
Data + AI Summit 2026、Day2。前日が「AIを使う側」の話だったとすれば、この日の主役は作る側の開発者だった。Databricks のディレクター・オブ・プロダクトマネジメント、Casey Uhlenhut 氏がステージに立ち、こう切り出す。エージェントのデモやパイロットを見るとき、私たちが見ているのはエージェントループだけだ。だが、それは全体のたった1%にすぎない。残りの99%——認証、MCP(Model Context Protocol=エージェントを外部ツールに接続する標準規格)接続、アイデンティティ管理、タイムアウトせずに長時間走らせる仕組み——そこで人は躓く。
本稿は、その99%を肩代わりするために設計されたエージェント開発基盤 Agent Bricks を追う。鍵は3つの言葉、Choice・Context・Control に集約されていた。
学べる本番環境——Free Editionに載った号砲
口火を切ったのは、製品ではなく「敷居」の話だった。Genie、GPUs、Agent Bricks、Lakebase、そして Lakeflow Designer が、Databricks Free Edition で利用可能になる。学習用の砂場ではなく、本番と同じプラットフォームの上で学べるということだ。すでに数十万人がここでデータとAIのプロジェクトを作り、学んできた。実質的に、Databricks のほぼすべてが永続的に無償で手に入る。
なぜこれが発表の入口なのか。学生や新しい開発者がDatabricks経験を持って現場に来れば、プラットフォームの学習に最初の数週間を費やす必要がなくなり、いきなり実課題に取り組める——採用する企業にとって、その価値は大きい。裾野を広げる一手から、この日の物語は始まった。

エージェントループは氷山の一角——なぜチームはインフラに溺れるのか
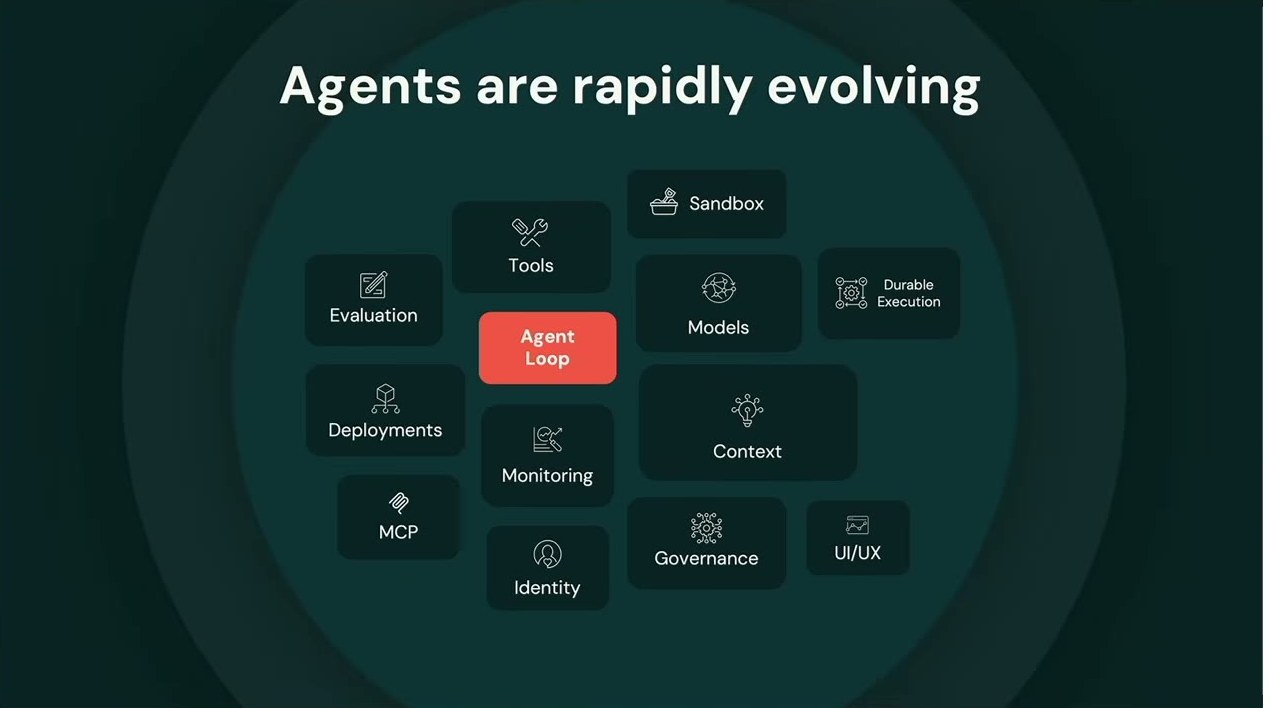
