機械学習の業界には、ずっと一つの夢があった。MLをできる限り簡単に、自動化したものにすること。そうすれば賢い判断を、ビジネスのあらゆる重要な意思決定に行き渡らせられる。多くの企業が挑み、多くが失敗してきた。Data + AI Summit 2026のDay2基調講演で、Databricksのプロダクトマネジメント(Data Science and Machine Learning)を率いる Mike Del Balso 氏は、「それがようやく変わりつつある」と切り出した。GoogleでMLOps(MLの本番運用)の黎明を見て、UberのML基盤「Michelangelo」を立ち上げた人物だ。彼が示したのは、MLを自動化する唯一の技術はエージェントであるという主張と、それを成立させる基盤とエージェント群だった。
隠れた技術的負債——MLコードは氷山の一角でしかない
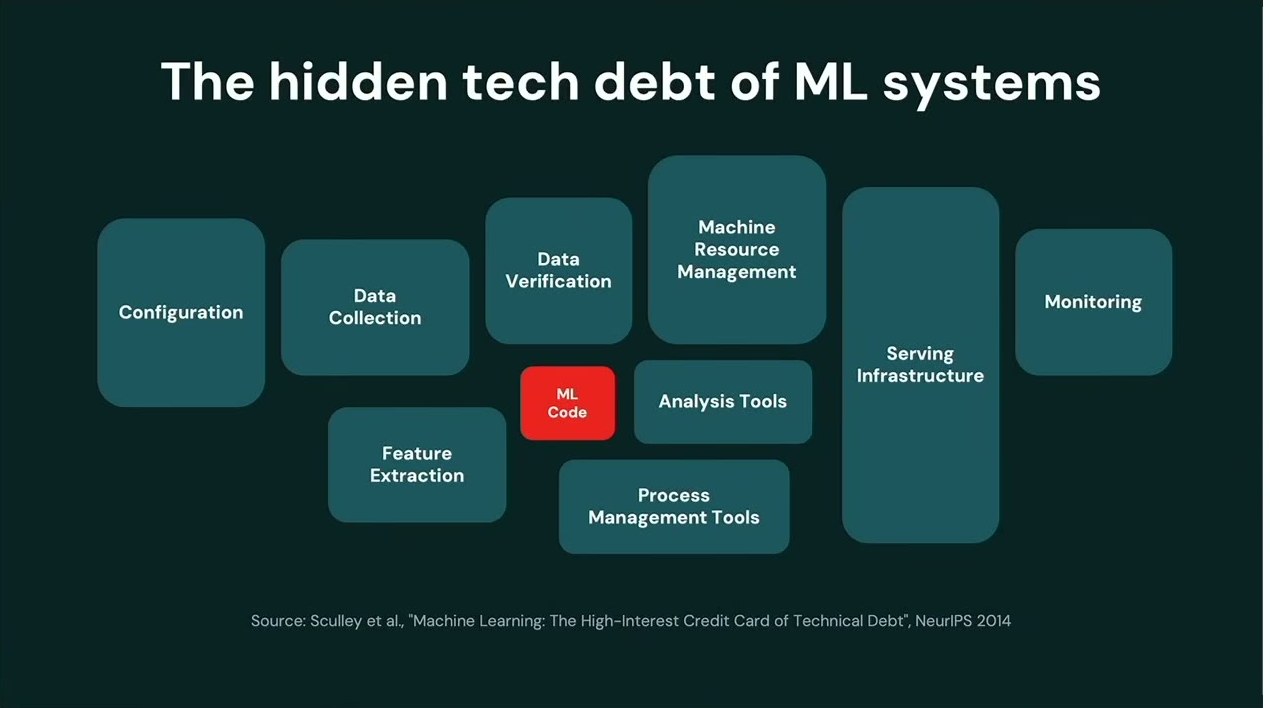
最初に映されたのは、多くのエンジニアが見覚えのある一枚だった。Mike氏のチームが約12年前にGoogleで発表した論文(Sculley et al., NeurIPS 2014)の図である。真ん中の赤い小さなブロックが「ML Code」。そしてそれを取り巻く Configuration、Data Collection、Data Verification、Serving Infrastructure、Monitoring こそが図の主役だ。本番でMLを動かし続けるために、実際には無数のシステムを構築・運用・保守しなければならない。「これは本番MLがいかに難しいかを説明する図だ」と彼は言い、種明かしをする。この難しさは、突き詰めればすべてデータの問題だ——と。
MLへのニーズはかつてないほど高い——50Xに膨らむ意思決定
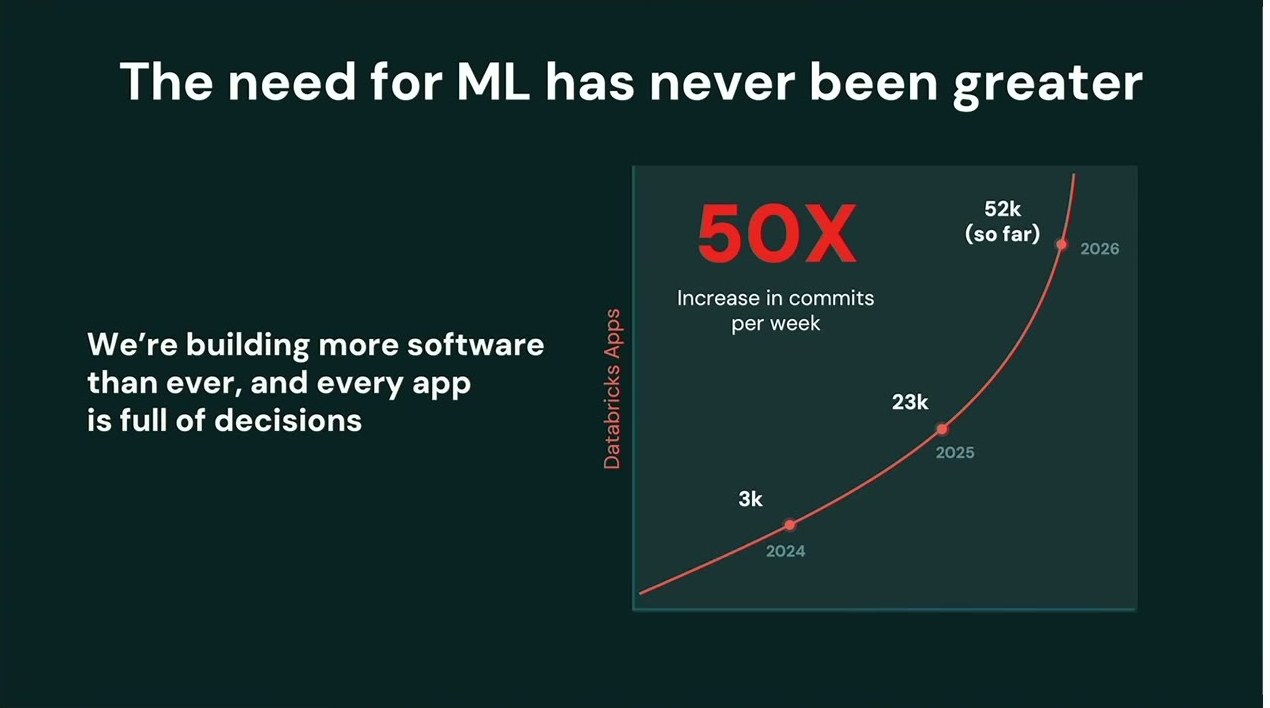
