
Data + AI Summit 2026。前日の基調講演で Ali Ghodsi 氏が「オントロジーがセマンティクスを支える」と語ったことを受けて、Stardog の最高プロダクト責任者 Navin Sharma 氏のセッション 「Ontology powered Semantic AI on Databricks」 には、ある問いが詰めかけた。「オントロジーとは何で、なぜ気にすべきなのか」。
答えはこうだ。AIエージェントを自律的に動かすために必要なのは、より大きなモデルではない。エージェントが参照すべき意味(セマンティクス)の土台——すなわちオントロジーである。本稿では、ブースで最も多く聞かれたというこの問いから、ハルシネーション(幻覚)を止める仕組み、そして「ユニバーサルセマンティックレイヤー」という考え方までを追う。
エージェントが嘘をつく理由と、オントロジーという答え
オントロジーとは、ビジネスの概念・関係・ロジック・制約を、特定のドメインに即して構造化し、共有可能にした意味の表現だ。要は、人と機械が同じ知識を共有し、理解し、その上で推論できるようにするための器である。Navin 氏は、これがエージェント時代に効く理由を3つ挙げた。
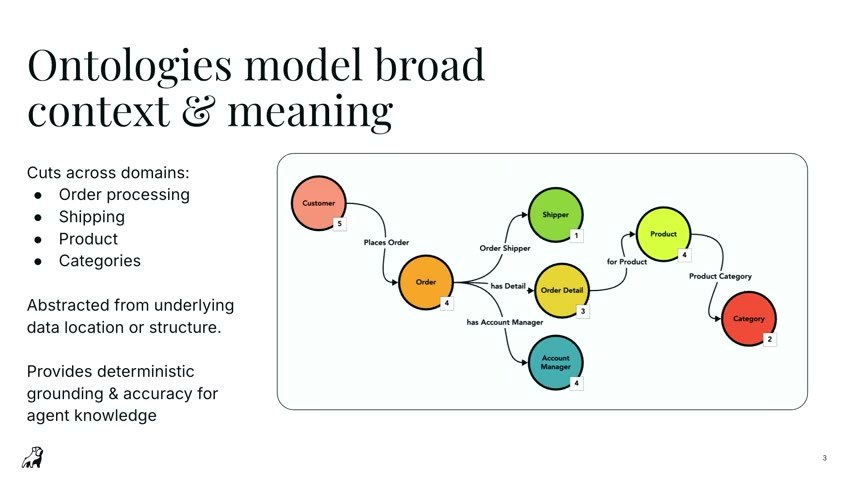
一つ、オントロジーはドメインをまたいだ複雑さを捉える。エンタープライズの問題は、ひとつのテーブルやスキーマ、単一ドメインで完結しない。供給・製造・販売がつながった「デジタルスレッド」を、業務の言葉でモデル化できる。
二つ、オントロジーはデータがどこにどう格納されているかから完全に切り離されている。Navin 氏はここで踏み込んだ。「特定のツール——Databricksであれ、Palantirであれ——に紐づいた“オントロジー”は、データの所在から抽象化されていなければ、ただ言葉を借りているだけだ」。抽象化されていなければ、それはベンダーロックインに過ぎない、と。
三つ、だからこそオントロジーは、エージェントが幻覚なしに動くための決定論的なグラウンディング(接地)を与える。エージェントが問いを投げても、答えはすべてオントロジーというレンズを通して返る。意味の土台が固定されているから、ぶれない。
“セマンティックスタック”のどこにオントロジーは座るのか
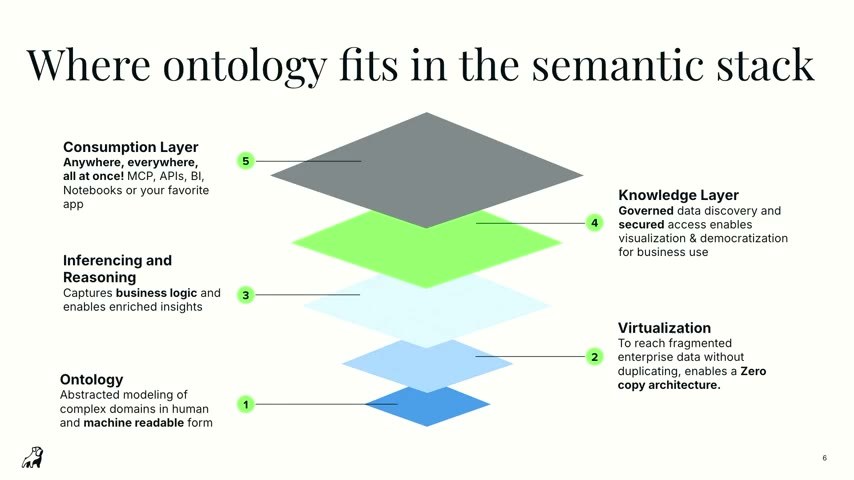
では、オントロジーは技術スタックのどこに位置するのか。Navin 氏が示したのは5層構造だ。