エージェントは急速に進化している。だが Casey 氏が示した図には、中央にAgent Loopが置かれ、その周りをTools・Sandbox・Models・Durable Execution・Evaluation・Context・Deployments・Monitoring・MCP・Identity・Governance・UI/UXが取り囲んでいた。デモで光るのは中心の赤いブロックだけ。しかし本番で必要になるのは、それを取り巻く全部だ。
しかも、この一式をたった1つのエージェントのために組まなければならない。企業が作りたいのは数千のエージェントである。だから開発チームは、エージェントを作るのではなく、インフラを作ることに追われてしまう。「氷山の一角」という比喩がこれほど似合う状況もない。
開発チームを縛る三つの壁——フロンティア・データ・安全性
顧客と対話する中で繰り返し現れる課題は、3つに整理できたという。
第一に、モデルとハーネスに追従し続けること。フロンティアは毎週のように変わる。新しいモデルが出る。Omnigent のような新しいエージェントハーネス(エージェントを動かす実行基盤)が出る。半年前に組んだ解は、もう1世代以上遅れている。最先端に乗り換えようとすれば、スタックごと作り直す「リプラットフォーム」が要る。第二に、エージェントを正しい業務データに接続すること。競争優位は自社データにあるが、そのデータはPDFから外部APIまで多様な形式に分散し、エージェントに正しい文脈を選ばせるのは難しい。第三に、安全にデプロイできること。エージェントは企業内で最も権限を持つアクターであり、機微な顧客データに触れ、実際の行動を取る。だからこそ「AIエージェントが本番DBを9秒で全削除した」「内通するAIエージェント」「トークン最大化でAI予算が爆発」といった見出しが現実に現れている。

Choice・Context・Control——基盤が答えるべき三つの問い
だからこそ、エージェント開発基盤は選択(Choice)・文脈(Context)・統制(Control)を提供しなければならない——Agent Bricks の全体像は、この3列で描かれていた。