生成AIがMLの需要を減らすと思った人もいるだろう。だが現実は逆だ、と彼は強調する。新しいソフトウェアを作るほど、推薦すべき商品も、提示すべき価格も、検知すべき不正も、判断すべき融資申請も増える。社内の意思決定の総量は爆発的に膨らむ。Databricks Appsの週次コミット数は 2024年の3kから2025年に23k、2026年は途中時点で52k——おおむね 50倍の伸びだ。ところがMLは難しいから、私たちはそれを「配給」してきた。ごく一部でしか使わず、あとはヒューリスティクスや静的なロジックで「より愚かな判断」をしている。
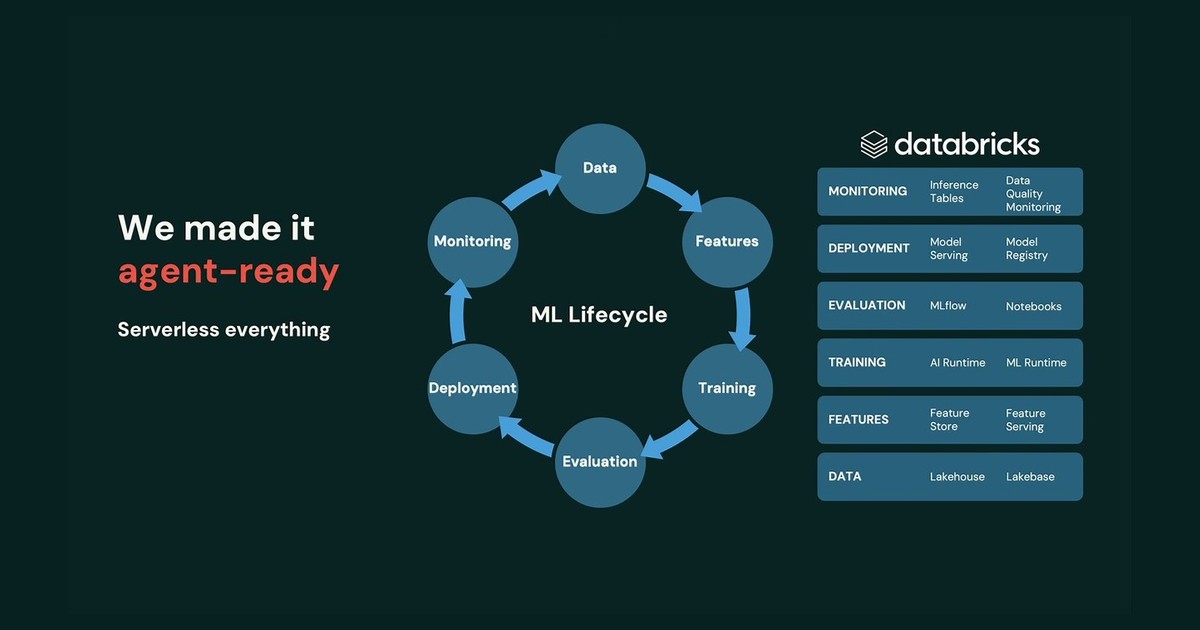
問題は、MLライフサイクル——Data → Features → Training → Evaluation → Deployment → Monitoring——のあらゆる段階に人がいることだ。どの特徴量を作り、どのモデルを本番へ昇格させるか、博士号を持つようなデータサイエンティストがその都度判断している。MLを自動化するなら、彼らと同じように判断を下す自動化が要る。それを担える技術は一つしかない、とMike氏は断言する。エージェントだ。だがエージェントはMLにまだ同じインパクトを与えていない。理由は二つ。正しいインフラを持つ企業がごく一握りしかいないこと、そしてエージェントが同じ質の判断を下すためのコンテキストが、今日のエージェントには手に入らないことだ。
エージェント対応にした基盤——サーバーレス、閉じたデータループ、デフォルトのガバナンス
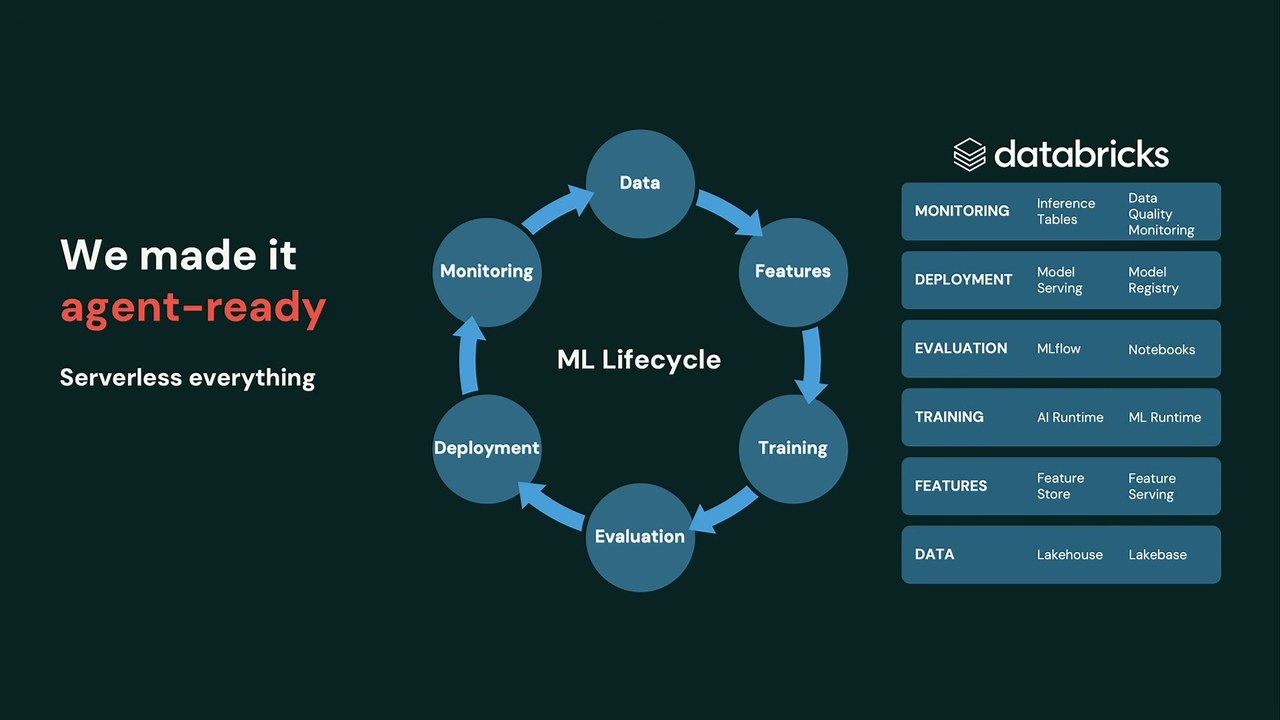
Databricksは過去18か月をかけてスタックをエージェント対応にしてきた。過去1年だけで 5億を超えるモデルがDatabricks上で学習され、Gartnerのマジック・クアドラントでもLeadersの最右上に位置づけられている。すでに揃っていたこの基盤を、人ではなくエージェントが駆動できる形に作り変えたという。