最下層が オントロジー——複雑なドメインを、人にも機械にも読める形で抽象モデル化する。
その上が バーチャライゼーション——断片化したエンタープライズデータに、複製せずに到達する。ここが鍵で、データはDatabricksにもSnowflakeにもBigQueryにも置いたまま、ゼロコピー・アーキテクチャでメタデータだけをオントロジーに対応づける。
3層目が 推論(Inferencing & Reasoning)——ビジネスロジックを載せ、新しい意味を生む。たとえば「高額で遅延した注文」という概念は、「高額=400ドル超」「遅延=要求出荷日より後」という業務ルールを与えれば、問いを投げた瞬間に新しいセマンティック概念として推論できる。
4層目が ナレッジレイヤー——誰が何を消費できるかをガバナンスとセキュリティで制御する。
最上層が コンサンプションレイヤー——MCP(Model Context Protocol/エージェントを外部ツールに接続する標準規格)サーバー、API、BIツール、ノートブック、自前アプリ、どこからでも、いつでも、一度に使える。
標準ベースか、ベンダー固有か——ロックインの分かれ道
オントロジーの“実装の流儀”にも、無視できない分岐がある。
ひとつは 標準ベースだ。W3C(Web技術の国際標準化団体)が10年以上前から定めてきた RDF(データのグラフ表現)・OWL(オントロジー記述言語)・SPARQL(グラフ問い合わせ言語)の上に構築する。Stardogを含む幅広いベンダーが対応し、相互運用性が高く、公共ドメインで作られた業界モデルをそのまま取り込める(F.A.I.R.=見つけ・使い・相互運用し・再利用しやすくする原則 に沿う)。もうひとつは プロプライエタリだ。Neo4j や Palantir のように、ベンダー固有のクエリ言語と実装に縛られると、エンタープライズ規模に広げるときに移植性とロックインの問題が立ちはだかる。
「オントロジーは、データの構造ではなく、ビジネスの意味を表すものだ」。標準に立脚するかどうかは、その思想を裏切らないための選択だ、というのが Stardog の主張である。

オントロジーは「描く」のではなく「ブートストラップする」
概念は分かった。問題は、どうやって最初の知識を立ち上げるかだ。Navin 氏は、製造業「Acme Manufacturing」のシニアアナリストになりきってデモを見せた。
第一は、業務ドメインの専門家と協働して、何を達成したいかをユースケースとして記述すること。
