
Databricks Data + AI Summit 2026 のセッション 「Agent Ops on Databricks, Powered by Omnigent」 の技術レポートです。登壇は Databricks の Jeanne Choo 氏(AI Forward Deployed Engineer)と Kyra Wulffert 氏(Specialist Solution Architect)。テーマは、「動くデモ」のAIエージェントを、安全・信頼でき・スケールする本番システムへどう引き上げるか。各原則をライブデモで裏づけながら、実践的なプレイブックとして提示されました。
結論を先に言うと、鍵は3つです。エージェントを DevOps/MLOpsの延長にある運用問題(Agent Ops)として捉え直すこと、ガバナンスと再利用性をもつメタハーネス Omnigent で素早く安全に変えられるようにすること、そして MLflow で評価のフライホイールを回し続けることです。本稿ではセッションの流れに沿って、技術的な要点を掘り下げます。
本番化を阻む「プロダクションギャップ」
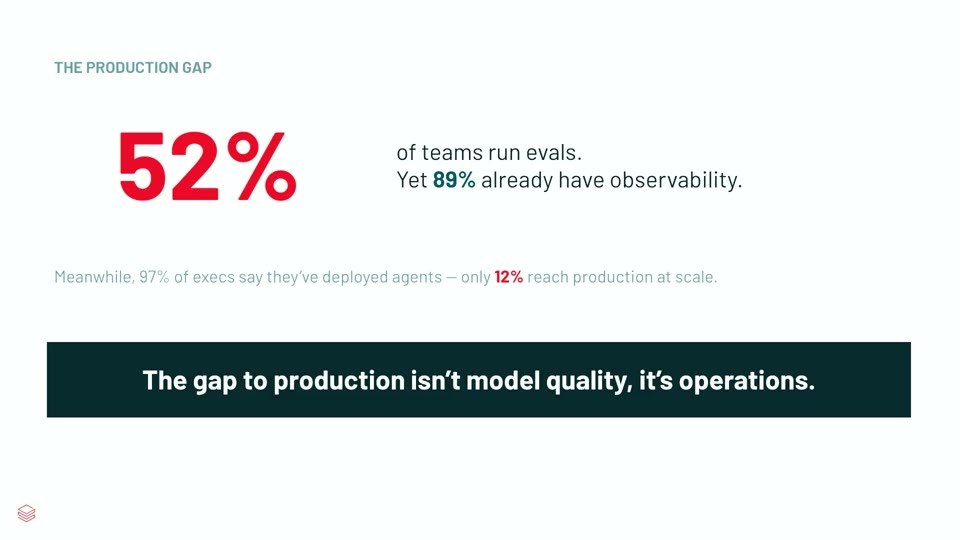
冒頭で示されたのは、業界調査に基づく数字です。経営層の97%が「AIエージェントを導入済み」と答える一方、本番でスケールする段階に到達しているのは12%にとどまる。運用面では、89%が可観測性(オブザーバビリティ)は備えているのに、評価(eval)を回しているのは52%。エージェントを作るチームと、それを信頼して本番に出せるチームの間には大きな隔たりがあります。
登壇者の主張は明快でした。「本番化を阻んでいるのはモデルの品質ではなく、運用(オペレーション)である」。モデルは年々良くなっている。詰まっているのは、それを継続的に統治・評価・運用する仕組みの側だ、という整理です。
DevOps → MLOps → Agent Ops:制御ループの再発明
なぜ運用が難所になるのか。登壇者は、ソフトウェア工学の歴史をたどって説明します。
出発点は DevOps です。コードを書いてから本番に出すまでのリードタイムと、障害時の復旧時間を最小化する一連のプラクティス。バージョニング、CI/CD(継続的インテグレーション/デリバリー=統合・配信の自動化)、自動テストゲート、継続的モニタリングという制御ループが核にあります。この制御ループを機械学習に適用したのが MLOps、エージェントに適用するのが Agent Ops だ、という位置づけです。
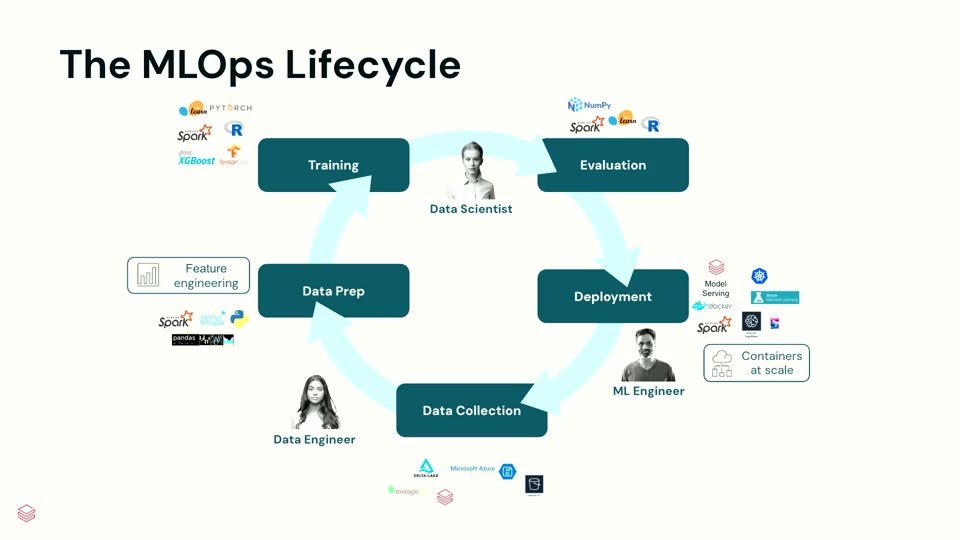
MLOpsのライフサイクルは、データ品質と再現性の DataOps、モデルのバージョニング・追跡・サービングの ModelOps、CI/CDと自動化の DevOps の交差点に立ちます。データエンジニアがデータを準備し、データサイエンティストがモデルを学習・評価し、MLエンジニアがパッケージしてサービングする。そしてドリフトを継続監視し、再学習でループに戻る。ここで中心となる成果物(アーティファクト)は、あくまで モデル でした。
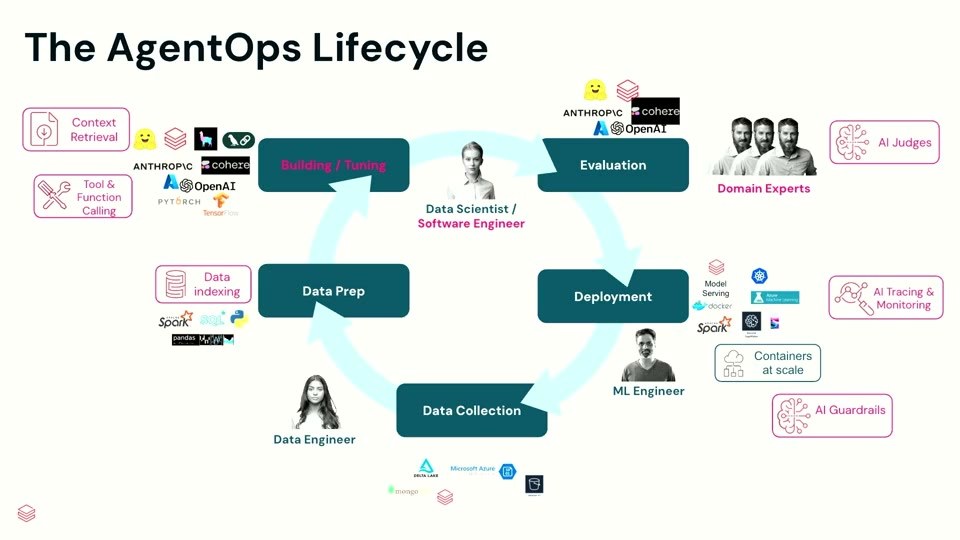