柱は三つ。第一に、すべてをサーバーレス化。エージェントにクラスタ設定や状態維持をさせず、必要なスケールへ即座に立ち上げ落とせる。第二に、ライフサイクル全体を単一のデータモデルで計装した。学習・特徴量・サービング・監視・推論が同じガバナンス済みテーブルに着地し、エージェントは自らの変更の影響を即座に見られる。第三に、デフォルトでガバナンス。モデル・実験・サービングエンドポイントをUnity Catalogで統制するのに加え、エージェントが取れるアクションそのものにもガバナンスをかけた。だから変更を信頼できる。
そして当日、新しいコンピュートタイプ AI Runtime を発表。エンタープライズ深層学習向けのサーバーレスGPUで、前払いコミットなしにオンデマンドで使える。「Powerful GPUs, on-demand」「Research-grade, enterprise-scale」を掲げ、すでに数百社が深層学習ワークロードを移している。前日にAli氏が触れたMerckの創薬モデルもこの基盤上の成果だ。さらにこの日、マルチノード学習のサポートを追加。どんな規模のデータでもスケールしてモデルを構築できるようになった。
Genie Code for ML——シニアMLエンジニアのように働くエージェント

基盤ができたら、次はループを駆動するエージェントだ。Mike氏が発表したのは、本番ML工学のためのエージェント Genie Code for ML——当日からの提供だ。「現実世界のMLを誰よりも見てきたのはDatabricksだ」と彼は言う。何が効き、何が効かず、本番で「良い」とは何か。その教訓をすべてGenie Codeに織り込み、MLスタックにネイティブ統合し、先ほどのインフラの使い方をどのコーディングエージェントより理解させた。