第二は、答えたい“コンピテンシークエスチョン”を定義すること——「総売上は」「何個のウィジェットを販売店に出荷したか」「特定部品の技術者あたり予定保守ロード時間は」。さらに「4月に販売店へ出荷されたウィジェットのうち、機械故障の時間帯に製造された部品インスタンスを1つ以上含むものは」といった、複数ドメインの結合を要する問いも。質問が思いつかなければ、システムが生成もしてくれる。
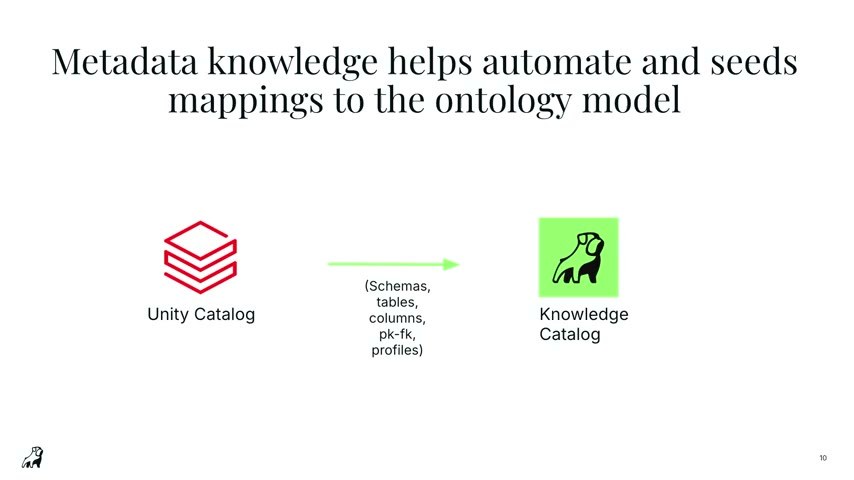
第三が、裏側のシステムのメタデータを取り込むこと。デモでは Unity Catalog に接続し、スキーマ・テーブル・カラム・主キー/外部キー・プロファイルを「Stardog Knowledge Catalog」へハーベスト(収集)する。対象はUnity Catalogに限らず、Collibra、Purview、Snowflakeでもよい。ここからオントロジー(スキーマ・モデル・制約・ルール)とシステムへのマッピングを生成する。繰り返すが、データそのものはStardogに一切移動・複製しない。
ハルシネーションを止める仕組み——問いをオントロジーの言葉で解く
そして、エージェントが幻覚を起こさずに情報を取り出す核心部分だ。
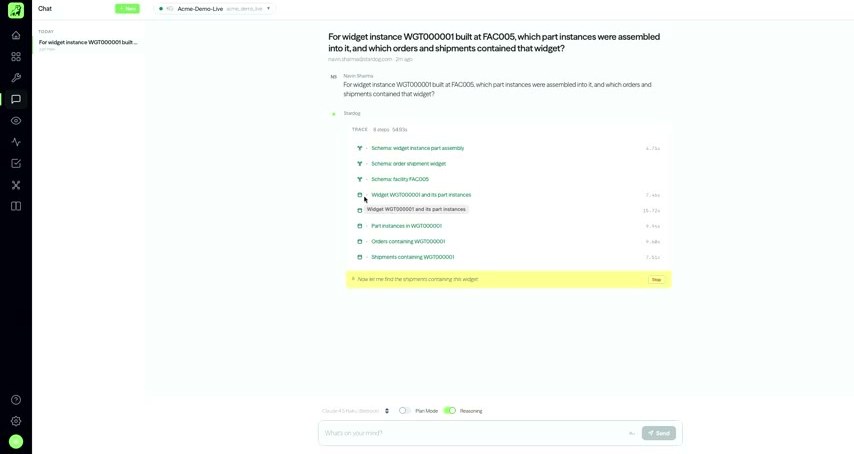
「FAC005で製造されたウィジェットインスタンス WGT000001 に、どの部品インスタンスが組み込まれ、どの注文と出荷がそれを含むか」。こう問うと、裏でマルチエージェント・オーケストレーションが走る。まず元の問いから、widget・instance・part・assembly・order・shipment・facility といったオントロジー概念を特定。LLMが標準ベースの SPARQL クエリを生成し、先のマッピングを使って Databricks の SQL ウェアハウス・エンドポイントへSQLをプッシュダウン、クエリ時にデータをフェデレーションして結果を返す。
重要なのは、その全工程にオブザーバビリティ(決定トレース)が効くことだ。デモでは8ステップのトレースが展開され、「出荷を探す」処理が逐次見えていた。そして極めつけは、情報が無ければ答えないこと。「返品のあった顧客は」と尋ねて該当データが無ければ、無理に答えを作らない。問いがどのオントロジー概念を参照し、どの情報があるかを見たうえで応答する——これがグラウンディングの効能である。
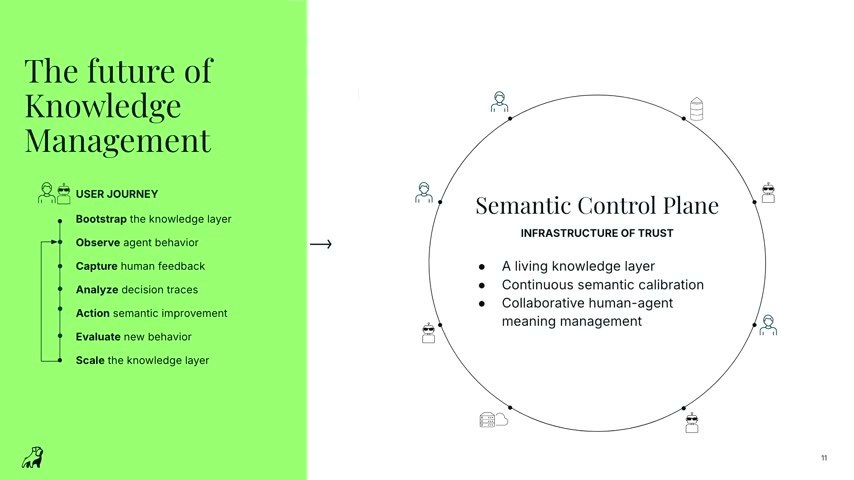
生きた知識層——セマンティックコントロールプレーン