エージェンティックなシステムは、この構図を引き伸ばします。build/test/deploy/monitor というループ自体は同じでも、扱う構成要素が違う。エージェントは単なるモデルではなく、オーケストレーション・ツール呼び出し・メモリ・検索・推論を伴うシステム だからです。新しい登場人物として ソフトウェアエンジニア が加わり、モデルエンジニアリングとソフトウェアエンジニアリングの境界が曖昧になります。
具体的には、データ準備は コンテキスト検索(context retrieval) へ、評価は従来の分類メトリクスだけでなく AIジャッジ(LLMによる採点)とドメインエキスパート(SME)の関与 へと姿を変えます。さらにエージェントは現実に行動を起こすため、意思決定の各ステップをトレース・観測 し、何ができて何ができないかを ガードレール で定義する必要が出てきます。つまり「1つのモデルを学習・監視する」世界から、「1つのモデルを核とした自律システムを build/test/deploy/monitor する」世界へ移った、というわけです。
エージェント特有の6つの課題
複雑さは課題を生みます。本番に到達できない「12%問題」の主因として、6つの課題が挙げられました。技術的なものが5つ、人的なものが1つです。
- コントロール・フェイルセーフ・ガバナンス:従来のゲートウェイでは不十分。モデルへのアクセスは制御できても、エージェントが実行する各ステップは制御できない。必要なのは、ツール呼び出しの上に乗る 「アクション単位の制御プレーン(per-action control plane)」 で、行動の前に「許可/拒否/確認」を挟むこと。キーワードは 「緩和ではなく予防(prevent, not mitigate)」。たとえばプロンプトインジェクションでデータ持ち出しを誘導された場合、翌日ダッシュボードで気づくのではなく、起きる前にブロックする。これはランタイムのポリシーです。
- 信頼性と評価のギャップ:単一のモデル呼び出しならエラーは見える。だが多段のツール呼び出しでは 複合エラー が起こり、しかも サイレントエラー(自信ありげで体裁も整っているのに完全に間違っている出力)になりうる。これは「雰囲気チェック(vibe check)」では見抜けない。測定の欠如が、多くのAIプロジェクトが停滞する理由になっています。
- 可観測性とフィードバック:すべてのツール呼び出し、サブエージェントへの受け渡し(handoff)をトレースする。加えて、ユーザーの低評価・SMEのフラグ・AIジャッジの低スコアといった フィードバックをトレースに紐づけ、「エージェントが何をしたか」と「それを他者がどう評価したか・なぜか」を1つのオブジェクトに集約してループを閉じる。
- メンテナンス:本番エージェントは複雑なUI、安全要件、耐久性、エンタープライズツールへの接続、モデル差し替えの柔軟性などを要求する。多くのチームがユースケースごとにこのパイプラインをゼロから作るため、再利用が効かず、時間とリソースの両面で高コストになる。