最も重要なのはコンテキストの強化だという。冒頭の技術的負債の図は10年前の「人の問題」を解くものだった。だが人が判断するとき、実際にはもっと多くの情報源に頼っている。すでにどんな実験を回したか、このビジネス指標は何を意味するか、評価スクリプトはどこにあるか。こうしたコンテキストはプラットフォーム全体に散らばっている。
エージェントにMLを持ち込むのは、コンテキストの問題

もしエージェントがこのデータにアクセスできなければ、間違ったデータを使い、間違った評価をし、一見正しそうだが正しくないものを返す——そして信頼できない。前日にKen氏が発表した Genie Ontology を、Databricksはここに統合した。すべてのコンテキストをGenie Codeに組み込み、チームがどうモデルを作り、どう評価するかを理解させたのだ。だからGenie Codeは既存パターンと同じやり方で特徴量を作り、既存の学習スクリプトとワークフローを再利用する。そして「このモデルは良い」と言えば、それはチームが信頼するのと同じ基準で測られている。
多国籍エンジニアリング企業 Danfoss は、これによりMLゼロの状態から完全な本番MLシステムまでをわずか 90分で構築した。通常なら数週間、数か月、企業によっては四半期かかる仕事だ。
Genie ZeroOps for ML——MLシステムを運用するエージェント
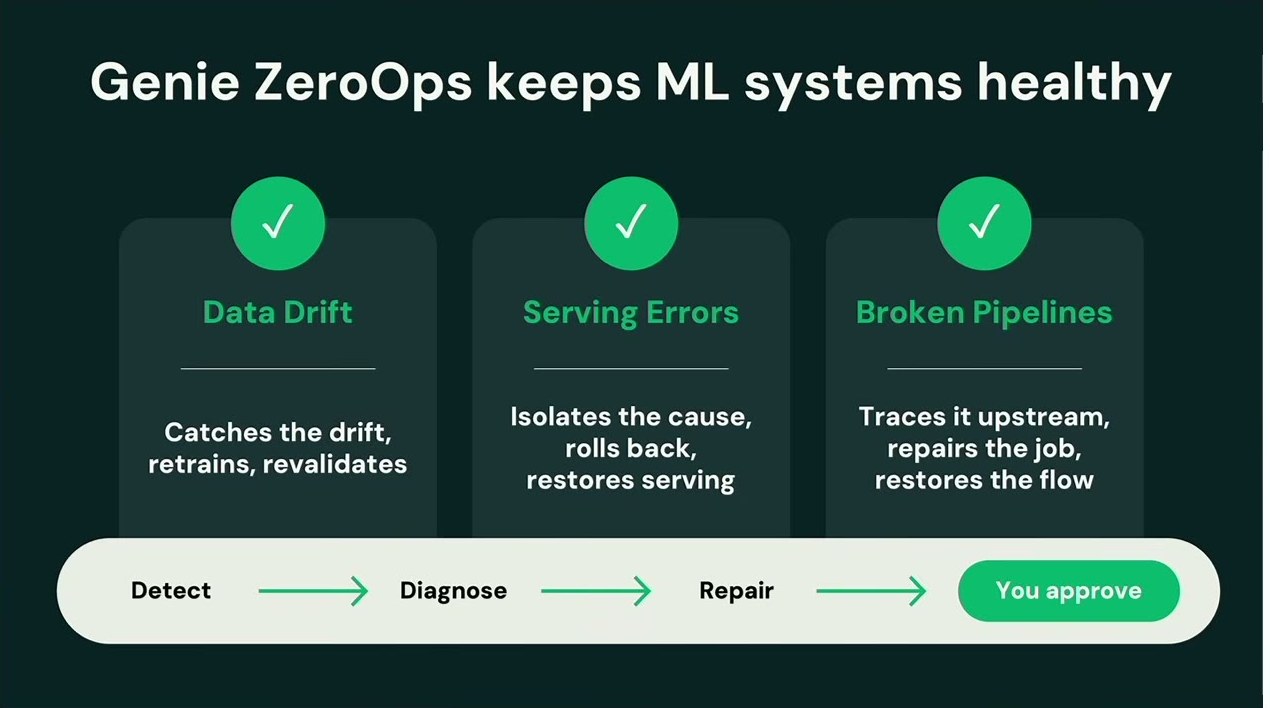
だが悪い知らせがある。現場のMLチームに聞けば、構築は仕事の大半ではない。時間の60〜70〜80%は、MLアプリケーションの「保守」に費やされている。モデルを100倍速く作れば100倍多くのモデルができる。その保守負担を100倍背負える組織はない。
