
VertexAIの予測モデル構築で、COVID-19の新規陽性者数データを読み込ませた特微量を反映してみた
目次
AutoMLのモデル評価
VertexAIのAutoMLにてモデルの構築を行いトレーニングが終了したのでその結果考察を行います。 出てきた値の意味なども解説しているので、それぞれのモデルを解釈する際の一例としてご覧ください。 今回は飲食店の売り上げデータを使用してモデルを作成しました。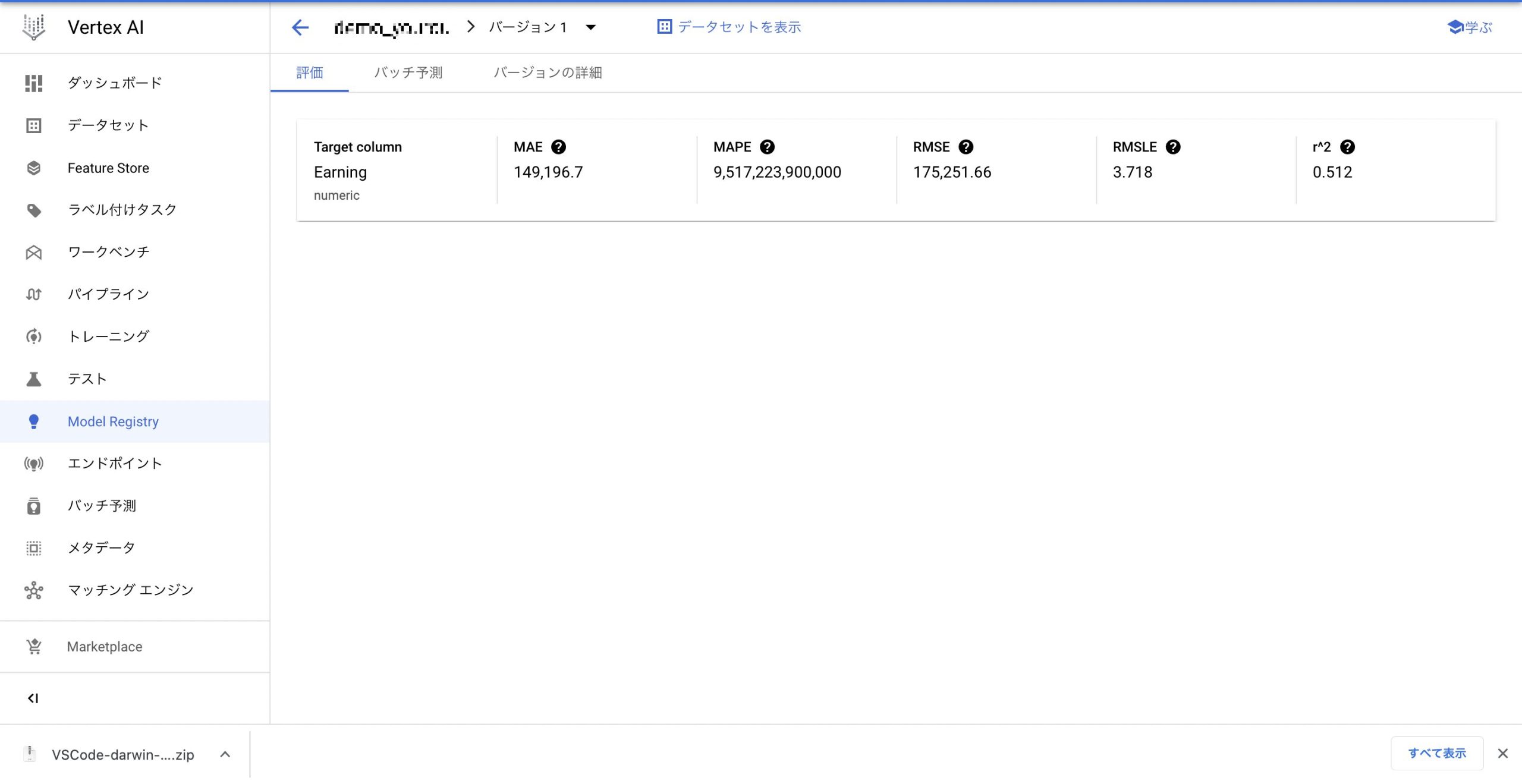 それぞれの値の意味と解釈は以下の通りです。
それぞれの値の意味と解釈は以下の通りです。
- MAE: 予測値と正解値の差の絶対値の平均
- 意味:予測に対して平均で約14万円の誤差のあるモデル
- 解釈:最大売上金額が100万円台を考えると現実的な誤差
- MAPE: 予測値と正解値の差を正解値で割った絶対値の平均(通常割合で表示される)