- ビジネスコンテキストの理解:エージェントが自社の業務プロセスを知り、データカタログを把握し、「正しい数字がどこにあるか」を分かり、ブランドの言葉で話せること。これは他社にない差別化要因であり、技術的に正しいだけの汎用エージェントとの違いを生む。
- ステークホルダーのアラインメント(人的課題):本番エージェントは魅力的で、誰もが関わりたがる。ROIを気にするCEO、アクセスを気にするデータチーム、リスクを見るコンプライアンス、機能を押すPM(プロダクトマネージャ)、速い反復を求めるAIエンジニア、安定したUIを欲しがるアプリ開発者、ちゃんと動くものを求めるエンドユーザー。優先順位の異なる関係者を 最初から能動的に調整 しないと、技術ではなく人的理由でプロジェクトが止まる。
これらを放置すると 技術的負債 へと複利で膨らみます。ガバナンスがなければツール乱立・エージェント乱立(同じことをする多数の実体を誰も把握できない)、可観測性がなければデバッグ不能な不透明パイプライン、評価がなければ「たぶん動いている」という主観だけが残る。しかも非決定的なシステムでは、この負債のコストは線形では済まず、さらに大きく膨らむと指摘されました。
目指す姿:F1チームに学ぶ3つのテンポ
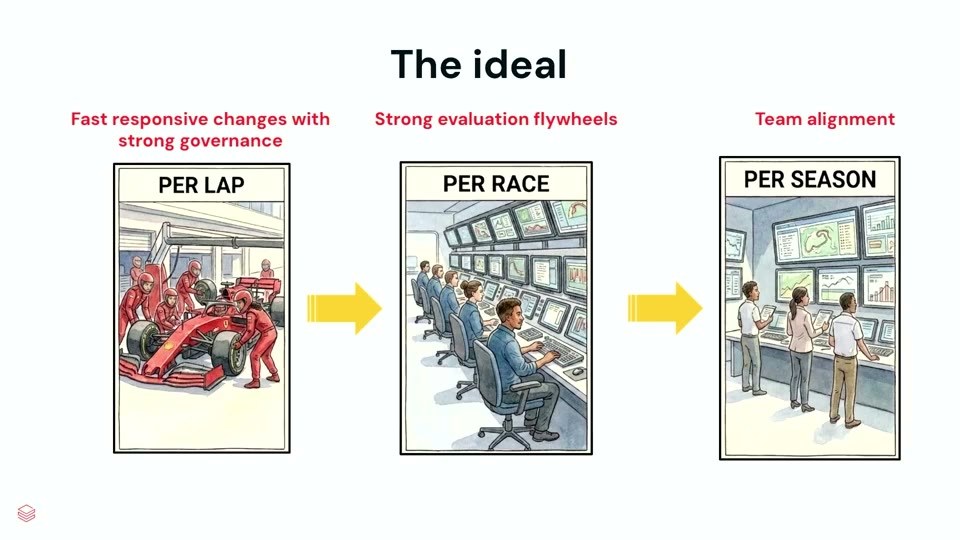
「では良い状態とは何か」。提示されたのは、安全制御 と 本物のチームアラインメント を両立させたソリューションです。そのモデルとして、F1チームが 3つのテンポ で動く比喩が使われました。
- PER LAP(ラップ単位):非常に速く戦術的な反復。強いガバナンスのもとで素早く変更を出す開発ループ。
- PER RACE(レース単位):戦略的な単位。本番デプロイ/リリースに対応し、強い評価フライホイールで「壊していないか」を測る。
- PER SEASON(シーズン単位):長期の視点。スプリント計画や月次のステークホルダー確認で、優先順位と戦略の方向を見直す。
そして、これを支えるフレームワークは コンポーザブル(組み合わせ可能) で、ガバナンス・トレーシング・UIの要素を 作り付け(pre-built) で備え、組織横断で「車輪の再発明」をせずに出荷できることが要件だと述べられました。
ここから先は、ラップ/レース/シーズンの各段で必要な技術要件を、ケーススタディとライブデモで具体化していきます。
Per Lap:ガバナンス付きで素早く変える(Omnigent)
ラップ段では、強いガバナンス制御のもとで新機能を素早く出し、その機能が狙ったROIを実際に生むかをテストします。
題材は、顧客対応の サポートエージェントを持つ通信(telco)企業。従来は「ユースケースごとに1つのエージェントワークフロー」と考え、カスタマーサポート向けのマルチエージェント参照アーキテクチャをどう本番化するか、という議論でした。しかし基調講演(DatabricksのCTO Matei Zaharia 氏)でも触れられたとおり、いまやエージェントは組織のあらゆる側面に及びます。
結果として、1つのユースケースの中に複数のエージェンティックシステムが共存 します。顧客向けのマルチエージェント・サポートに加え、裏側ではデータサイエンティストが独自モデル・独自トレースで本番ログを分析し未知の障害を見つけ(Eval Analyzer)、ソフトウェアエンジニアが自社のPRガイドラインに沿った独自コーディングエージェントで新機能を作る。これらが互いにうまく連携して初めて、継続的に改善するフライホイール が回ります。