Choice には、フロンティア/カスタムのModels と、Managed Omnigent・Custom Agents・Agentic Tasks を束ねるOrchestration(LangGraph・Omnigent・crewai・Agno に対応)が並ぶ。Context には、Documents・Tables・Volumes・Memory API・Lakebase からなるKnowledge, Data & Memory と、MCP・Skills・Agent Tools のTools。そしてControl には、Databricks Sandbox・Agent Deployment・Durable Execution のDeployment と、Unity AI Gateway を要に Observability・Evaluation・Authentication・Smart Policies を備えたGovernance が座る。
Choice の核心は、リプラットフォームせずに最先端へ居続けられることだ。すべてのモデルに統一インターフェースでアクセスでき、容易に切り替えられる。Opus・GPT・Gemini・Qwen、そして直近では Kimi。さらにこの日、SpaceX との提携により Grok モデルファミリーへのアクセスも発表された。フロンティアモデルで足りないときは、強化学習で自社タスク特化のカスタムモデルを学習・デプロイすればよい。実際、社内のGenie研究チームはRLで自タスクにおいてOpusを上回ったという。

コンテキストという最難問——Unity Catalog・Document Intelligence・そしてメモリ
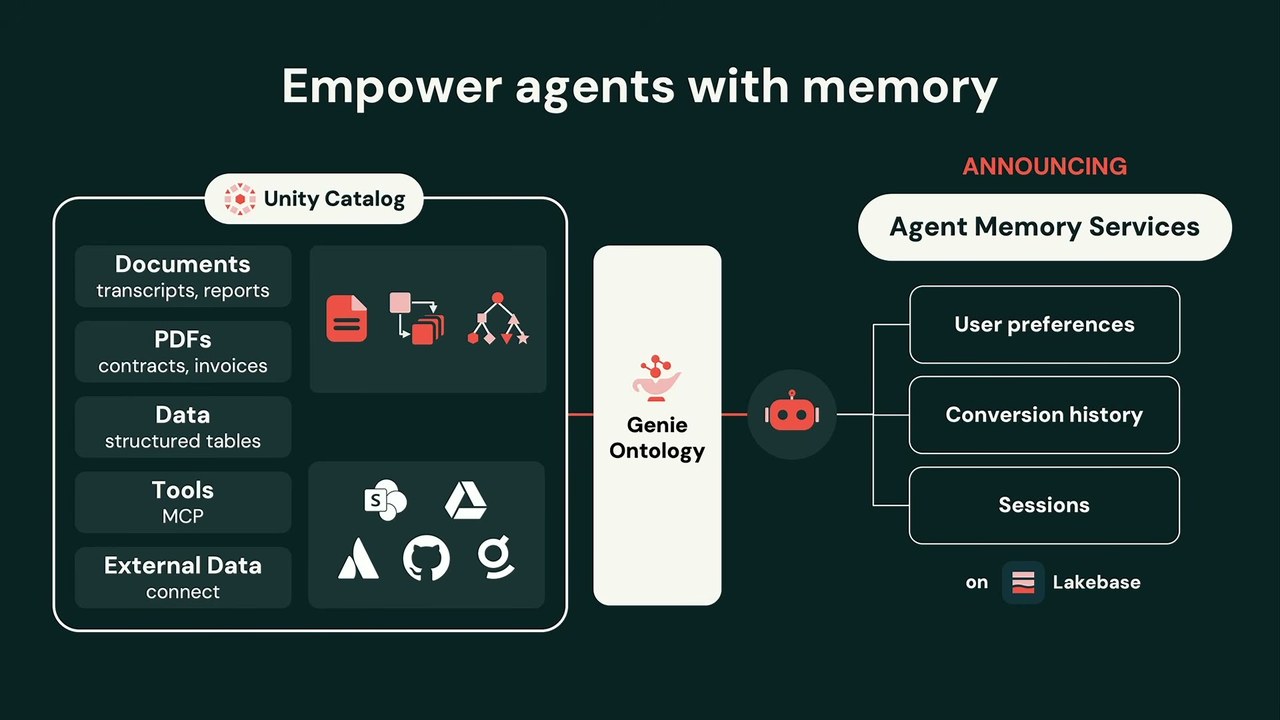
