来場3万人を超え、スポンサー240社超で開かれたData + AI Summit 2026。そのキーノートで、いちばん地味で、いちばん根が深いテーマが扱われた。データを置く「箱」の話だ。
考えてみてほしい。分析するためのシステムと、取引を処理するためのシステム。多くの企業は、この二つを別々に抱えている。注文を受ける、在庫を引く、決済を通す——こうしたミリ秒単位で確実に捌く仕事は片方が担う。売上を集計する、傾向を見る、レポートを作る、という大量データの分析はもう片方が担う。そして両者の間を、データをコピーして埋める。夜間にバッチでごっそり移したり、専用のリアルタイム層に流し込んだり。
この「分析用と取引用は分ける。だからコピーする」という発想。ほぼ40年続いてきた業界の通説だ。スライドの言葉を借りれば “Accepted wisdom(受け継がれてきた常識)”。Summitでは、その常識そのものを壊す発表が二つ並んだ。
この記事は、その二つを軸に進む。①なぜ「2つの島」に分けてきたのか → ②分析側を変えるLakehouse//RT → ③取引側を変えるLakebase → ④止まっても切り替えられる仕組み → ⑤両者をひとつに束ねるLTAP、という順に見ていく。

これまでは“2つの島”だった
なぜ二つに分けてきたのか。求められる性質が真逆だからだ。
取引処理は、一件一件を取りこぼさず、しかも速く返す必要がある。注文ボタンを押して数秒待たされたら客は離れる。分析は逆に、数千万・数億行をまとめて舐めて答えを出す。両方を一台でやろうとすると、どちらかが必ず割を食う。だから島を二つに分け、間をコピーでつないできた。
ただ、このコピーには代償がある。まず鮮度。コピーした瞬間からデータは古くなる。「今この瞬間の在庫」を見ているつもりが、実は数十分前の姿だった、ということが起きる。次に手間。コピーの仕組みそのものを誰かが作り、動かし、壊れたら直す。最後に統制。同じ数字が二つの島に存在すると、どちらが正なのか分からなくなる。誰がどのデータに触れていいかというルールも、島ごとに作り直すことになる。