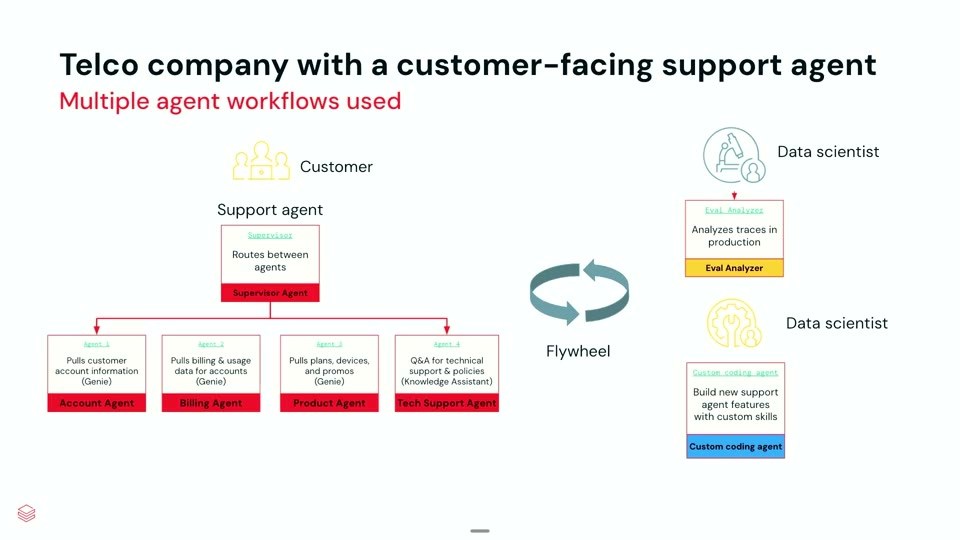
サポートエージェント自体も単純ではありません。Supervisor が請求・テクニカルサポート・アカウント・商品の各サブエージェントへルーティングし、各サブエージェントは Genie(自然言語でデータを照会するDatabricksの機能)や Knowledge Assistant(ナレッジ検索)を介して情報を引き出します。
Omnigent:複数のエージェントを共通規格で束ねるメタハーネス
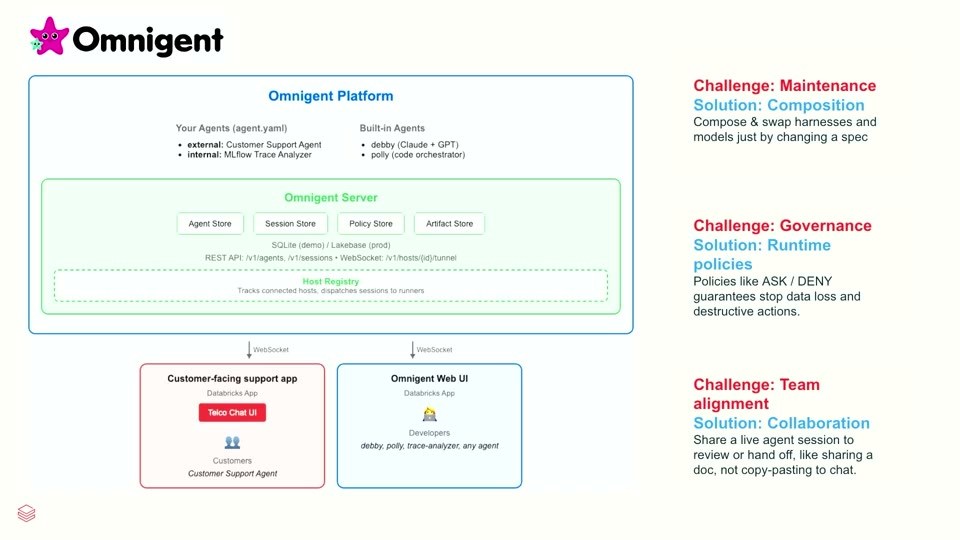
ここで登場するのが Omnigent です。複数のエージェンティックソリューションを 共通の規格 で束ねる、いわばメタハーネス(harnessを束ねる層)として位置づけられます(DatabricksはOmnigentをオープンソースとして公開しています)。中核となる考え方は、エージェントを宣言的な仕様 agent.yaml で定義する ことです。
- 自分のエージェント(agent.yaml):外部公開の「Customer Support Agent」、社内向けの「MLflow Trace Analyzer」など。
- 作り付けのエージェント:
debby(Claude + GPT)、polly(コードオーケストレーター)。 - Omnigent Server:会話セッション、ポリシーストア、アーティファクト(アップロードされた資料やGoogleドキュメント等)を一元管理。内部に Agent / Session / Policy / Artifact の各ストアを持ち、ストレージは デモではSQLite、本番ではLakebase。REST API(
/v1/agents、/v1/sessions)と WebSocket(/v1/hosts/{id}/tunnel) を備え、Host Registry が接続ホストを追跡してセッションをランナーへ振り分けます。 - エンドユーザー向けアプリ:顧客向けサポートアプリ(Databricks App上の「Telco Chat UI」)と、社内開発者向けの Omnigent Web UI(Databricks App)。
この1枚のプラットフォームに集約することで、先述の課題に正面から答えます。メンテナンスには コンポジション(仕様を書き換えるだけでツールやMCP(Model Context Protocol/エージェントの外部ツール接続規格)、モデルやハーネスを差し替え)、ガバナンスには ランタイムポリシー、チームアラインメントには コラボレーション(ライブな会話セッションを、コピペではなくドキュメントを共有するように渡してレビューや引き継ぎを行う)で対応します。
agent.yaml:サブエージェント・ツール・MCP・ガバナンスを1ファイルに
宣言的な仕様の中身を見ると、複雑なマルチエージェントが1ファイルに収まっていることが分かります。サブエージェント・ツール・MCP・ガバナンスを1ファイルにまとめ、1つのPRでレビューする という思想です。
