機械学習モデルの性能は、どの特徴量(説明変数)を使うかで大きく左右されます。本記事では 特徴量選択(feature selection) の全体像を整理し、分類タスクを題材に scikit-learn を用いた実装例も紹介します。
特徴量選択とは
特徴量選択は、与えられた候補特徴量集合 から、目的変数 の予測や説明に有用な特徴量の部分集合 を選ぶ問題です。こうしたシンプルなモデルを目指す発想は、「ある事柄を説明するためには、必要以上に多くの仮定をするべきではない」というオッカムの剃刀の原則に基づいています。
目的は大きく次の4つに整理できます。
- 汎化性能の向上:ノイズ的な特徴量を除くことで過学習を抑える
- 計算量の削減:学習や推論を軽くする
- 解釈性の向上:重要な特徴量が何かを理解しやすくする
- 次元の呪いの緩和:学習に必要なデータ量(サンプル数)の増加を抑えられる
特徴量選択手法は、特徴量の評価・選択の観点から大きく フィルタ法 / ラッパー法 / 組み込み法 の3つに分類できます。(このほか、各手法を組み合わせて精度と高速性を両立するハイブリッド法も存在します。)
フィルタ法(Filter Method)
フィルタ法は、モデルに依存せずに特徴量を評価・選択する手法です。具体的には、統計的指標を用いて各特徴量のスコアを計算し、特徴量ランキングを作成します。そのうえで、上位 個だけを残したり、あらかじめ決めた閾値を下回るものを除外したりします。
主な評価観点は次の3つです。
①関連性(Relevance):目的変数との関連が強い特徴量ほど有用
②冗長性(Redundancy):他の特徴量と類似している場合はどちらかを除外
③安定性(Stability):分散が極端に小さいなど、情報量が乏しい特徴量は除外
具体的な評価方法には、以下のようなものがあります。どの評価方法を選ぶべきかは、説明変数と目的変数の関係やデータの種類によって変わります。線形関係があるか、離散値 or 連続値か、正規分布を仮定できるかなどを確認する必要が出てきます。
・相関係数
・分散
・相互情報量
・ANOVA
・カイ二乗検定
基本的には上記のような評価指標を単独で使って各特徴量のスコアを算出します。ただし、より発展した手法として mRMR や Relief などが存在します。mRMR は目的変数との関連性を高めつつ、特徴量同士の冗長性を抑えるように特徴量を選びます。Relief は近傍(似たサンプル)同士を比較し、クラスが変わると値も変わりやすい特徴量を高く評価します。
メリット
・高速でシンプル
・モデルを選ばず使える
デメリット
・特徴量同士の相互作用や、モデル固有の適合性を直接反映しにくい
・閾値(どのスコア以上を残すか、何個残すか)の設定が難しいことがある
ラッパー法(Wrapper Method)
ラッパー法は、実際に機械学習モデルを使用することで特徴量の部分集合を評価する手法です。つまり、ラッパー法では最適な特徴量の集合を決定するまでにモデルの学習と特徴量の評価を何度か繰り返すことが必要です。例えば、全探索を例に出すと、全ての特徴量がA,B,Cの3つであるとき、回の学習が必要になります。(一般に特徴量数が なら回)
部分集合を探索する方法の代表例としては、次のようなものがあります。
・逐次前進選択法(SFS)
・逐次後退選択法(SBS)
・再帰的特徴削減(RFE)
・遺伝的アルゴリズムなどの進化計算
メリット
・モデルの性能に直結する特徴量集合を選びやすい
・特徴量同士の相互作用を選択に間接的に取り込める
デメリット
・計算コストが高い(特徴量集合の評価毎にモデル学習が必要)
・あるモデルに依存した特徴量集合しか獲得できない
組み込み法(Embedded Method)
組み込み法は、モデルの学習プロセスの一部として、特徴量の選択や重み付けを自動的に行う手法です。例えば、正則化によって重みが 0 に近づく(スパース化する)場合や、決定木系のように学習過程での分割への寄与(不純度減少など)を集計して、特徴重要度を算出できる場合があります。
組み込み法の具体例は次のとおりです。
・Lasso(L1正則化)
・Elastic Net(L1 + L2 の正則化)
・決定木(DT)
・ランダムフォレスト(RF)
メリット
・フィルタ法より性能を意識しつつ、ラッパー法より計算が軽いことが多い
・学習と同時に選択でき、実装・運用がシンプルになりやすい
デメリット
・ハイパーパラメータ(正則化強度など)に敏感で、調整が必要
・木系の重要度は相関の強い特徴量があると評価が歪むことがある
SHAP / LIME ベースの特徴選択
ここまで紹介した3分類とは別に、SHAP や LIME を用いたアプローチもあります。 SHAP / LIME は、モデルの予測結果に対する各特徴量の寄与(重要度)を定量化・可視化するモデル解釈(XAI)のための手法です。これらを用いて得られた重要度をもとに特徴量選択へ応用することが可能です。 ただし、これらの重要度はあくまで学習済みモデルの挙動を反映したものであり、特徴量集合を変えて再学習する評価(ラッパー法)とは性質が異なります。特徴量選択への応用は可能ですが、主目的はモデルの予測根拠の説明である点を意識して解釈することが重要です。
各手法の精度と計算コスト
これらの関係は、データやモデル、指標の選び方によって変わりますが、ここではあくまで目安として整理します。
| 手法 | 精度 | 計算コスト |
| フィルタ法 | 低〜中 | 低 |
| 組み込み法 | 中〜高 | 中 |
| ラッパー法 | 中〜高 | 高 |
実装
ここでは、分類タスク(2値分類)を想定して、代表的な方法を scikit-learn で実装する例を示します。実装した手法はMI、RFE、RFです。
