
本記事では、Databricksジョブを活用して、dbt Coreプロジェクトを効率的に実行する方法について解説します。Databricksジョブを利用することで、dbtプロジェクトの定期実行や自動化が可能となり、データトランスフォーメーションの運用が簡略化されます。
はじめに
本記事では、Databricksジョブを活用して、dbt Coreプロジェクトを効率的に実行する方法について解説します。Databricksジョブを利用することで、dbtプロジェクトの定期実行や自動化が可能となり、データトランスフォーメーションの運用が簡略化されます。
この記事では、Databricksとdbtの基本的な連携手順を紹介し、jaffle_shopリポジトリを例に挙げて解説します。この方法を活用することで、以下のようなメリットが得られます。
・dbtタスクをスケジュール実行して自動化。
・ジョブ全体を監視し、成功・失敗通知を受信。
・他のタスク(データ取り込みや分析)とのシームレスな統合。
dbt Coreプロジェクトを効率的に運用するための基盤づくりにぜひお役立てください。
概要
Databricksジョブを利用すると、以下のようなdbt Coreプロジェクトの運用が可能になります:
自動化とスケジュール: dbtタスクを自動化し、定期実行をスケジュール可能。
監視と通知: dbt変換のステータスを監視し、失敗や成功時に通知を送信。
ワークフロー統合: 他のタスク(例:データの取り込みや分析タスク)と統合。
成果物のアーカイブ: ログやマニフェストなどの成果物を自動的に保存。
要件
1.依存パッケージの準備 Databricksでは、dbt-databricksパッケージを推奨しています。このパッケージはDatabricks向けに最適化されています。
pip install dbt-databricks2.DatabricksのGit統合 Databricksジョブでdbtプロジェクトを使用するには、DatabricksのGit統合を設定する必要があります。
3.SQLウェアハウスの有効化 サーバーレスまたはプロSQLウェアハウスを有効化します。
4.必要な権限 Databricks SQLとジョブの実行権限が必要です。
1. ジョブの作成
以下の手順で、Databricksジョブを設定してdbtプロジェクトを実行します。
1.Databricksのサイドバーから「ワークフロー」をクリックし、[ジョブ作成]を選択します。

2.ジョブ名を入力します(例:dbt_task)。
2. dbtタスクの追加
