
本記事では、Databricks と dbt(Data Build Tool)を組み合わせてデータ加工を効率的に行う方法を解説します。クラウド環境のスケーラビリティを活かし、dbt によるモジュール化とデータ品質チェックの自動化を行うことで、データパイプラインの構築と運用がよりシンプルになります。 dbt-osmosisを活用した自動ドキュメント生成についても取り上げ、データプロジェクトの管理やメンテナンス性を向上させる方法について紹介します。
はじめに
本記事では、Databricks と dbt(Data Build Tool)を組み合わせてデータ加工を効率的に行う方法を解説します。クラウド環境のスケーラビリティを活かし、dbt によるモジュール化とデータ品質チェックの自動化を行うことで、データパイプラインの構築と運用がよりシンプルになります。dbt-osmosis を活用した自動ドキュメント生成についても取り上げ、データプロジェクトの管理やメンテナンス性を向上させる方法について紹介します。
必要な準備
1. Databricks のセットアップDatabricks でワークスペースをセットアップし、接続に必要なホスト URL、HTTP パス、アクセストークンを取得します。この情報は、dbt が Databricks に接続するために必要です。
ローカル環境で dbt プロジェクトをセットアップし、Databricks への接続を設定します。以下は、profiles.yml の設定例です。
# ~/.dbt/profiles.yml
dbt_project:
target: dev
outputs:
dev:
type: databricks
schema: default
host: your-databricks-host
http_path: your-http-path
token: your-access-token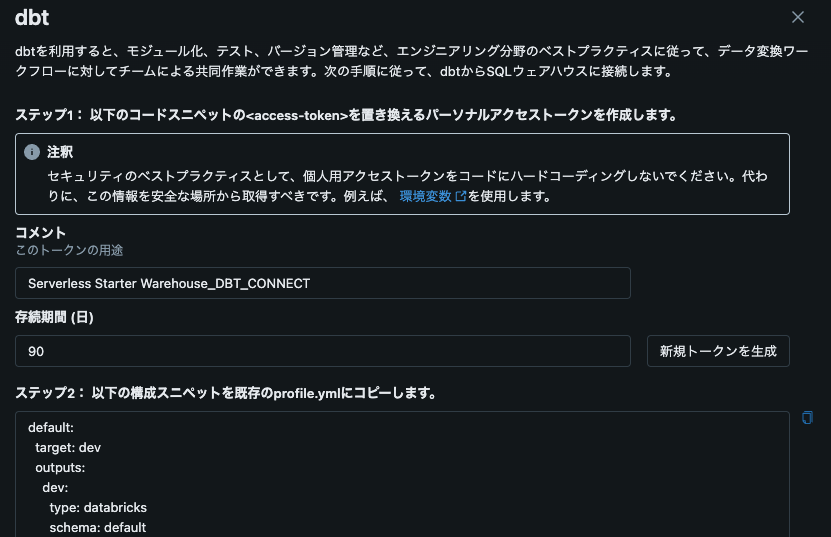
この設定で、Databricks 環境に接続する準備が整いました。
データ加工の実例
以下の例では、データ列に含まれる文字化けの修正を行い、整ったデータを新しい列として生成します。
-- models/transform_data.sql
SELECT *,
REPLACE(
REPLACE(
REPLACE(
target_column,
'文字列A',
'修正後の文字列A'
),
'文字列B',
'修正後の文字列B'
),
'文字列C',
'修正後の文字列C'
) AS transformed_column
FROM {{ source('data_warehouse', 'raw_data_table') }}
このクエリは、data_warehouse データベース内の raw_data_table からデータを取得し、target_column 内の文字列を順次置換して、文字化けの修正結果を transformed_column 列に出力します。
models ディレクトリ内に .sql ファイルとしてクエリを保存することで、dbt はこのクエリをモデルとして認識し、実行時に必要な変換を行います。
Databricks 上の既存のデータソースを dbt で使用するため、sources.yml にデータソースを設定します。
# models/sources.yml
version: 2
sources:
- name: data_warehouse
database: data_database
schema: default
tables:
- name: raw_data_tableこの設定により、dbt は Databricks 上のデータベースにある raw_data_table を参照できるようになります。
dbt-osmosis を使ったドキュメントの自動生成
dbt-osmosis は、dbt プロジェクトのドキュメントを自動的に生成してくれるツールです。これにより、プロジェクトの可視化が容易になり、カラム情報なども管理しやすくなります。
まず、dbt-osmosis をインストールします。
pip install dbt-osmosisdbt-osmosis を使ってスキーマドキュメントを生成します。以下のコマンドで、dbt プロジェクト内のモデルやソースに対応するドキュメントが自動生成されます。
dbt-osmosis yaml document出力例
version: 2
sources:
- name: data_warehouse
database: data_database
schema: default
tables:
- name: raw_data_table
description: "Table containing sample business data for analysis"
columns:
- name: raw_id
description: "Raw ID from data ingestion"
data_type: string
- name: extracted_at
description: "Timestamp of data extraction"
data_type: timestamp
- name: metadata
description: "Metadata from ingestion process"
data_type: string
- name: generation_id
description: "Generation ID from ingestion process"
data_type: bigint
このコマンドにより、各モデルに対応する schema.yml ファイルが自動生成され、カラム情報や説明などが反映されます。これにより、データモデルの管理が容易になり、データパイプラインの可視性が向上します。
データパイプラインの実行
dbt を使用して、依存関係のインストール、データのテスト、モデルの実行を行います。
dbt deps – 依存関係のインストール
dbt deps コマンドを実行して、dbt_project.yml に定義されている依存パッケージをインストールします。
dbt depsdbt test – データのテスト
次に、dbt test コマンドでデータの品質をチェックします。schema.yml に定義した not_null や unique などのテストが実行されます。
dbt test3.
dbt run – モデルの実行
最後に、dbt run コマンドを使用してデータ変換を実行します。これにより、Databricks に接続してモデルが実行され、変換結果が保存されます。
dbt run
まとめ
Databricks と dbt を組み合わせることで、クラウド上で大規模なデータの加工が簡単かつ効率的に行えます。また、dbt-osmosis を活用することで、スキーマのドキュメント作成が自動化され、データパイプラインの可視性が向上します。これにより、データエンジニアがデータ品質を保ちながら変換処理を行う環境が整い、データプロジェクトの管理が容易になります。