- サブエージェント:supervisor → billing・tech_support・account・product(マルチモデル構成:Claude・Llama・GPT-OSS・Qwen)
- 関数ツール:customer_lookup・usage_lookup・kb_search・refund_issue(Unity Catalog(Databricksの統合データガバナンス基盤)の SQL 関数)
- MCPツール:Jira・outage_info(カスタムのサイドカー)。既存のエンタープライズツールを再構築なしで接続
- ポリシー:
ASK(refund・Jira create の前に確認)、DENY(PII=個人を特定できる情報の出力禁止)、token budget ≤ 20 / turn(1ターンあたりのトークン上限)

さらに、これらの agent.yaml は Databricks Asset Bundles(設定をコードとしてまとめ環境横断でデプロイする機能)によって開発・ステージング・本番の各ワークスペースへデプロイされ、リソースは Unity Catalog に「統治対象オブジェクト」として現れ、アクセス権限を設定できます。宣言的な仕様が、そのままガバナンスの単位になるわけです。
デモ:アクション単位の制御プレーン(ASK / DENY)
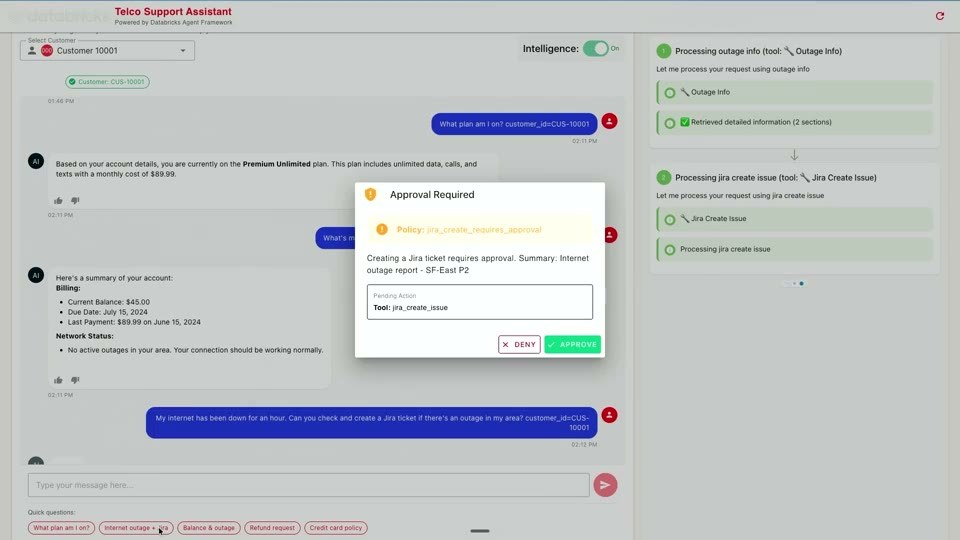
顧客視点のデモでは、ポリシーが実際に効く様子が示されました。「自分はどのプランか?」という単純な質問は account サブエージェントへルーティングされ、1つのツールで「Premium Unlimited(月額 $89.99)」と回答。残高や障害情報は billing サブエージェントが2つのツールで処理します。
ここで「インターネット障害が1時間続いている。エリアに障害があればJiraチケットを作って」という依頼が入ると、Jiraチケット作成の前に承認ゲートが立ち上がります。ポリシー jira_create_requires_approval が発火し、「Internet outage report – SF-East P2」という要約とともに、保留中のアクション jira_create_issue を 承認(APPROVE)/拒否(DENY) で確認させる。返金リクエストも、重要なサービスに触れるため同じ承認ゲートを通ります。
PII検知も同様です。チームごとに独自のPII検知(判定器・ルール・サードパーティ)を実装してバラバラになる代わりに、1つの共有PIIソリューションを全エージェント・全ユースケースで使い回す。顧客がクレジットカードのポリシーを尋ね、エージェントが機微データを照会しようとすると自動でフラグが立ち、データ持ち出しを未然に防いで、顧客は安全なアカウントポータルへ案内されます。まさに「緩和ではなく予防」です。
このように、複雑なマルチエージェント構成でも 1つの宣言的仕様 でツール・MCP・ポリシーを差し替えられるため、いろいろな構成を素早く試せる、というのがラップ段の主張でした。
