
LookerはGoogle Cloud Platformのデータ分析プラットフォームで、データ収集から可視化までを簡単に行えます。このブログでは実際のデータを使用し、Lookerでデータを可視化するために必要なModelファイル、Viewファイルの構築方法について解説します。
目次
Lookerとは??
Lookerは、Google Cloud Platformが提供するデータ分析プラットフォームです。データの収集、分析、可視化を簡単に行うことができ、ビジネスの意思決定を支援します。 Lookerは下記のように大きく三つの要素からプロジェクトを構成し、実装されています。- Modelファイル:データセット間の結合など、テーブル単位の定義を行う
- Viewファイル:接続したデータセットの定義を行う
- LookML dashborads:ModelファイルやViewファイルで定義したデータを使って可視化を行う
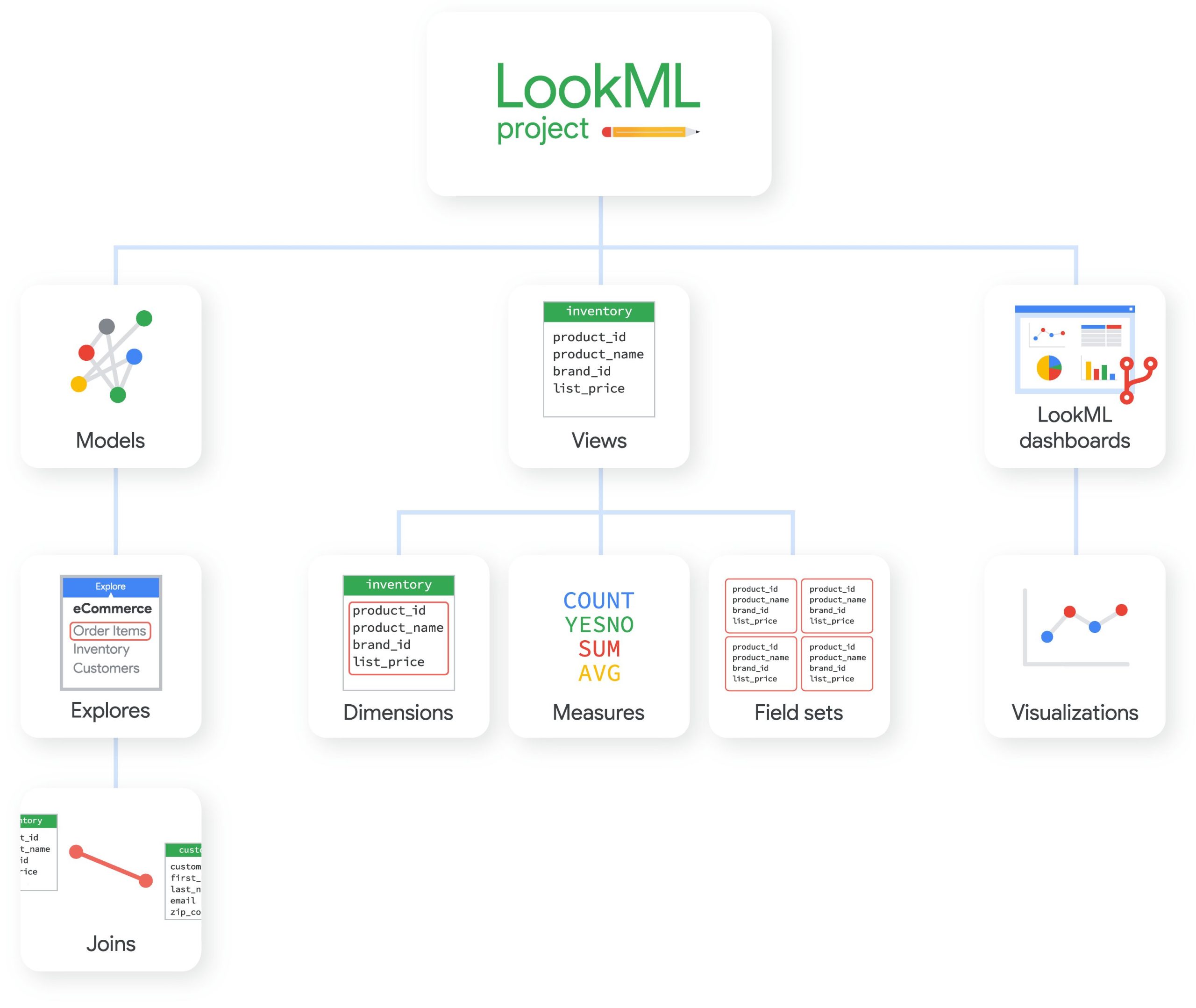 引用:https://cloud.google.com/looker/docs/what-is-lookml
主な実装フローは下記のようになります。
引用:https://cloud.google.com/looker/docs/what-is-lookml