- 意味:今回のモデルについてはなし
- 解釈:グランドトゥルースデータ(推論ではなく実際のデータ)に0が含まれており、0の除算が生じてしまうため、この場合解釈できない
- RMSE:予測値と正解値の差の2乗の平均の平方根
- 意味:予測に対して平均で約17万円の誤差があるモデル
- 解釈;外れ値をより大きく扱う傾向にある(営業時間短縮で0の売り上げがあるためこの辺が影響した可能性あり)
- r^2:決定係数:、残差の二乗和を標本値の平均値からの偏差の二乗和で割ったものを1から引いた値
- 意味:モデルの当て当てはまり具合を評価した数値で0~1を取る。一般に決定係数0.5以上で高精度、0.64以上で非常に高精度とされる
- 解釈:今回、0.512で制度としては高くない。外的要因がノイズになっている可能性がある。
特徴量の追加
今回のデータでは特徴量が不足していたため、オープンデータから特徴量を追加していく。 飲食店の売り上げの特徴量となりそうなデータとして、COVID-19の感染者数を使用する。 総務省から新規陽性者数の変異をDLし、データセット作成する。
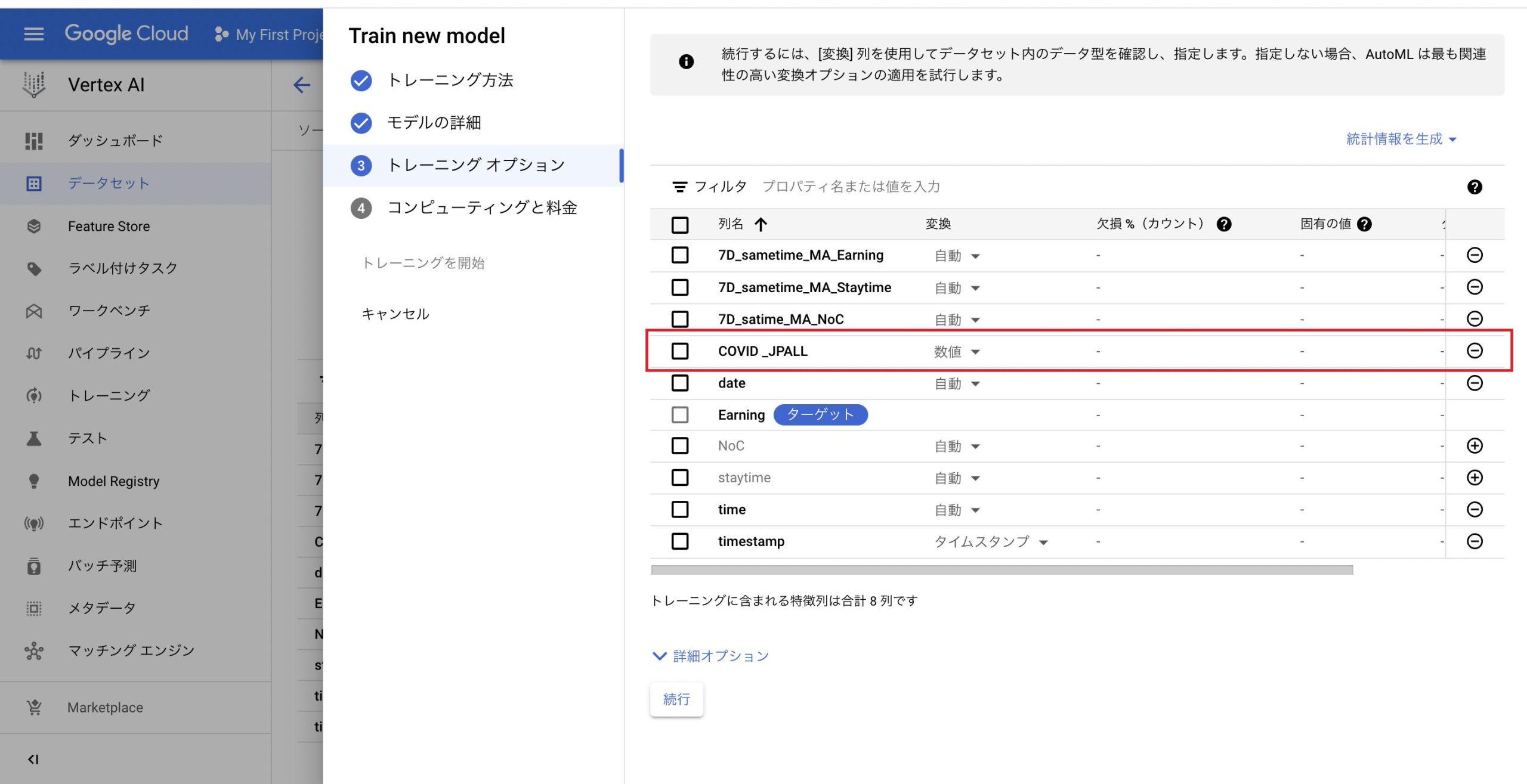
これで新規陽性者数を特徴量として含めるかどうかでモデルの違いを見る。
値をモデルトレーニングに使用するかどうかは、画面右の「-」で変更することができる。
総務省から新規陽性者数の変異をDLし、データセット作成する。
これで新規陽性者数を特徴量として含めるかどうかでモデルの違いを見る。
値をモデルトレーニングに使用するかどうかは、画面右の「-」で変更することができる。
特微量追加後のモデルの解釈
コロナの新規陽性者数を特微量として含めた場合のそうでない場合のモデルを比較する。 コロナあり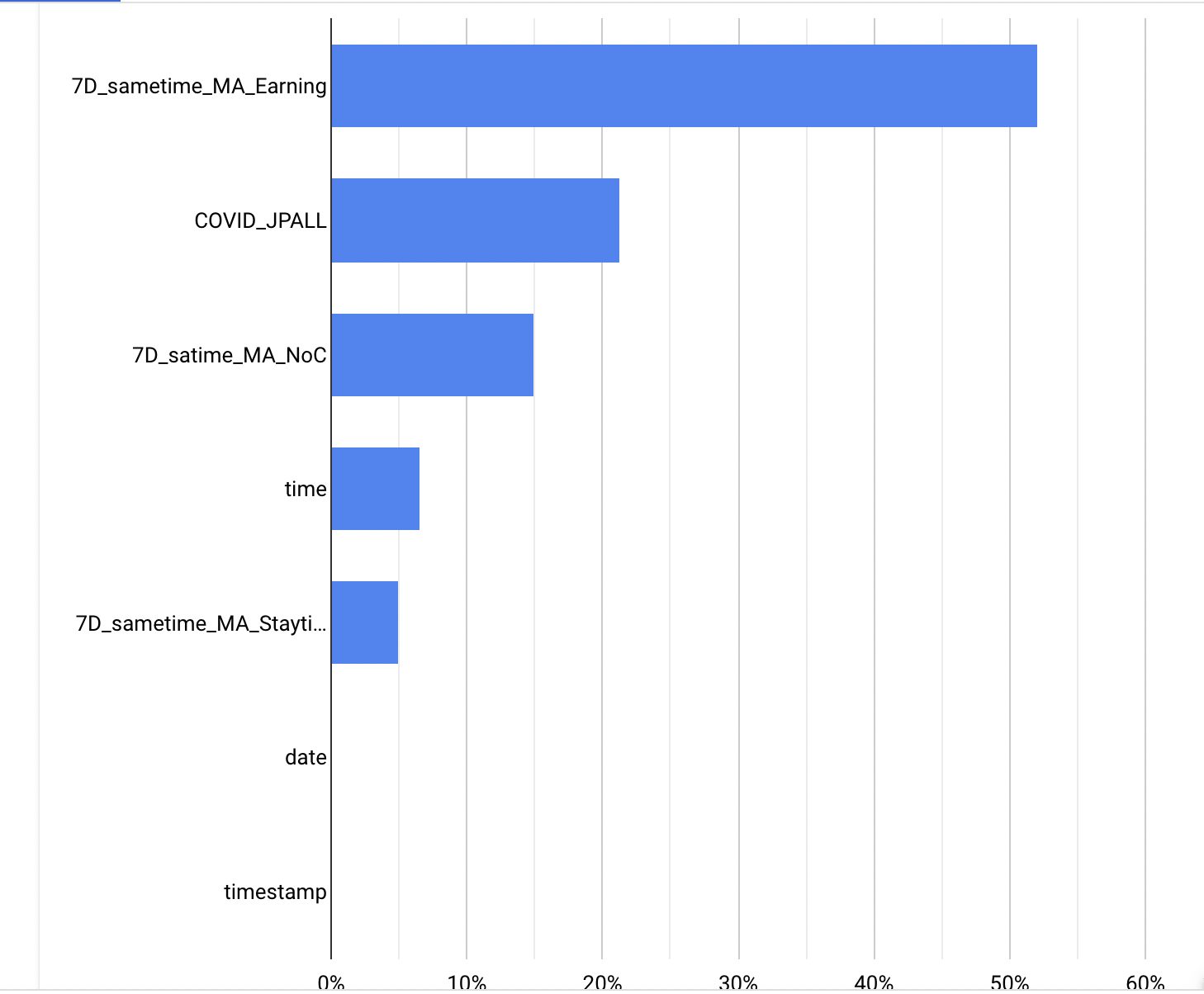 コロナなし