1. MI(フィルタ法)
特徴量と目的変数の依存度(非線形関係も含む)を相互情報量で評価する手法
2. RFE(ラッパー法)
係数などを基準にしたモデルの再帰的な訓練による手法
3. RF(組み込み法)
ランダムフォレストで得られる重要度(不純度減少ベース)に基づく手法
!pip install japanize-matplotlib
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_selection import SelectKBest, mutual_info_classif, RFE, SelectFromModel
# データ
data = load_breast_cancer()
X = data.data
y = data.target
# 評価設定
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
k_values = [5,10,15,20,25,30]
mi_scores = []
rfe_scores = []
rf_scores = []
for k in k_values:
# 1. MI: フィルター法
mi_pipeline = Pipeline([
("select", SelectKBest(mutual_info_classif, k=k)),
("scale", StandardScaler()),
("model", LogisticRegression(max_iter=3000))
])
mi_score = cross_val_score(
mi_pipeline, X, y, cv=cv, scoring="accuracy"
).mean()
mi_scores.append(mi_score)
# 2. RFE: ラッパー法
rfe_pipeline = Pipeline([
("scale", StandardScaler()),
("select", RFE(
LogisticRegression(max_iter=3000),
n_features_to_select=k
)),
("model", LogisticRegression(max_iter=3000))
])
rfe_score = cross_val_score(
rfe_pipeline, X, y, cv=cv, scoring="accuracy"
).mean()
rfe_scores.append(rfe_score)
# 3. RF: 組み込み法
rf_pipeline = Pipeline([
("select", SelectFromModel(
RandomForestClassifier(n_estimators=300, random_state=42),
threshold=-np.inf,
max_features=k
)),
("scale", StandardScaler()),
("model", LogisticRegression(max_iter=3000))
])
rf_score = cross_val_score(
rf_pipeline, X, y, cv=cv, scoring="accuracy"
).mean()
rf_scores.append(rf_score)
# グラフ
plt.figure(figsize=(10, 6))
plt.plot(k_values, mi_scores, marker="o", label="MI")
plt.plot(k_values, rfe_scores, marker="o", label="RFE")
plt.plot(k_values, rf_scores, marker="o", label="RF")
plt.xlabel("選択した特徴量数", fontsize=14)
plt.ylabel("正解率", fontsize=14)
plt.title("特徴選択手法の比較", fontsize=16)
plt.legend(frameon=True, edgecolor="black")
plt.grid(False)
plt.show()結果
- 横軸:選択した特徴量数
- 縦軸:交差検証で得られた正解率の平均
- 3本の線:MI(フィルタ法) / RFE(ラッパー法) / RF(組み込み法)の比較
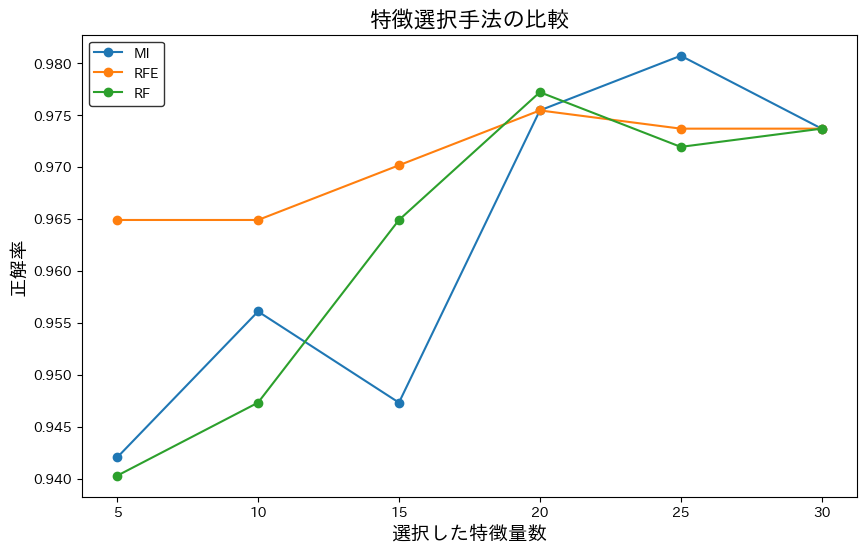
結果は上記の通りになりました。今回は、選択する特徴量数(k)を変化させたときの 正解率の推移を比較しています。 全体として、いずれの手法でも k=20 前後で正解率が向上する傾向が見られました。 手法別に見ると、MI は特徴量数がある程度多いときに精度が伸びやすく、RFE は全体的に安定した正解率を示しました。RFはMIに似た挙動を示しましたが、精度検証はロジスティック回帰で行っているため、今回は参考程度に捉えます。
まとめ
特徴量選択は、汎化性能の向上、計算量の削減、解釈性の改善などを目的に、利用する特徴量を絞り込む考え方です。手法は大きく フィルタ法 / ラッパー法 / 組み込み法 の3つに整理でき、それぞれ「評価の基準」や「探索の仕方」が異なります。なお、今回の実験結果は breast_cancer データでの一例であり、データの次元数・相関構造・サンプル数などによって、最適な手法や特徴量数は変わります。実務では、精度指標だけでなくドメイン知識やビジネス上の要件も踏まえ、適切な特徴量を選ぶことが重要です。