最高のモデルも、与える情報の質を超えられない。だから次は Context だ。Agent Bricks では、すべての文脈を Unity Catalog で中央管理する。外部データもここに接続し、あらゆるデータがエージェントのツールとして呼び出し可能になる。ダッシュボードすら発見できる。だが発見だけでは足りず、正しい文脈を引き当てることが要る。前日発表された Genie Ontology が、全エージェント資産にメタデータ層をかぶせ、効率的な文脈の検索と選択を支える。
文脈が複雑な形式で来る問題には Document Intelligence——ai_parse_document / ai_extract / ai_classify による解析・抽出・分類で、品質とコストの曲線で最良を狙う。数百万のPDF契約書や請求書を、銀行口座を空にせずに扱えるようにする発想だ。Databricks 外のデータには Managed External MCP で安全に接続し、認証の面倒を肩代わりする。
そして、ユーザーごとにエージェントを作らずに個別化したい——その答えがこの日の新発表 Agent Memory Services だ。マネージドAPIでカスタムエージェントをつなぎ、ユーザー設定・会話履歴・セッションを保存する。基盤は Lakebase。コンテキストはエージェント領域で最も難しい問題であり、Databricks はメモリ・検索・リトリーバルの難問だけを専門に解く研究チームを抱え、その成果をサービスに焼き込み、Genie にも統合していると語られた。
壁の中で走らせる——Databricks Sandboxという「囲い」
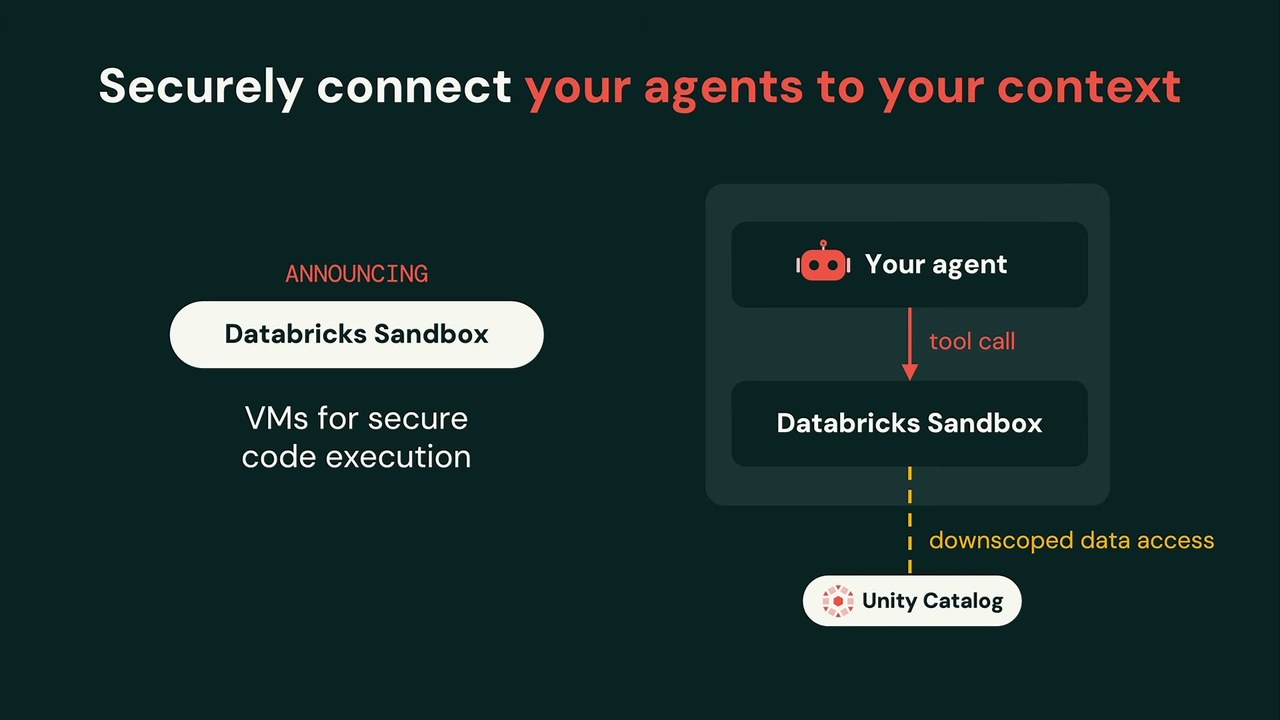
ここから Control だ。エージェントにコードを走らせれば、放っておくほど創造的なことをやってのける。だが本番を落とされては困る。囲われた環境で動かしたい——その答えが、この日の新発表 Databricks Sandbox である。
