今回はBigQuery上のデータから同時に購入される商品について分析を行うバスケット分析を行ってみたので、その実装方法をまとめたいと思います。データサイズが大きく使用するメモリを削減した実装を行います。
目次
はじめに
今回はpythonのmlxtendライブラリを用いてBigQueryに保存されたテーブルのデータをバスケット分析しようとしたところ、インターネット上にある多くの方法ではメモリ不足となってしまいました。そこで一部の工程を手で作ることで使用するメモリの削減を行ったので、そのやり方についてまとめたいと思います。なお、Google Cloud のプロジェクトの認証部分についてはブラウザのある環境を前提としています。バスケット分析の各指標について
よく使われる指標については以下のようなものが挙げられます。mlxtendではantecedentsによって、consequentsがどの程度購入されるようになるかという形で出力します。- antecedents: 前提とする商品(群)。
- consequents: 今考えている商品(群)。
- support値: その購入の仕方をした顧客の全顧客に対する割合。
- confidence値: antecedentsを購入したときにconsequentsを購入する条件付き確率。つまり、antecedentsを購入した際に、どれだけの割合がconsequentsを購入するか。
- lift値: confidenceの値をconsequentsを購入する顧客の割合で割った値。antecedentsと一緒にconsequentsを購入した顧客の割合と、単純に全顧客に対するconsequentsを購入する顧客の割合の比なので、antecedentsによってconsequentsがどの程度買われるようになったかを示す。
今回使用したデータ
今回は購入履歴の情報を使いました。各行1つの商品が購入された時の情報を表している状態です。 ここでは以下のようなデータがBigQuery上にあり、これを使用したとしましょう。実際には取引先キーには取引相手を一意に特定できるような、商品名は商品を決定できるような項目です。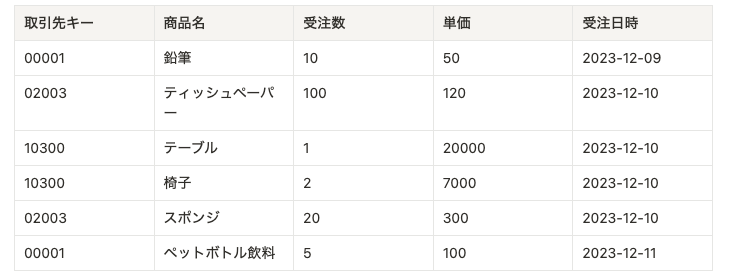 上記の表では同時に複数の商品が購入された場合、商品ごとに別の行に分けられます。また、受注先が同じであっても日時が異なる場合には、同時に購入されているわけではありません。したがって、今回の例では取引先キーと受注日時が同じであるようなすべてのデータを統合した上で、1つのデータとして再構築する必要があります。
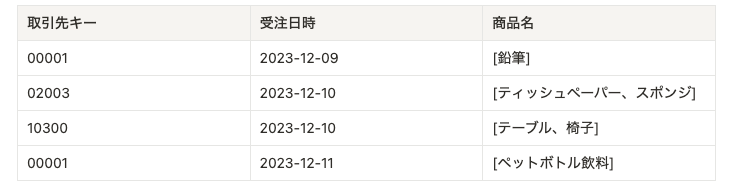
つまり、イメージとしては上記の表を下記のようなものに書き換えてから考えることになります。
上記の表では同時に複数の商品が購入された場合、商品ごとに別の行に分けられます。また、受注先が同じであっても日時が異なる場合には、同時に購入されているわけではありません。したがって、今回の例では取引先キーと受注日時が同じであるようなすべてのデータを統合した上で、1つのデータとして再構築する必要があります。
つまり、イメージとしては上記の表を下記のようなものに書き換えてから考えることになります。
モジュールのimport
使うモジュールはmlxtend、pandas、google.cloudです。import mlxtend
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
from google.cloud import bigquery
import pandas as pdgcloud CLIのインストール(Local環境の場合)
Google Cloudのgcloud CLIから自分のOSにあったもののインストーラーをダウンロードして、インストーラーに従って進みましょう。 その後、使用するテーブルがあるプロジェクトを以下の手順で認証しましょう。 1. `gcloud init`コマンドを使用して初期化する。はじめての場合defaultという設定ができ、その後、ブラウザに飛んで認証を求められるので認証を行う。 2. 複数のGoogle Cloud ProjectがそのGoogle Accountに紐づいている場合には選択が求められるので、使用したいデータのあるプロジェクトを選択する。BigQueryからデータの読み込み
bq_client = bigquery.Client()
query ='Your Query'
base_df = bq_client.query(query).to_dataframe()
base_df['sales'] = base_df['単価'] * base_df['受注数']
threshold = base_df['sales'].quantile(0.85)
processed_df = base_df[base_df['sales'] >= threshold].reset_index(drop=True)時に購入された商品をまとめる
del base_df
tmp_df = (
processed_df.groupby(["取引先キー", "受注日時", "商品名"], dropna=False)["受注数"]
.sum()
.reset_index()
)
del processed_df
grouped_df = (
tmp_df.groupby(["取引先キー", "受注日時"])["商品名"]
.apply(list)
.reset_index()
)
unique_products_group = tmp_df['商品名'].unique()
del tmp_dfmlxtend用のone-hotのテーブル作成
product_columns = {
product: grouped_df["商品名"].apply(lambda x: product in x)
for product in unique_products
}
product_df = pd.DataFrame(product_columns)
del grouped_df, product_columnsバスケット分析の結果出力
freq_items = apriori(
product_df,
min_support=0.01,
use_colnames=True,
max_len=2,
low_memory=True,
verbose=False,
)
df_rules = association_rules(
freq_items,
metric="confidence",
min_threshold=0.0,
)- min_support(必須): support値の最小値を規定します。support値が小さいということはその購入パターンの出現頻度が小さいということになります。この値を定めることでノイズを除去します。
- use_colnames(必須): Trueの場合、引数として取った行列の列成分の値を出力されるデータに使用します。特段の理由がなければTrueでいいでしょう。
- max_len(必須): 同時に考慮する商品の最大数です。2以上の整数値で、2の場合1つの商品に対して別の1つの商品がどれだけ一緒に買われるかのみを表しますが、3以上にすると複数の商品が買われた場合に、別の商品や商品群がどれだけ買われやすいかという多対多の関係まで見れます。
- low_memory: これをTrueにすると、メモリ消費を抑えられる代わりに実行時間が長くなります。
- verbose: 実行中にステータスメッセージを出力するかどうかを制御します。
出力の補正
def convert_frozenset(item):
if isinstance(item, frozenset):
return ', '.join(item)
return item








