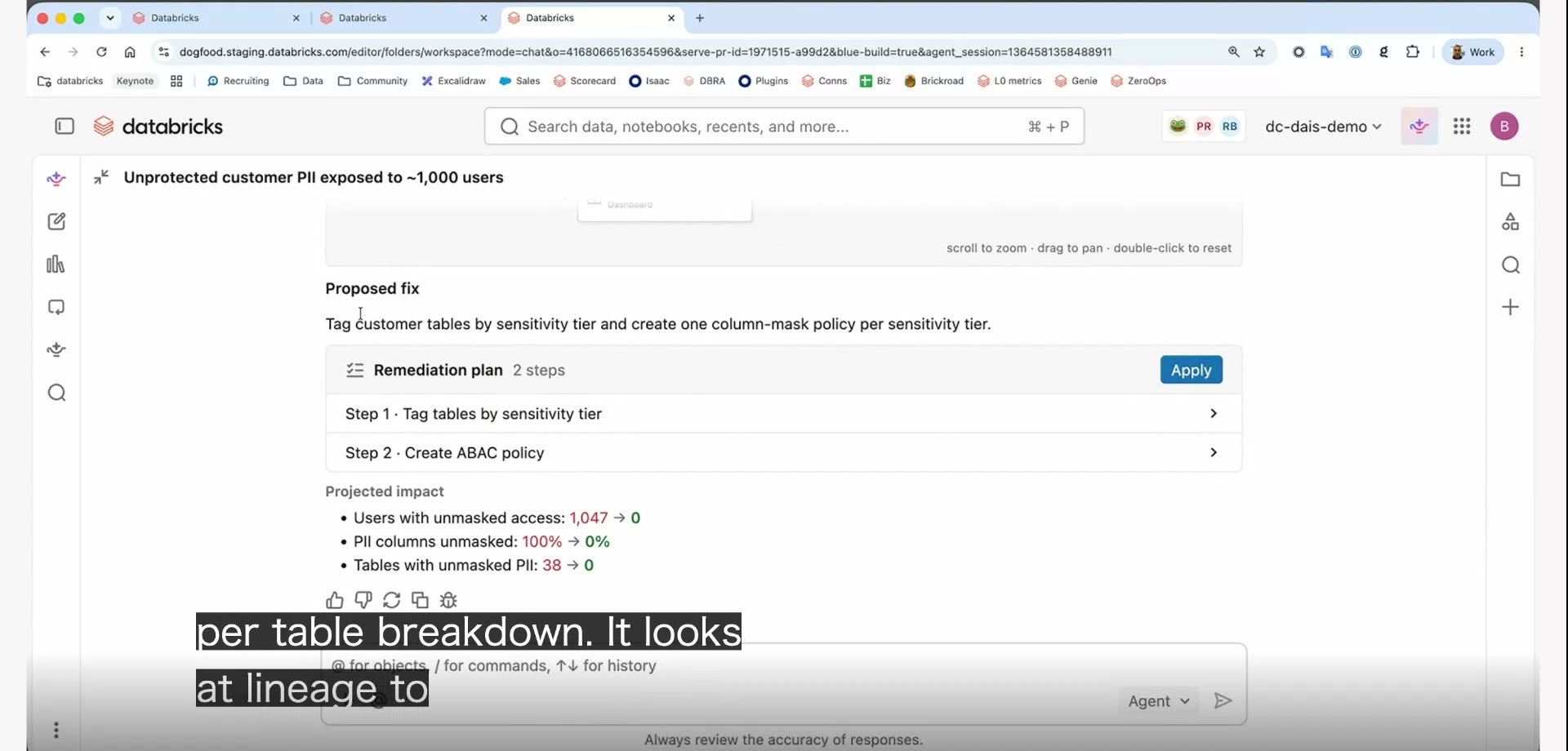
「直したら、誰が見られなくなって、何件が安全になるのか」。その影響まで数字で見せてから、人が承認する。これなら踏み切れる。
押さえどころ
ZeroOpsの登場で問われるのは、機能の良し悪しよりも、自社の体制のほうだ。
あなたの組織のデータ人材は、いま何に時間を使っているか。落ちたパイプラインの復旧、原因不明のズレの調査、深夜のアラート対応。そうした「維持」に半分以上を取られているなら、それは新しい価値を生む時間を、そっくり失っているということでもある。
維持はできるだけ機械に渡し、人は「価値を生むこと」に回す。最後の承認だけは人が握る。自社のデータ人材の時間が、いま「守り」と「攻め」のどちらに偏っているか。まずはそこを棚卸ししてみる価値がある。
関連:生成AIに「自社の文脈」を渡すサービス「Ontology Boost」
ZeroOpsが壊れた箇所の根本原因までたどり着けるのは、Unity Catalogに「どのデータがどこから来て、何に使われているか」という社内の文脈が積み上がっているからだ。裏を返せば、AIに自社の文脈を渡せていなければ、賢い自動化も正しく働かない——これは、私たちSiNCEが提供を開始したサービス 「Ontology Boost」 がまさに取り組む領域です。生成AI(ChatGPT・Claude・Geminiなど)が、御社固有の用語・KPI・業務ルールに沿って"根拠のある"回答を返せるよう、知識基盤(オントロジー)の構築・接続・運用までを一貫支援します。