1.タスクのタイプ選択
タスクタイプにdbtを選択します。
2プロジェクトソースの設定
ソースとしてGitプロバイダーを選択し、リポジトリを指定します。Gitリファレンスにはmainブランチを指定します。
例:
・GitリポジトリURL: https://github.com/olyalukashina/jaffle_shop
・Gitリファレンス: main
3.dbtコマンドの設定
実行するdbtコマンドを指定します。以下は基本的なコマンド例です:
dbt deps # 必要な依存関係をインストール
dbt seed # seedファイルをロード
dbt test # テストを実行
dbt run # モデルを実行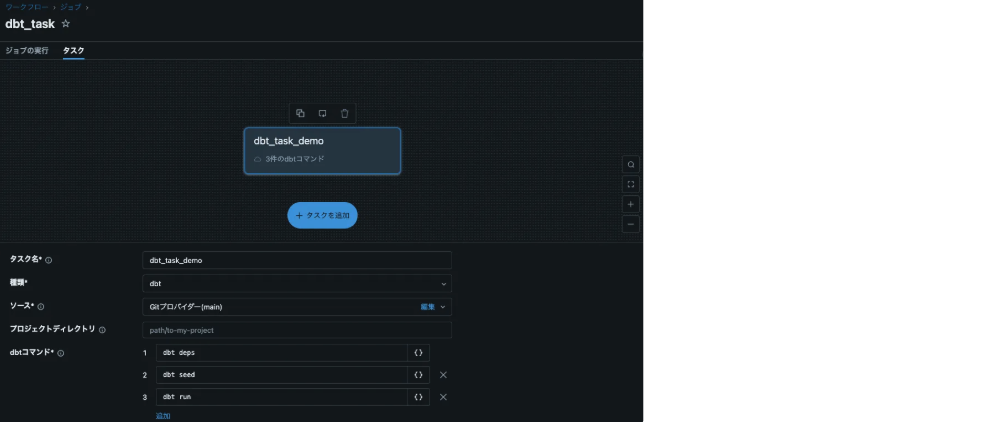
4.SQLウェアハウスの設定
dbt生成SQLを実行するSQLウェアハウスを選択します。サーバーレスまたはプロSQLウェアハウスを利用するのがおすすめです。
5.依存ライブラリの設定(オプション)
使用するdbt-databricksパッケージのバージョンを固定するには、以下の手順を実行します:
・現在のバージョンを削除
・dbt-databricks==1.6.0などのバージョンを追加
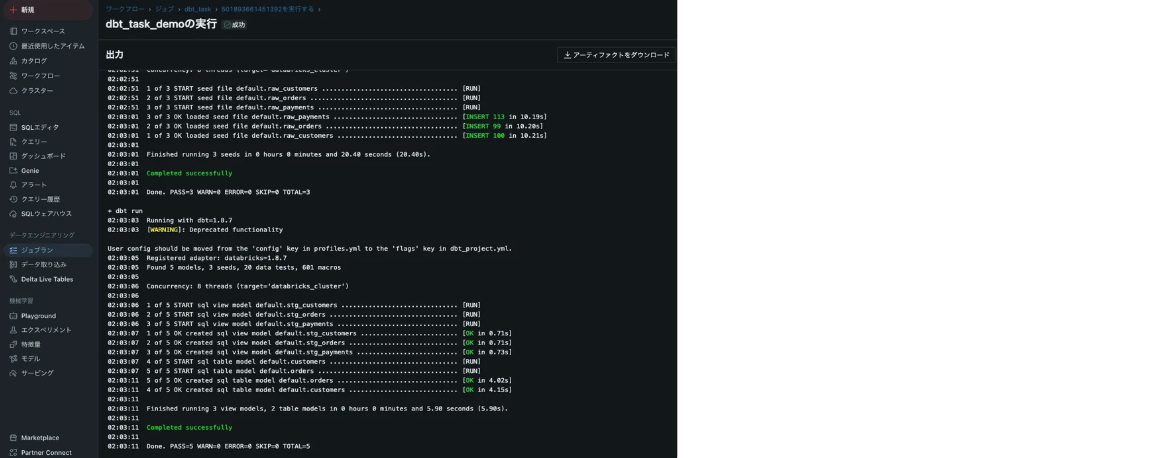
3. ジョブの実行
設定が完了したら、今すぐ実行をクリックしてジョブを開始します。ジョブのステータスやログは、Databricksジョブの詳細ページから確認できます。
4. 定期実行の設定
ジョブのスケジュール設定を利用して、定期実行を有効にします。以下のようなスケジュールを設定することが可能です。
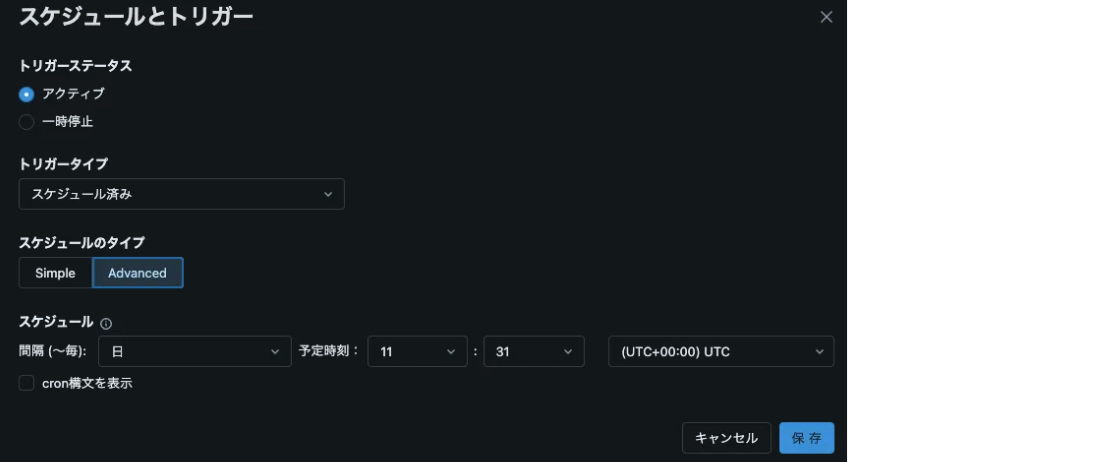
スケジュールタブで時間や頻度を指定するだけで、自動化が完了します。
終わりに
Databricksジョブを活用してdbt Coreプロジェクトを運用することで、データトランスフォーメーションのプロセスを簡略化し、定期実行や自動化を容易に実現できます。特にDatabricksのSQLウェアハウスやGit連携を組み合わせることで、プロジェクト全体の管理が効率化され、安定性も向上します。
さらに、Databricksジョブの柔軟なワークフロー構築機能を活用することで、データの取り込み、変換、分析といった一連のタスクをシームレスに統合できます。この仕組みを活用すれば、スケーラブルで効率的なデータパイプラインを構築するための強力な基盤が得られます。