そこでMike氏が「過去10年で機械学習における最大のローンチ」と呼んで発表したのが Genie ZeroOps for ML。MLシステムを、あなたに代わって運用するエージェントだ。従来の監視は問題を見つけて「これがおかしい」と持ってくるだけだった。ZeroOps for MLはそこで止まらず、問題を見つけ、自ら根本原因を突き止め、自律的に修正を考え、解決策を持ってくる。すべての本番モデルを継続監視し、問題を自律的に調査・解決する。ただしデプロイ前には必ずチームの承認を残す。これまでMLは常にチームの誰かがオンコールだった。ZeroOpsはそれを反転させ、エージェントをオンコールに、チームは推奨を承認する立場に置く。Data Drift・Serving Errors・Broken Pipelinesに対し、Detect → Diagnose → Repair → You approve の流れで対処する。
デモ——崩れたチケット需要予測を、エージェントが自律で根本原因まで辿る
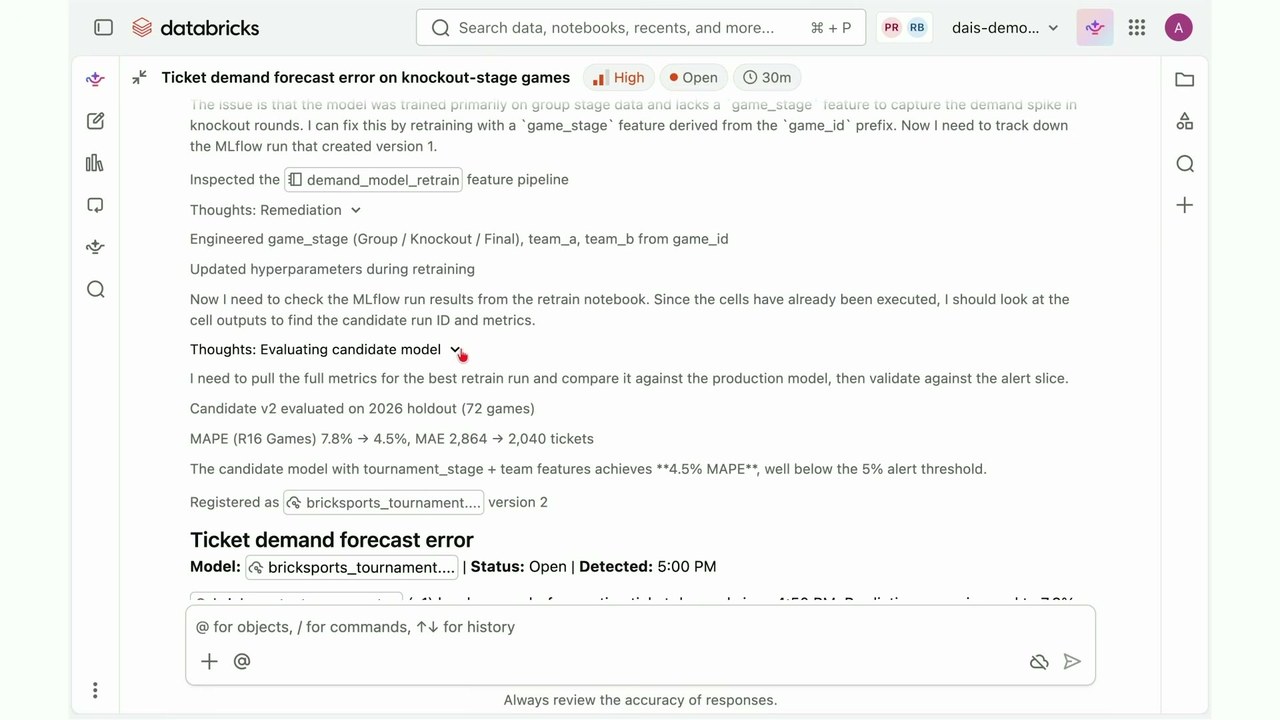
ステージにはAmber氏が登壇し、ライブで動かして見せた。題材は架空の「Data and AI World Cup」。Bricksports Globalには全試合のチケット販売を予測する本番モデルがあり、予測は運営費の数千万ドル規模に直結するミッションクリティカルなものだ。
まずGenie Codeに「予測と実績が±5%を超えたら発火するアラートを作って」と頼むと、追加設定なしでアラートが作られる。金曜17:30、会議から戻ってメールを開くと——アラートが30分前に発火していた。だが新しいボタンがある。「View investigation in Genie ZeroOps」。タップすると最高深刻度のスレッドが開いた。Genie ZeroOpsは私が調査するのを待たず、30分前から自動で動き、すでに数十の仮説を検証していた。