Sandbox は、エージェントが安全にコードを実行できるVMを提供する。ただし汎用VMではない。箱出しで自社データへのアクセスを備えた唯一のVMだと位置づけられた。downscoped access(権限を絞った、ユーザーの代理として行うアクセス)でUnity Catalogのデータに触れ、エージェントはそのVMの中でデータと戯れても、システムの他の部分に影響を与えない。しかもこのSandboxはミリ秒で起動する。エージェントの作業速度に合わせて、生成と破棄を高速に繰り返せる。文脈を安全に「いじり倒す」ための囲いだ。
Unity AI Gateway——統制・セキュリティ・コストを一手に
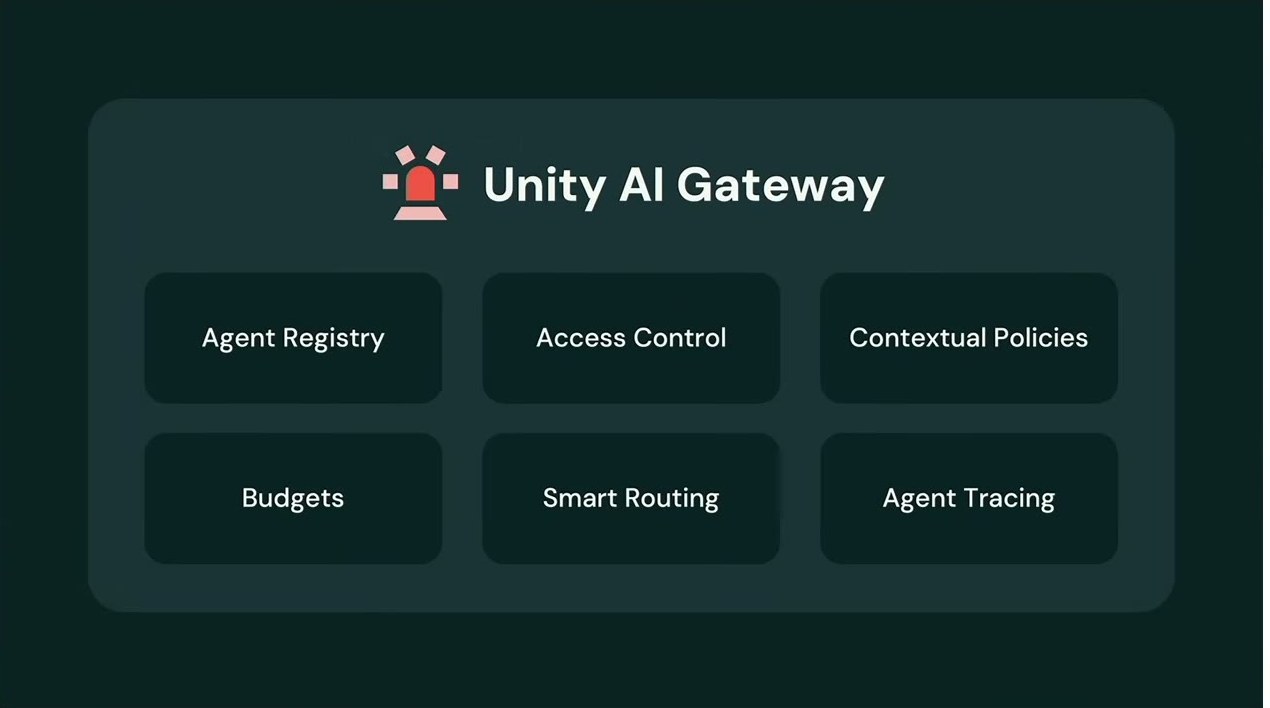
そして真打ち、Unity AI Gateway。モデル・エージェント・MCP・スキルを横断して統制を統一する、中央集権的なガバナンス/セキュリティ/コスト制御の仕組みだ。エージェントを企業内で自律的に走らせることを可能にする要であり、6つの能力を備える。
Agent Registry は、社内で作られた全エージェント・MCP・スキルを、外部エージェントも含めて1つの台帳に登録する記録システム。Contextual Policies(コンテキスト依存ポリシー)は、SQLで定義する動的・ステートフルなセキュリティポリシーで、たとえばPII(個人を特定できる情報)を含む機微データに触れたエージェントは「汚染された」状態に遷移し、次の行動が変わる——同僚へのメール送信はALLOW、Salesforce更新はASK HUMAN、社外公開はDENYといった具合に、触れたデータに応じて許可が切り替わる。Access Control、Budgets(ユーザー/グループ単位の支出上限)、Smart Routing(複雑度に応じたモデル振り分け、プロバイダ/クラウド横断のフォールバック)、そしてAgent Tracing——MLflow トレーシングで入出力と途中経過をすべて記録し、Unity Catalog のテーブルに集約する。そのテーブルとデータは自社の所有であり、Genie で分析したり、SIEM(ログを集約し脅威を検知する仕組み)である Lakewatch につないでデータ漏洩のリアルタイム通知を得たりできる。