スライドでも、右側のリアルタイム層の欠点として「データが鮮度を失う」「単純なクエリしか投げられない」「ガバナンスが崩れる」が赤い×で挙げられていた。便利そうに見える専用層ほど、こうした副作用を抱えている。
Lakehouse//RT——データを動かさず、超高速に分析する
一つ目の答えが Lakehouse//RT。エンジンには Reyden(レイデン)という名前が付いている。
考え方はシンプルだ。データを専用の箱にコピーしてから速くするのではなく、レイク(社内データを貯めておく場所)の上で、置いたまま直接、超高速に分析する。コピー前提だった発想を、まるごとひっくり返す。

数字も出た。1秒間に12,000件のクエリが押し寄せても、応答は100ミリ秒(0.1秒)を切る。専用の配信基盤と比べて最大16倍の速さだという。さらに、分析系データベースの性能を測る業界標準のテスト「TPC-H」を1TB規模に拡張した検証では、競合2社が「Failed」——途中で処理しきれず脱落——と表示されたのに対し、Databricks側は走り切った。机上のベンチマークでも、次に見る実顧客の実測でも、というわけだ。
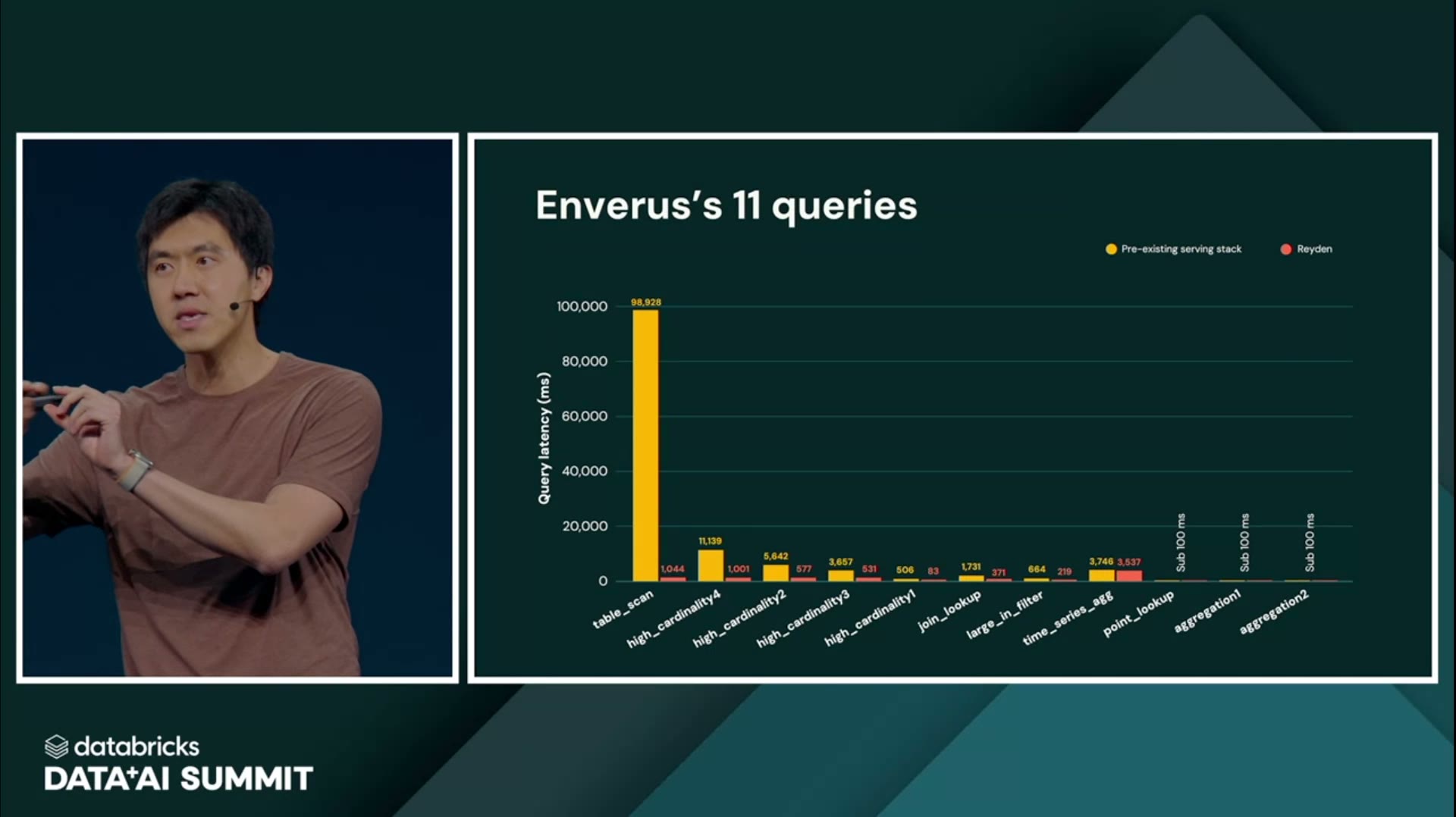
念のため、ここで言う「速い」は体感の話ではなく、実測の応答時間だ。約99秒かかっていた重いクエリが約1秒に縮む、というのは、桁が二つ違う。ダッシュボードを開くたびにコーヒーを淹れに行っていた人が、瞬時に画面を見られるようになる、という距離感だ。
Lakebase——使う時だけ立ち上がる、レイク上のPostgres
二つ目が Lakebase。こちらは取引処理の側を受け持つ、フルマネージドのサーバーレス Postgres だ。
Postgres(PostgreSQL)は、世界中で広く使われている定番のデータベース。「互換」なので、これまでPostgresで書いてきた資産をそのまま活かせる。「フルマネージド」は、運用の面倒をDatabricks側が見てくれるという意味。「サーバーレス」は、サーバーの台数を自分で見積もって用意しなくていい、という意味だ。
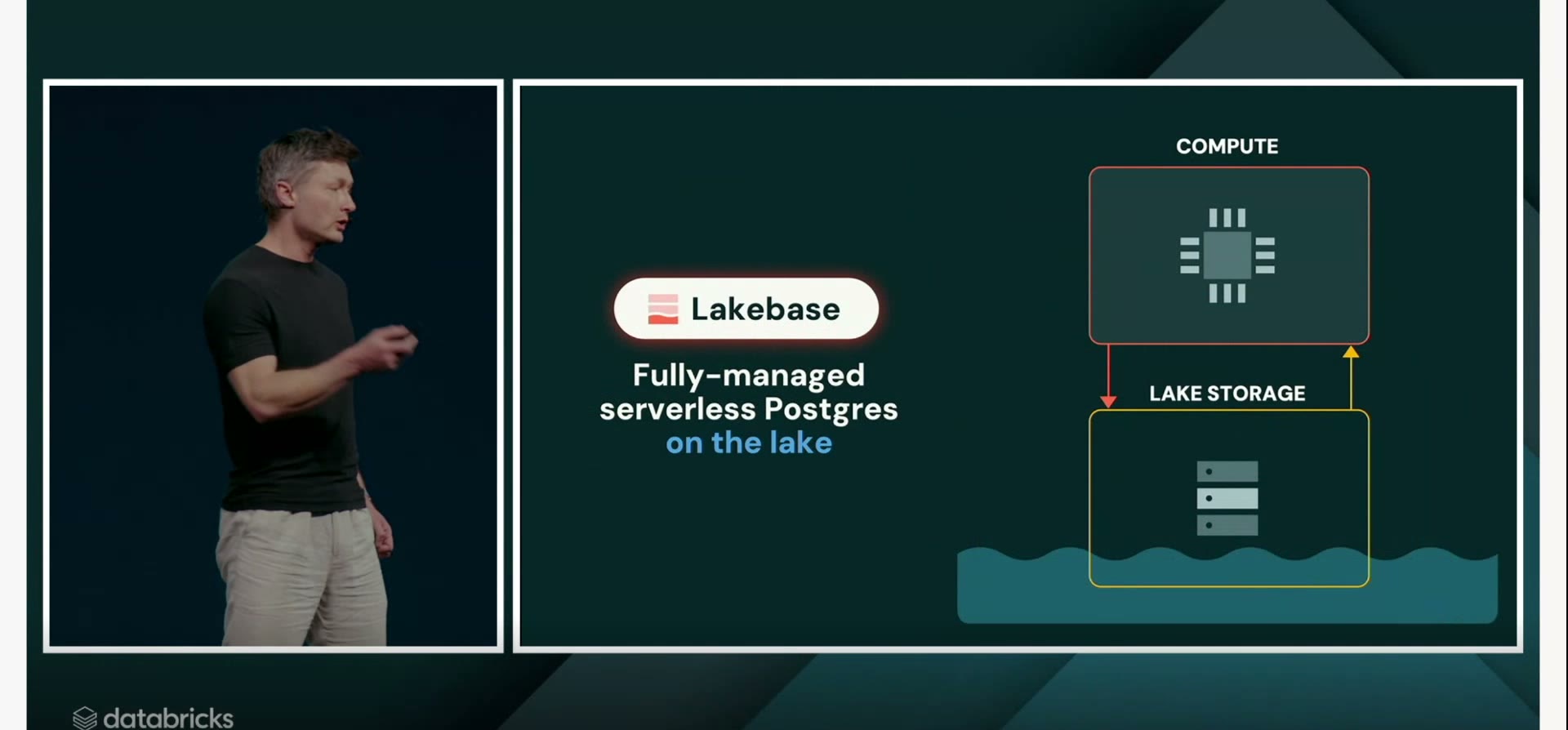