オントロジーは一度作って終わりではない。Navin 氏は「ナレッジマネジメントの未来」を、ブートストラップ → 観測 → 収集 → 分析 → アクション → 評価 → スケールという7段階のユーザージャーニーとして示した。
エージェントの挙動を観測し、人間(ナレッジ・スチュワード)のフィードバックを取り込み、決定トレースを分析し、意味の改善をアクションに移す。変更を加えたら、「期待する答え」と照らして精度が落ちていないかを評価してから反映する。この、人とエージェントが意味を磨き続ける営みを Stardog は 「セマンティックコントロールプレーン(信頼のインフラ)」 と呼ぶ。生きた知識層であり、継続的なセマンティック・キャリブレーションであり、人と機械の「ミーニング・マネジメント(意味の運用)」である。
なぜ“ユニバーサル”でなければならないか
ここで Navin 氏は、各データ/アプリプラットフォームが語る「セマンティクス」との違いを明確にした。Databricks の Genie、Snowflake の Cortex、SAP の Joule——いずれも自社のメタデータやデータ層・アプリ層の理解に基づくため、オントロジーとして見れば射程が限られる。Tableau や Power BI のようなBI層のセマンティクスも、ダッシュボードの指標に閉じる。エンタープライズの複雑さとドメインの広がりにはスケールしない。
だからこそ、データの構造から抽象化され、標準に立脚した ユニバーサルセマンティックレイヤー——「信頼のインフラのための認知バックボーン」——が要る、という主張だ。裏付けとして Gartner の予測が引かれた。2027年までに、ユニバーサルセマンティックレイヤーを持たない企業はAIの手戻り・是正に40%多く支出する。2028年までに、AIの失敗の50%はセマンティックフレームワークの欠如または不備に起因する。2029年までに、大企業におけるAIエージェント・オーケストレーション成功の80%は、ユニバーサルセマンティックレイヤーに依存する(出典:Gartner『Future-Proof AI Systems and AI Agents With Universal Semantic Layer Development』2026年2月3日)。
セマンティックレイヤーが無ければ、エージェントは互いの「壁に囲まれた庭(walled garden)」で、つながらない知識を抱えたまま走り回ることになる、と Navin 氏は警告した。

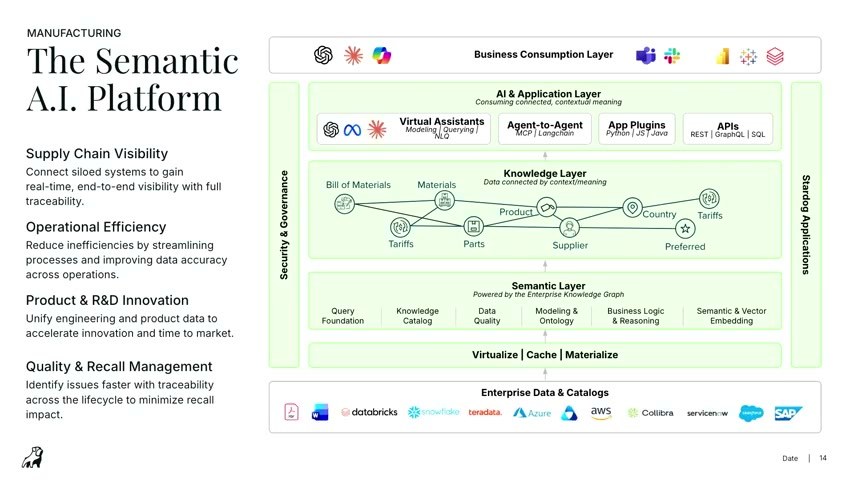