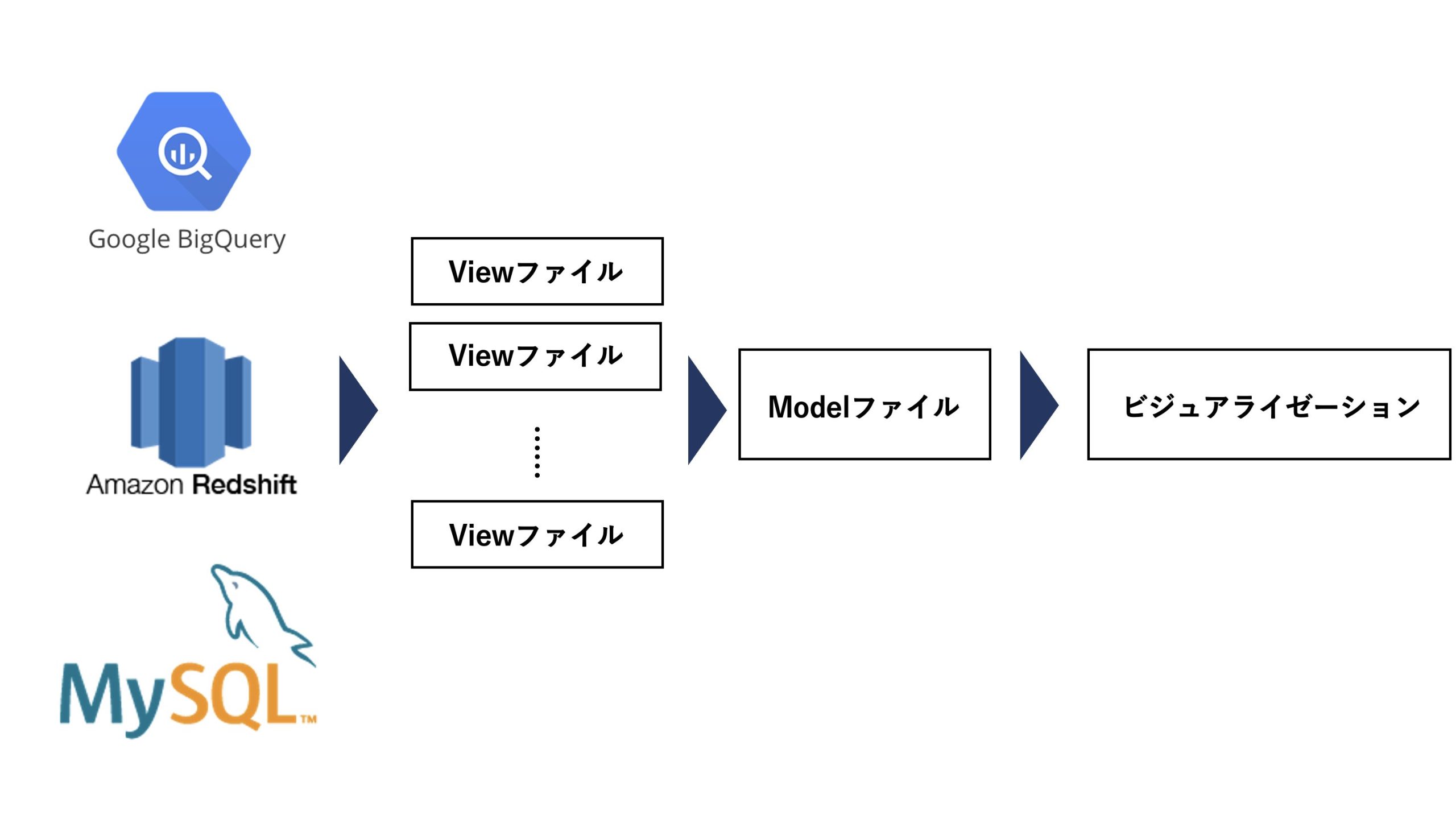
主な実装フローは下記のようになります。
- BigQueryやRedshiftなどのようなDWHやMySQLなどのSQLサーバーとLookerの接続を行う
- Viewファイルを作成し、接続したデータセットをLooker上でどのように扱うかを定義
- ViewファイルをModelファイルで呼び出し、データセットの結合や、どのデータセットを使うかを定義付け
- Modelファイルで定義したデータセットを使用して、表やグラフを描画し、データの可視化
今回扱うデータ
今回、実際のデータを使用してLookerでどのようにデータを可視化するのかを複数のブログに渡って解説していきます。今回、前もってクレンジングした下記データをBigQueryに保存して使用していきます。 https://competition.nishika.com/competitions/nishika-mansion-spring-2023/summary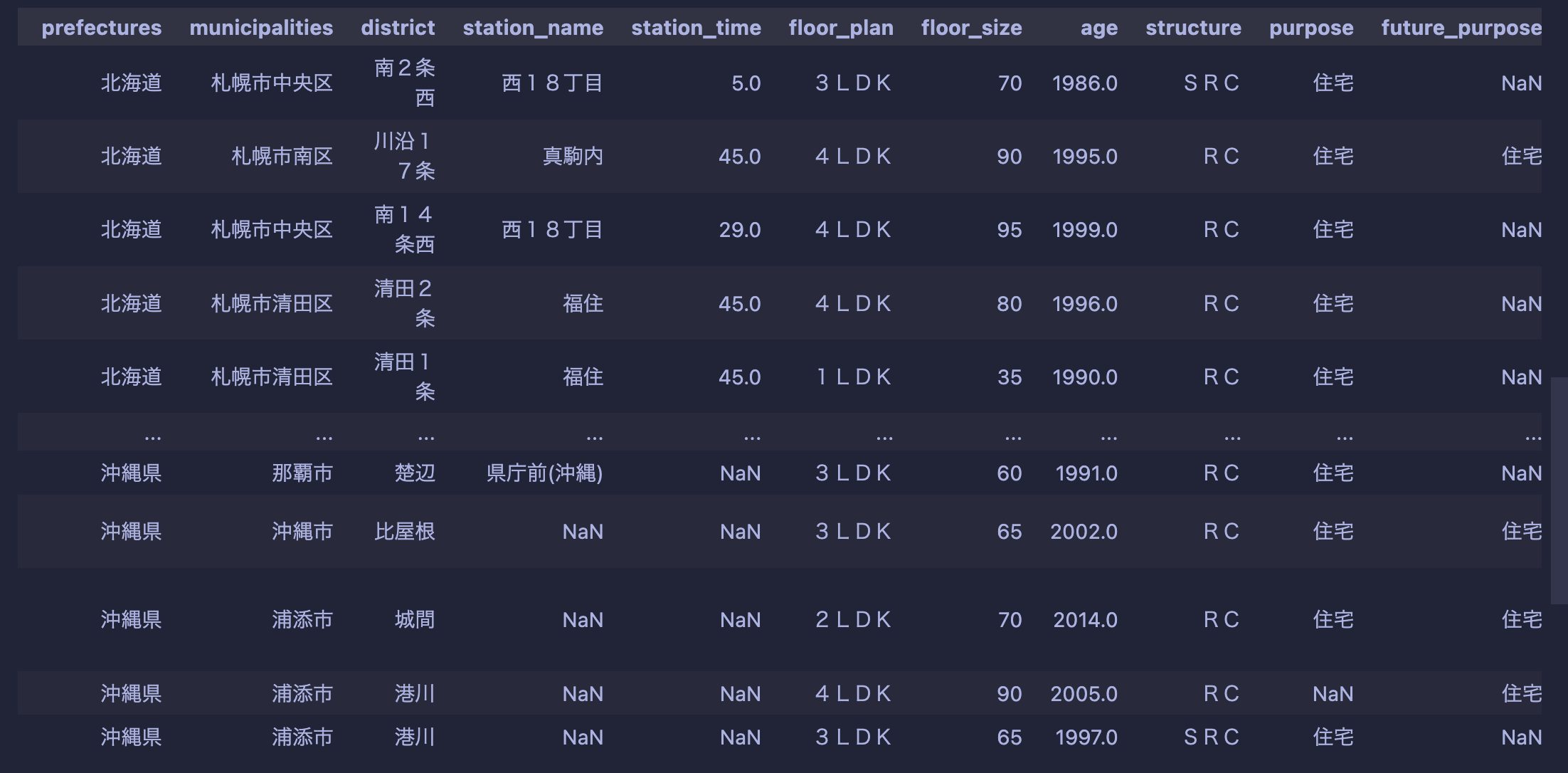
Viewファイルを作成し、データの定義を行う
まず、今回使用するテーブルをLooker上でどのようにして扱うかを定義付けするため、Viewファイルの作成を行います。下記表はViewファイル作成に使用するコードの一例です。下記コードを使ってBigqueryにあるテーブルのデータをLooker上でどのように扱うかを定義します。 下記がViewファイルの実装例です。