ZeroOpsはモデルを作ったノートブックを分析し、Unity Catalogのテーブルを見て、SQLを実行し、MLflowの実験を走らせる。まるで本物のML専門家のように反復し、根本原因に辿り着いた。モデルにはトーナメントのステージを伝える特徴量が欠けていた。本番のv1は game_id をワンホット(カテゴリ値を0/1のフラグ列に変換する手法)で学習しており、トーナメントラウンドの信号を持たない。だから決勝トーナメント(ノックアウトステージ)に入った途端、増えた需要を捉えられず予測がずれた。
そこで止まらない。ZeroOpsは未活用データから特徴量(game_stage、team_a、team_b)を作り、ハイパーパラメータをチューニングして再学習し、MLflowに登録した。ライフサイクル全体のリネージを持つため、前モデルと同じ評価基準を再利用して精度を確認する。結果は 2026のノックアウトholdout(学習に使わず評価用に取り分けた検証データ、72試合)でMAPE(平均絶対パーセント誤差)7.8%→4.5%、MAE(平均絶対誤差)2,864→2,040チケット。閾値5%を下回り、bricksports_tournament のversion 2として登録された。Amber氏は評価を自分の目で確認し、ワンクリックで少量のトラフィックにデプロイ——AI Gatewayではversion 1に90%、version 2に10%のカナリア配信が組まれた。本来なら数時間から数日のチーム横断インシデントが、最小の混乱で解決した。
エージェント型MLエンジニアリングが到来——ループは自走し、チームが指揮を執る

講演は三つの発表に集約された。AI Runtime(マルチノード学習対応)はPublic Preview——サーバーレスGPUで深層学習やLLMを構築できる。Genie Code for MLは一般提供(generally available)——いま手元のGenie Codeに組み込まれており、今日から使える。Genie ZeroOps for MLはこの夏(coming soon)だ。