製造・金融・ライフサイエンスへ——意味の土台が効く現場
最後に示されたのが、業界別の「セマンティックAIプラットフォーム」の全体像だ。上位のビジネス消費層とAI/アプリ層(バーチャルアシスタント、MCP・LangChainによるエージェント連携、APIはREST/GraphQL/SQL)の下に、エンタープライズ・ナレッジグラフ(製造業なら部品表・素材・サプライヤー・国・関税…)が広がり、その下にセマンティック層(クエリ基盤、Knowledge Catalog、データ品質、モデリング&オントロジー、ビジネスロジック&推論、セマンティック&ベクトル埋め込み)が座る。データはDatabricks・Snowflake・Teradata・Azure・AWS・Collibra・ServiceNow・SAPなどに置いたまま、仮想化・キャッシュ・マテリアライズで使う。
適用先は広い。製造業ならサプライチェーン可視化・操業効率・R&Dイノベーション・品質/リコール管理。金融なら不正・AML(マネーロンダリング対策)、リスク管理、コンプライアンス、顧客360。ライフサイエンスなら臨床試験や分子・タンパク質レベルの理解をつなぎ、創薬を加速する。
押さえどころ
このセッションの主張は、突き詰めればひとつだ。エージェントの信頼性は、モデルの賢さではなく、意味の土台の確かさで決まる。
- オントロジーは、ドメインを横断する業務の意味を、データの所在から切り離してモデル化したもの。だからエージェントに決定論的なグラウンディングを与え、幻覚を抑える。
- 実装は W3C標準(RDF/OWL/SPARQL) に立脚すると、相互運用性と移植性で有利。ベンダー固有実装はロックインを生む——というのがStardogの立場だ。
- データは動かさない。ゼロコピーでDatabricks等に置いたまま、SPARQLを生成しSQLとしてプッシュダウンする。Unity Catalogのメタデータはオントロジーの“種”になる。
- オントロジーは生き物。セマンティックコントロールプレーンとして、人とエージェントが意味を継続的に磨く。
なお本セッションはStardogによる協賛セッションであり、プラットフォーム内蔵のセマンティクス(Databricks Genie 等)に対しては「ユニバーサルであること」を競争軸に置く立場からの主張である点は、読み手として踏まえておきたい。とはいえ、「エージェントを本番で信頼するには意味の層が要る」という論点そのものは、ベンダーを問わず通底するテーマだろう。