エージェント基盤をデータ基盤に統合したからこそ、こうしたコンテキスト依存ポリシーが成立する。管理者は、安全かつ責任を持って組織全体にAIを民主化できるようになる。
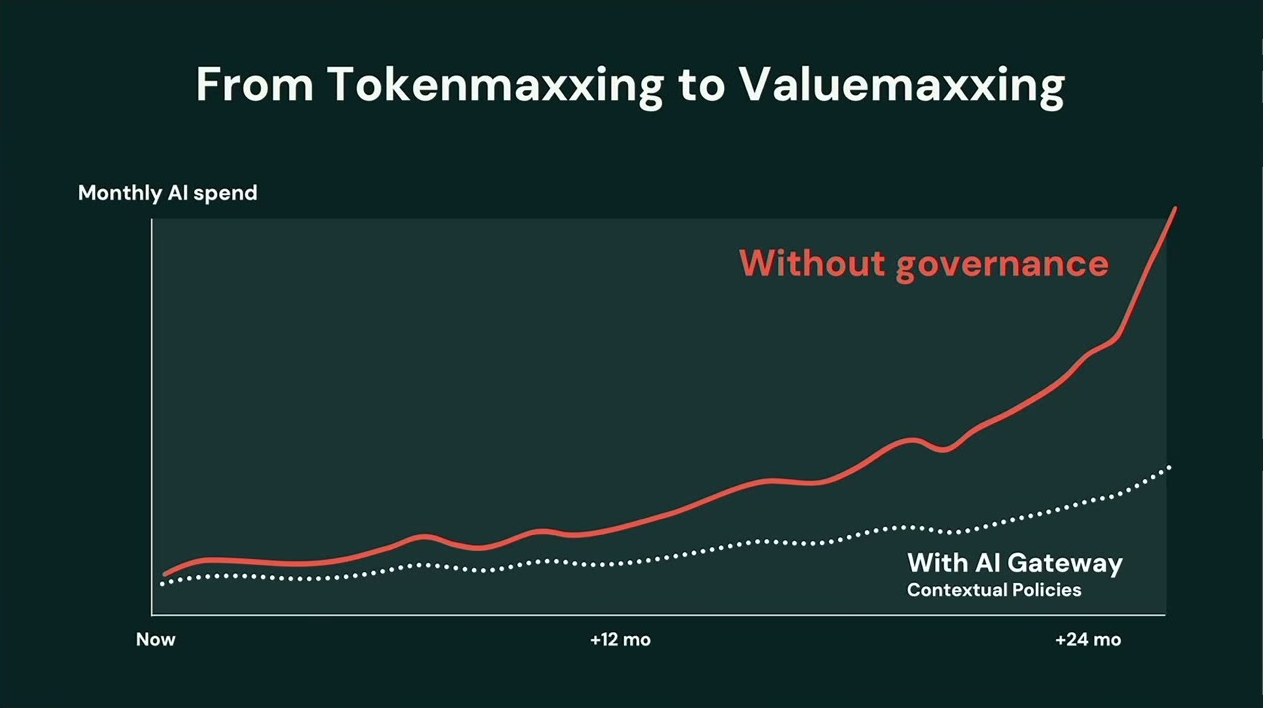
tokenmaxxingからvaluemaxxingへ——AI支出の曲線を曲げる
しめくくりは、ソフトウェアエンジニア Ankit Mathur 氏のデモだった。AIに本気で取り組むのは高くつく。支出上位1%のユーザーは年間9万ドル超を費やし、その指数曲線は鈍る気配がない。いまやエンジニアだけでなく全社員がエージェントを並列で使い、モデルは止めない限り働き続ける。だが、それは責任ある使い方なのか。
デモは、開発者の一日が始まるターミナルから出発する。Codex を Unity AI Gateway に向けるだけで、推論とMCPが中央のチョークポイントを通る。エンジニアには1日50ドルの予算があり、ポリシーはハードな上限ではなく繊細だ。上限に近づくと、より安価でトークン効率の良いモデル(今週リリースのDatabricks Kimi)へと誘導される。さらに Omnigent をGatewayにつなぐと、メタハーネスがタスクより上位のレベルで判断を下す。「このリポジトリの4つのバグを探せ」という指示に対し、表層スキャンには安価な Kimi、エッジケースレビューには賢く安価な Gemini 3.5 Flash、コアロジックや深い監査には中〜高品質モデルを割り当てる——すべては Databricks Sandbox 上で並列実行され、エンタープライズ級のセキュリティを保つ。
仕上げは Agent Tracing。コーディングセッションのトレースをUnity Catalogに集め、Genie で分析すると、デフォルトが最高価格のOpusだったためにセッションの約9割が過剰(overkill)だったと判明した。データがあれば推測ではなくデータ駆動で判断できる。この知見は、どんなスキルを作ってトークン効率を高めるかの指針にもなる。Casey 氏と Ankit 氏の主張は明快だ。予算・インテリジェントルーター・トレーシングで指数曲線を曲げ、世界を「トークン最大化(tokenmaxxing)」から「価値最大化(valuemaxxing)」へ動かす。