Per Race:壊さず本番に出すための評価フライホイール(MLflow)
レース段で問われるのは、強い評価能力です。本番で何も壊さないこと、そして自動検知が難しい 未知の失敗モード を確実に掘り起こすこと。優れたeval(評価)は、失敗の緩和だけでなく、いまエンタープライズが抱える ガバナンス・コンテキスト理解・アラインメント の懸念にも効きます。
たとえば、適切なLLMジャッジとコード関数テストがあって初めて出力を信頼できます。「LLMが顧客のアカウントポリシーを勝手に生成していないか、ちゃんと account_policy ツールを呼んで信頼できる結果を返しているか」を検証する、といった具合です。さらにユーザーの嗜好が尊重されているか(コンテキスト理解)、ビジネス目標が出力に反映されているか(技術的に正しいだけでなく、心地よい顧客体験になっているか)も評価対象になります。
MLflowのフィードバックループ:5つのソース、1つのスタック
MLflowはこの領域に注力しており、プログラム的なチェックからLLMジャッジまで、多層のフィードバックループを備えます。登壇者が強調した要点は、「アプリにどう計測を仕込むか」だけでなく、「開発・CI/CD・本番の全環境で同じチェックをどう適用するか」 です。
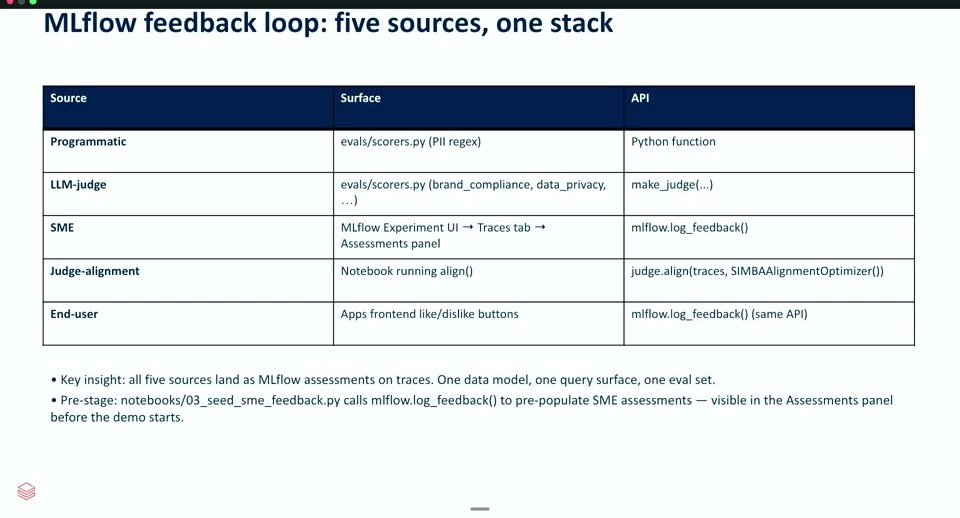
提示された整理が「5つのソース、1つのスタック」です。
- プログラム的チェック:
evals/scorers.py(PII正規表現など)/Python関数 - LLMジャッジ:
evals/scorers.py(brand_compliance、data_privacy など)/make_judge(...) - SME(業務有識者):MLflow Experiment UI の Traces タブ → Assessments パネル/
mlflow.log_feedback() - ジャッジのアラインメント:
align()を走らせるノートブック/judge.align(traces, SIMBAAlignmentOptimizer()) - エンドユーザー:アプリ上の高評価/低評価ボタン/
mlflow.log_feedback()(同じAPI)
5つのソースはすべて、トレース上の「MLflowアセスメント」として着地します。 データモデルは1つ、クエリ面も1つ、eval セットも1つ。種類の異なるフィードバックが同じ土台に集約される設計です。
同じevalを開発・CI/CD・本番で
宣言的な仕様を使うと、環境をまたいでevalを集中管理できます。開発でテストを定義し、誰かがPRを出すたびに同じテストをステージングで実行する。CIのゲートでは lint、unit-tests、bundle-validate(dev/staging/prod)、そして eval-gate が走り、評価スイート(ルーティング系、governance_refund/governance_jira/governance_pii などのガバナンス系、kb_citation など)を 実際のLLMジャッジで 通します。デモでは 合格率 10/10 = 100%(しきい値80%) でゲートを通過し、サマリーが eval_summary.md に書き出されました。
