
この記事では、MCMC(マルコフ連鎖モンテカルロ法)でサンプリングを行う手順と、Pythonを用いた実際の適用例をご紹介します!
サンプリング手順について
MCMCを使用する際の基本的な手順は以下のようになります。
1. 問題の定式化MCMCを使用する目的を明確にします。例えば、「確率分布からのサンプリング」や「ベイズ統計モデルの事後分布のパラメータ推定」などです。
2. MCMCアルゴリズムの選択「メトロポリス・ヘイスティングス法」、「ギブスサンプリング」、「ハミルトニアン・モンテカルロ」など、適切なMCMCアルゴリズムを選択します。(→アルゴリズムの詳しい説明はこちら)
パラメータ設定
アルゴリズムによって異なりますが、MCMCの主要なパラメータには、「初期値」、「バーンイン期間」、「ステップサイズ」 、「サンプル数」などがあります。
※バーンイン期間とは、アルゴリズムの初期段階で生成されるサンプルを、分析から除外する期間のことです。バーンイン期間が短すぎると、未収束のサンプルが分析に含まれるリスクがあります。一方で、長すぎると有用なサンプルを失うことになります。
3. サンプリングの実行初期値を設定した後、選択したアルゴリズムに従って、目的の分布からサンプルを生成します。
4. 収束の確認生成されたサンプルが目的の分布に収束しているかを評価します。
5. 結果の分析- バーンイン期間サンプルの除外:初期のサンプルを排除します。
- 事後分布の分析(必要な場合):収束したサンプルを使用して、推定したいパラメータの事後分布を分析します。
実際にPythonで実装してみよう!
先ほどの5つのステップに則って、実際にサンプリングを行いたいと思います。
ここでは、簡単な統計モデル(ベイジアン線形回帰モデル)を取り上げ、MCMCを用いた事後分布のパラメータ推定を行うことを目標とします。
1. 問題の定式化
今回は、線形回帰モデルのパラメータ(傾きと切片)を推定することを目的とします。
モデル式は次のとおりです。
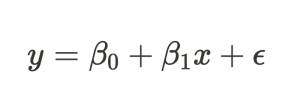
(ϵ は誤差項で、正規分布に従うと仮定)
上式において、今回は真のパラメータを
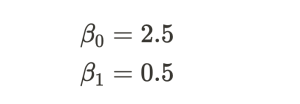
と設定することにします。
はじめにライブラリのインポートと、仮想データの生成を行います。
import numpy as np import scipy.stats as stats import matplotlib.pyplot as plt #random.seedを設定 np.random.seed(0) # 仮想データを作成 x = np.linspace(0, 10, 100) y = 2.5 + 0.5 * x + np.random.normal(scale=1.0, size=100)
2. MCMCアルゴリズムの選択 および 3. サンプリングの実行
今回は、メトロポリス・ヘイスティングス法を選択します。
下記のコードでは、
- 現在のパラメータ値から新しい値を提案(正規分布を使用)
- 提案された値の受理確率を計算し、ランダムに受理/拒否を決定。
- このプロセスを5000回繰り返す
ということが行われています。
# メトロポリス・ヘイスティングス法
def metropolis_hastings(lr, iterations, x, y):
beta_0 = 0
beta_1 = 0
sigma = 1
samples = []
for i in range(iterations):
beta_0_proposal = np.random.normal(beta_0, lr)
beta_1_proposal = np.random.normal(beta_1, lr)
sigma_proposal = np.random.normal(sigma, lr)
likelihood_current = np.sum(stats.norm.logpdf(y, beta_0 + beta_1 * x, sigma))
likelihood_proposal = np.sum(stats.norm.logpdf(y, beta_0_proposal + beta_1_proposal * x, sigma_proposal))
prior_current = stats.norm.logpdf(beta_0, 0, 10) + stats.norm.logpdf(beta_1, 0, 10) + stats.halfnorm.logpdf(sigma, 0, 1)
prior_proposal = stats.norm.logpdf(beta_0_proposal, 0, 10) + stats.norm.logpdf(beta_1_proposal, 0, 10) + stats.halfnorm.logpdf(sigma_proposal, 0, 1)
#受理確率
p_accept = np.exp(likelihood_proposal + prior_proposal - likelihood_current - prior_current)
if np.random.rand() < p_accept:
beta_0, beta_1, sigma = beta_0_proposal, beta_1_proposal, sigma_proposal
samples.append([beta_0, beta_1, sigma])
return np.array(samples)
# MCMCを実行
samples = metropolis_hastings(0.05, 5000, x, y)4. 収束の確認
本来なら、次に収束判定を行いますが、ここではコードが長く複雑なものになってしまうため、省略します。
5. 結果の分析
# バーンイン期間を取り除く
burn_in = 500
post_burn_in_samples = samples[burn_in:]バーンイン期間の除外後、残りのサンプルを使用して、β0 と β1 の事後分布を分析します。
plt.figure(figsize=(12, 6))
# beta_0の事後分布
plt.subplot(311)
plt.hist(post_burn_in_samples[:, 0], bins=30, density=True)
plt.title('Posterior of $\\beta_0$ After Burn-in')
# beta_1の事後分布
plt.subplot(312)
plt.hist(post_burn_in_samples[:, 1], bins=30, density=True)
plt.title('Posterior of $\\beta_1$ After Burn-in')
#事後分布の平均を求める
mean_beta_0 = np.mean(post_burn_in_samples[:, 0])
mean_beta_1 = np.mean(post_burn_in_samples[:, 1])
print(mean_beta_0, mean_beta_1)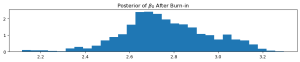
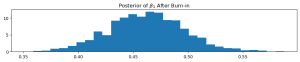
MCMCでサンプリングした事後分布の平均は、
print(mean_beta_0, mean_beta_1)にて出力しています。その結果は、
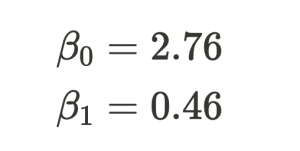
となりました。
はじめに、真のパラメータは、
と設定しましたので、サンプリングにより、真のパラメータに比較的近いものが得られたのではないでしょうか。
以上、Pythonを用いてMCMCでサンプリングを行う方法をご紹介しました。今回は、アルゴリズムをより深く理解するために、ライブラリは用いずに関数を定義しましたが、ライブラリPyMC3を使うと簡単に実装できます。