コロナなし
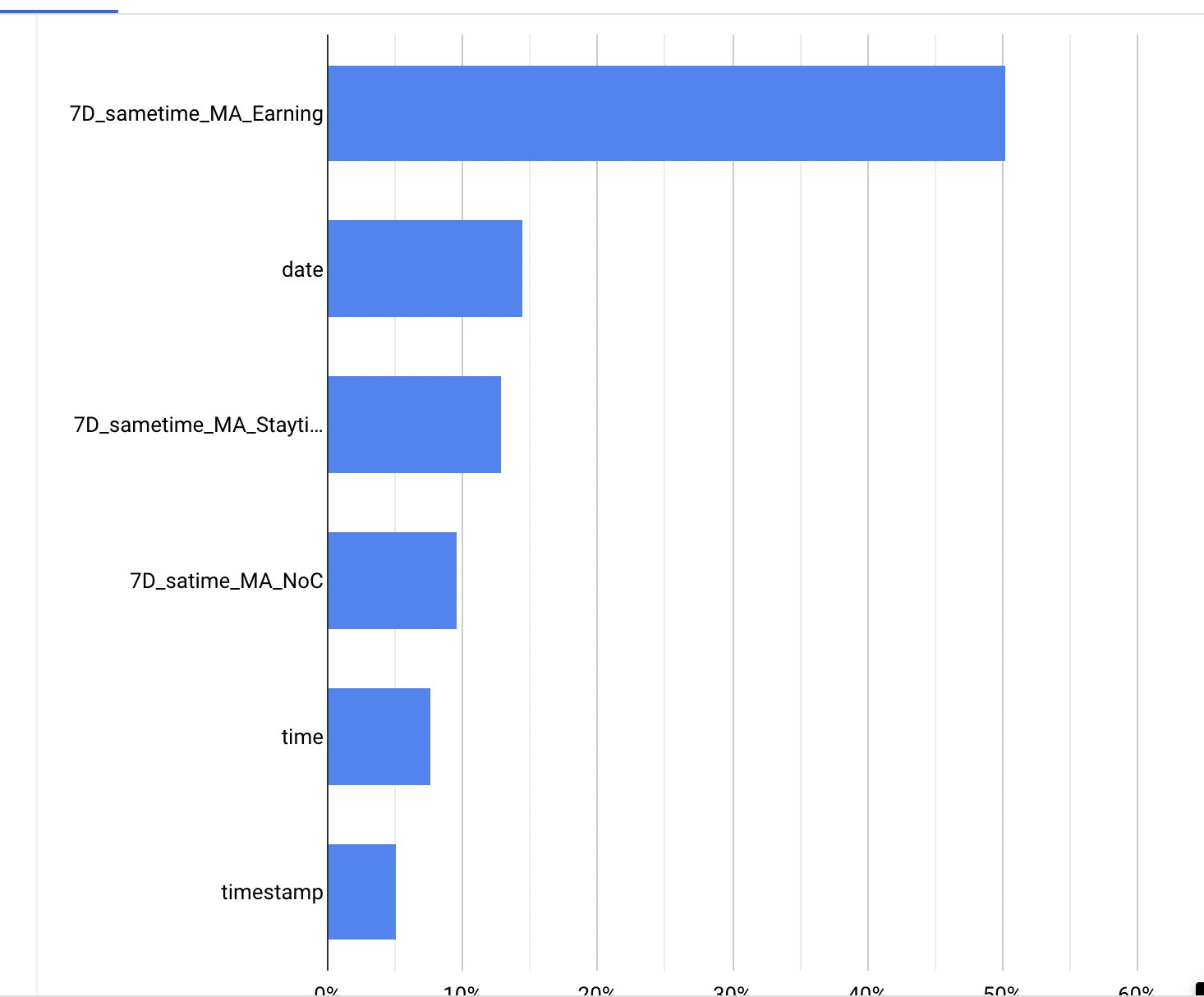 これは特微量の重要度を表しているが、重要ではあるがほかの値の特微量の方が重要度が高いという結果になった。
実際に使える特微量とは?
Google Cloudのこの資料から考えます。
https://lp.cloudplatformonline.com/rs/808-GJW-314/images/InsideSaaS-Google0701.pdf
この資料を見ると、実際に使えそうな特微量は
・天気予報
・立地、店舗規模(多店舗データでトレーニングした場合)
・営業時短要請のフラグ
・コロナ感染者数の予測値
・休祝日
などがあります。
今後の課題
・上記の資料などから、適切な特微量を検証し見つけていくこと。
・今回は売り上げデータでのモデル作成であり、1つの店舗しか使用していなかった。この店舗数を増やすことによってモデルの精度の向上を目指す。
これは特微量の重要度を表しているが、重要ではあるがほかの値の特微量の方が重要度が高いという結果になった。
実際に使える特微量とは?
Google Cloudのこの資料から考えます。
https://lp.cloudplatformonline.com/rs/808-GJW-314/images/InsideSaaS-Google0701.pdf
この資料を見ると、実際に使えそうな特微量は
・天気予報
・立地、店舗規模(多店舗データでトレーニングした場合)
・営業時短要請のフラグ
・コロナ感染者数の予測値
・休祝日
などがあります。
今後の課題
・上記の資料などから、適切な特微量を検証し見つけていくこと。
・今回は売り上げデータでのモデル作成であり、1つの店舗しか使用していなかった。この店舗数を増やすことによってモデルの精度の向上を目指す。 