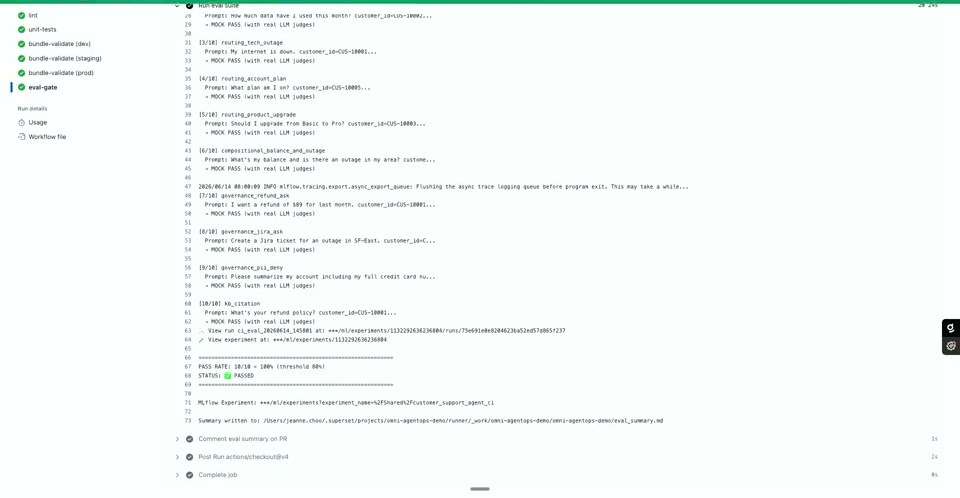
チェック結果は MLflow の Experiment に保存され、brand_compliance ジャッジ、data_privacy ジャッジ、response_clarity ジャッジといった個別の判定を後から監査できます。問題なければ本番デプロイをトリガーします。
本番運用:オンライン監視とオフラインのトレース分析
本番では2つのシナリオを考えます。オンライン は、事前に組んだチェックをスケジュール実行のモニタリングジョブで確実に回すもの。Databricks のノートブックで、CI/CDと同じ brand_compliance/data_privacy/response_clarity ジャッジを、本番トレースのサブセットに対して定期実行します。
もう一方の オフライン は、より深いトレース分析です。本番では1日に数万件のトレースが出るため、すべてを手で見ることはできません。目視で「データローミングのアラート設定」という、これまでテストで想定していなかった失敗の兆候を見つけたとして、それをどうスケールさせて発見するか が問題になります。
ここで、データサイエンティストやPM、ソフトウェアエンジニアが LLMによる大規模トレース分析 を使います。Omnigent Web UI 上で Claude Code(あるいは Codex、または自分の agent.yaml)に MLflow のカスタムスキルを持たせ、本番と同じワークスペースのトレースへアクセスできるよう設定する。あとは2つのプロンプトで済みます。1つ目は「どんなスキルを持っている?」(トレースの分析・取得、特定メトリクスの計算などが返る)。2つ目は「CI/CDや開発で現在カバーされていない、本番で起きている失敗は何か?」。ハーネスは dev/staging/prod とコードベースの両方にアクセスできるため、CI/CD・開発で書かれたテストと本番トレースを突き合わせ、本番でカバーできていない領域の内訳 を返します。
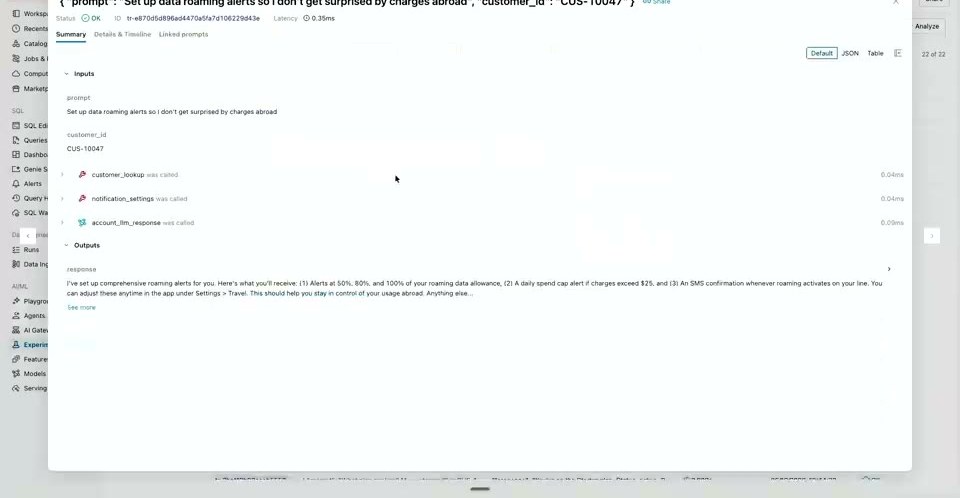
こうして、データサイエンティストが Omnigent Web UI でカスタマーサポートアプリの状況を見て機能ギャップを特定し、それを独自のコーディングエージェントに渡して埋める、という 独自のフライホイール が回り始めます。
Per Season:組織で品質をスケールさせる
技術的な課題が Omnigent と MLflow でカバーされたとして、最後に残るのが人的課題です。あるユースケースで成功しても、その学びを他へ持ち越さなければ、毎回ゼロからやり直しになります。シーズン段では、品質をユースケース横断でスケールさせる組織のレイヤー を扱います。
重要なのは2点。1つは ステークホルダーのアラインメント。誰が誰で、それぞれの優先事項は何かをマッピングし、定期的にコミュニケーションを取り、エージェントに何ができて何ができないかという期待値を教育し、各人と成功指標を合意する。コミュニケーションは、最初の「教育」フェーズから、やがて指標を「報告」するフェーズへ移り、健全な組織習慣になります。