Data → Features → Training → Evaluation → Deployment → Monitoringのループは外周を自動で回る。構築側を Genie Codeが、運用側を Genie ZeroOpsが担い、チームは指揮を執る立場に立つ。「100倍のモデルには100倍の複雑性が伴う。チームをそこから守ることこそ機会だ」とAmber氏は言う。Mike氏は「MLを100倍にする時代に入った」と締めくくった。賢い判断をビジネスのあらゆる意思決定に行き渡らせる——その夢に、ようやくインフラとエージェントが追いついた。
押さえどころ
- MLの自動化はデータの問題であり、それを駆動できる技術はエージェントだけ——というのが出発点。壁は「正しいインフラを持つ企業が少ないこと」と「エージェントに与えるコンテキストがないこと」の二つ。
- Databricksはスタックをエージェント対応にした。すべてサーバーレス/単一データモデルの閉じたループ/デフォルトでガバナンス(エージェントのアクションまで統制)が柱。
- AI Runtime(Public Preview)はエンタープライズ深層学習向けのサーバーレスGPU。前払いコミット不要で、新たにマルチノード学習に対応した。
- Genie Code for ML(一般提供)はGenie Ontologyでコンテキストを得て、チームのパターン・学習スクリプト・評価基準を再利用する。Danfossは生データから本番サービングまで90分で構築した。
- Genie ZeroOps for ML(この夏)は問題ではなく解決策を持ってくる運用エージェント。デモでは欠落特徴量(game_stage)を自律で突き止め、再学習でMAPEを7.8%→4.5%に改善し、承認を経てワンクリックでカナリアデプロイした。
デモで光るエージェントではなく、本番のループを丸ごと回し続けるエージェントへ。ループは自走し、チームが指揮を執る——agentic MLエンジニアリングは、ここから始まる。