性能と使い勝手の数字が並ぶ。立ち上がりは数百ミリ秒、遅くとも0.5秒以内。使わない時間は処理能力をゼロまで落とせる(scale-to-zero)から、待機させているだけで課金が積み上がることがない。「ブランチ」と呼ぶ機能では、データベースの複製を一瞬で作り、変えた部分だけを追跡できる。スナップショットから過去の状態に戻すのも自在だ。処理量は毎秒60万件にのぼる。
ここが効くのは、AIエージェントを動かす業務だ。エージェントは試しに環境を一つ作って動かしては捨てる、を繰り返す。立ち上がりが遅く、待機コストがかさむデータベースでは、この使い方に耐えられない。一瞬で立ち上がり、使わなければゼロに落ちる。数百ミリ秒の起動とscale-to-zeroは、まさにエージェント時代の運用DBのために設計されている。
片方のクラウドが落ちても、止めない
データベースで怖いのは、止まること。Lakebaseには、業界初をうたう完全マネージド型のクロスクラウドDR(災害復旧)が用意された。

平たく言えば、片方のクラウド(たとえばAWS)が落ちても、もう片方(Azure)へワンステップで切り替えられる、ということ。ここで効くのが、切り替え先を普段は待機させておける点だ。止まらないために本番をもう一式そっくり常時動かし続ける構成(アクティブ-アクティブ)は、安心と引き換えに二重のランニングコストを払い続ける。Lakebaseは、復旧サイトを切り替えの瞬間まで最小限で待たせておけるので、その無駄が小さい。リージョンやクラウドをまたいだ切り替えを、完全にマネージドな形で提供するのは業界初だという。
Lakebaseはすでに3,500社以上が使っている。発表されたばかりの新機能の話に聞こえるが、土台そのものは現場で回り始めている。
取引も分析も、ひとつに(LTAP)
二つの発表を貫く考え方が LTAP(Lake Transactional/Analytical Processing=レイク上で取引処理と分析処理を一体で回す)だ。
取引(Lakebase)と分析(Lakehouse//RT)を、オープンなデータレイクの上にある、一つの統制された「記録の正本(system of record)」に統合する。これまでのように「取引の数字」と「分析の数字」が別々の島に分かれて存在するのではなく、正しい数字は一か所、という状態にする。しかも、片方に寄せたせいでもう片方が遅くなる、という性能の妥協をしない、というのがこの構想の肝だ。