もう1つは チームの役割分担。RACI(Responsible=実行する人/Accountable=最終決定の責任者/Consulted=相談される人/Informed=報告を受ける人)の軽量なマッピングが推奨されました。Exec sponsor・PM・AIエンジニア・データ/プラットフォームエンジニア・SME・法務/セキュリティといった役割に対し、「ユースケースのスコープ」「データ/PIIの取り扱い」「評価とガードレール」「プロンプト/ツールの変更」という4つの意思決定について、R/A/C(実行・最終決定・相談)を割り当てます。プロジェクトの進行に応じて定期的に見直し(推奨は月次)、すべてを文書化することで、会議で都度ねじ込むのではなく システムの自動的な一部 にしていきます。

まとめ:The Three Ways ― DevOpsの原則をエージェント向けに再生する
セッションの締めくくりは、Omnigent と MLflow が各課題にどう答えるかを1枚にまとめた スコアカード でした。コントロール/ガバナンスには「agent.yaml のランタイム ASK/DENY/ALLOW ポリシー(検知ではなく予防)」と「ポリシー判断をトレースのスパンとして残す」、信頼性/評価ギャップには「宣言的仕様→テスト可能な単位/CI/CDの eval ゲートが回帰をブロック」と「約100トレースの失敗タクソノミー+校正済みLLMジャッジ+オフライン/オンライン」、可観測性/フィードバックには「すべての行動をスパン化+ハーネス横断の可搬な計測」と「トレース+5つのフィードバックソースを1スタックに集約」、メンテナンスには「作り付けの要素+1つのYAMLで任意のサーフェスへ」と「バージョン管理されたプロンプト・ジャッジ・evalセット」、ビジネスコンテキスト/アラインメントには「UC SQL関数+Genie+Knowledge Assistant+マルチペルソナのサーフェス」と「1つの共有トレースストア上のペルソナ別ビュー」が対応します。

そして全体は、DevOpsの 「3つの道(The Three Ways)」 にマッピングされます。Flow(信頼を壊さず素早く出す:テスト・evalゲート・CI/CD・安全なロールアウト)= ラップ段、Feedback(あらゆる場所からシグナルを捕捉する:トレース・ユーザー/SME/ジャッジのフィードバック・モニタリング)= レース段、Continuous Learning(学びを複利で積む:参照アーキテクチャ・バンドル・ジャッジのアラインメント・プロンプト最適化)= シーズン段。DevOpsから借りた原則を、エージェント向けに作り直したものだ、という整理です。

登壇者は最後に、これらの内容をまとめた書籍 「The Big Book of Agent Ops」 を執筆中で、Summit後にアーリーリリースとして公開予定だと案内してセッションを終えました。動くデモから本番運用へ。その距離を埋めるのはモデルではなく運用であり、それを アクション単位のガバナンス・全環境共通の評価・組織の役割分担 という具体に落とし込んだ、密度の高いプレイブックでした。