押さえどころ
Agent Bricks が答えようとしたのは、「エージェントループの外側にある99%」だった。Choice・Context・Control の3語に、その全部が詰まっている。
- Free EditionにGenie・GPUs・Agent Bricks・Lakebase・Lakeflow Designerが解放され、本番と同じ基盤で学べるようになった。
- Choice——統一インターフェースで全フロンティアモデルを切り替え、SpaceXとの提携でGrokも追加。足りなければRLでカスタムモデルを学習でき、リプラットフォーム不要。
- Context——Unity CatalogとGenie Ontologyで文脈を中央管理し、Document Intelligenceで複雑な文書を解く。新発表のAgent Memory ServicesがLakebase上でユーザー設定・会話履歴・セッションを保存する。
- Control——新発表のDatabricks Sandboxがdownscopedアクセス付きのVMでコードをミリ秒起動・安全実行し、Unity AI GatewayがAgent Registry・Contextual Policies・Budgets・Smart Routing・Agent Tracingでモデル/エージェント/MCP/スキルを横断統制する。
- デモが示したのは、予算・ルーティング・トレーシングで支出曲線を曲げ、tokenmaxxingからvaluemaxxingへ転じる道筋だった。
エージェント基盤がデータ基盤に統合されているからこそ、コンテキスト依存のセキュリティポリシーやデータ直結のSandboxが成立する。デモで光る1%ではなく、本番で背負える99%を引き受ける——それがAgent Bricksの賭けどころだ。