下記がViewファイルの実装例です。
view: mansion_dataset {
sql_table_name: `使用したいテーブルのパス`;;
dimension: id {
primary_key: yes
type: number
sql: ${TABLE}.id ;;
}
dimension: city_plan {
type: string
sql: ${TABLE}.city_plan ;;
}
dimension: district {
type: string
sql: ${TABLE}.district ;;
}
dimension: floor_plan {
type: string
sql: ${TABLE}.floor_plan ;;
}
dimension: floor_size {
type: number
sql: ${TABLE}.floor_size ;;
}
}
Modelファイルを作成し、今回扱うViewファイルの定義を行う
次に、Modelファイルの実装をしていきます。Modelファイルでは先ほど作成したViewファイルをどのように扱うかを定義するためのファイルです。 今回は実装しませんが、複数のテーブルをマージして使用したい場合は複数もViewファイルを作成し、Modelファイルでマージ処理の定義を行います。 下記が今回使用するModelファイルです。「connection:~」では、Lookerがどのテーブル、どのプロジェクトと接続するかを宣言します。「include: “/views//*.view”」では作成したViewファイルを読み込むための処理です。今回はviewsというディレクトリ配下にあるViewファイルを全て読み込む仕様になっています。最後に、「explore: 〜 {}」を使用し、読み込んだViewファイルの中で、今回使用するデータセットの宣言を行います。仮に、「include: “/views//*.view”」で読み込んでも「explore: 〜 {}」で宣言しないと、Looker上では扱うことができないので注意です。connection: ""
# include all the views
include: "/views/**/*.view"
explore: mansion_dataset {}まとめ
今回ViewファイルとModelファイルを実装し、BigqueryのデータをLooker上で扱うための環境構築を行いました。次回の記事からは実際にどのようにしてLooker上でビジュアライズを行っていくのかを解説していきます。【Lookerの使い方ガイド】表による可視化