構想倒れでないことは、マスターカードの事例が示す。年に1,500億件を超える取引を扱う規模の会社が、データの保管場所を国・地域の規則に合わせる「データレジデンシー」の要件に応えるためにLakebaseを採用。構想から大規模な適用まで、約7週間で持っていったという。
島が一つになる、ということの意味は地味だが大きい。コピーの仕組みが消えるということは、そのコピーを作り、監視し、壊れたら直してきた人の仕事が、まるごと減るということだ。二重のルールも、片方が古くなる不安も、同じように軽くなる。
押さえどころ
データの量が増え、AIが常時データを叩くようになると、これまでの「島を増やし、コピーを増やし、それを守る人を増やす」というやり方は、際限なく重くなる。
問われるのは、システムを足して人も足す、以外の道を検討できているか。コピーをやめて一か所に集める。使う時だけ立ち上げ、使わなければ落とす。止まっても切り替えられるようにしておく。今回の発表で効いているのは、その選択肢が「研究段階」の話ではなく、3,500社・マスターカードという実運用の言葉で語られた点だ。
速くて、コピーがなくて、統制が効いている。そんな“ひとつの記録の正本”が足元に整っているか。それは、この先のあらゆる打ち手の前提になる。一度ここを整えた企業と、島を増やし続ける企業の差は、データとAIが重くなるほど開いていく。
関連:生成AIに「自社の文脈」を渡すサービス「Ontology Boost」
速くて統制の効いた“ひとつのデータ基盤”が整ったその先で、最後に問われるのは「そのデータの“意味”をAIがどこまで分かっているか」です。基盤の上に、自社固有の文脈をどう乗せるか——これは、私たちSiNCEが提供を開始したサービス 「Ontology Boost」 がまさに取り組む領域です。生成AI(ChatGPT・Claude・Geminiなど)が、御社固有の用語・KPI・業務ルールに沿って”根拠のある”回答を返せるよう、知識基盤(オントロジー)の構築・接続・運用までを一貫支援します。