
Natural Language APIを使用して、ツイートを数値化し、それをBigQuery にアップして分析します。 記事は3つに分けており、この記事は3番目のできたデータを分析していきます。
目次
本分析の目的・目標のおさらい
なにかを分析するときに、最初にこういう分析がしたいというイメージをまとめても、データの制作や準備を行っていると、だんだんと本質とずれてきてしまいます。ここで今一度本分析のおさらいをしておきます。 目的と目標 本分析の目的は「潜在ニーズの表出」と「SNS(twitter)からのサイトへの流入」であり、 本分析の目標は「この単語を使うとエンゲージメント率(サイトURLクリック率等々)が上がりますよ!」と言えるようになることと設定しました。 筆者はここがぶれてしまったり、分析に対する理解度の低さによって分析の本質にそぐわない手順を踏んだりしてしまっています。分析で行ったこと
まずは以下のサイトを参考に回帰分析を行いました。 https://www.magellanic-clouds.com/blocks/blog/other/try_to_use_bigquery_ml/#モデル作成
create model 'モデルの作成作を指定'
options(model_type='linear_reg') as
select
<フィールド名>
<フィールド名> as label--labelをつけることによって被説明変数を指定
where DATETIME1 between '2020-04-01 00:00:00 UTC' AND '20222-03-31 00:00:00 UTC';--データの範囲- 回帰分析の種類 ロジスティック回帰分析と線形回帰分析があり、ロジスティック回帰を使用していた。 ロジスティック回帰:説明変数から二値の結果を予測します。例)合格か不合格か 線形回帰:説明変数から値を予測します。例)気温や曜日から電力消費量を予測する
- ・モデル作成の期間設定 モデル学習データの期間を1カ月分しか指定していなかったため、決定係数が高く出てしまった。
- ・変数の多重共線性 説明変数の中に、説明変数どうしが互いに相関関係にあるものを採用してしまった点
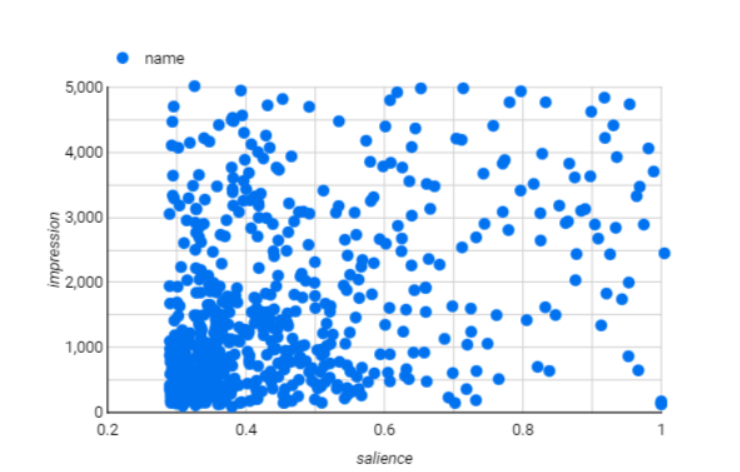 例えばこの散布図です。これだけ散らばりがあると相関性がなく回帰分析などの説明変数として使うことはできないように思えます。
しかしここで使っている値が、「インプレッション数」と「重要度」です。インプレッション数はそのツイートが何回ユーザーの目に入ったかであり、重要度はNLAPIによって分が単語分けされ、その単語が文の中でどれだけの重要度を持っているかを表しています。
文の中で重要度高ければインプレッション数が上がるというのはおかしな話になってしまいます。なので全く役に立たない散布図を作ってしまいました。
改善点
データを可視化するにも、重回帰分析をするにも変数に対する理解度を上げ、必要に応じて加工をしなくてはいけません。この状態でAutoMLを使用した分析も行ってしまい、結果につながらないモデルを作成してしまいました。
データの加工
NLAPIを使用してデータを作成しているわけですから、そのデータがどうすれば使えるようになるのかはしっかりと吟味していかなくてはなりません。
例えば、NLAPIで出てきた「重要度」という値は、その文のなかの単語の重要度を表しているのでそのままではエンゲージメント率について説明する値にはなりません。なので、ツイートのエンゲージメント率を重要度に応じて単語に分配するということが必要になります。これをすればその単語がエンゲージメント率をどれくらい保有しているかがわかります。
このようにデータが使えるのか使えないのか、どうやったら使えるようになるのかはよく考える必要があります。
例えばこの散布図です。これだけ散らばりがあると相関性がなく回帰分析などの説明変数として使うことはできないように思えます。
しかしここで使っている値が、「インプレッション数」と「重要度」です。インプレッション数はそのツイートが何回ユーザーの目に入ったかであり、重要度はNLAPIによって分が単語分けされ、その単語が文の中でどれだけの重要度を持っているかを表しています。
文の中で重要度高ければインプレッション数が上がるというのはおかしな話になってしまいます。なので全く役に立たない散布図を作ってしまいました。
改善点
データを可視化するにも、重回帰分析をするにも変数に対する理解度を上げ、必要に応じて加工をしなくてはいけません。この状態でAutoMLを使用した分析も行ってしまい、結果につながらないモデルを作成してしまいました。
データの加工
NLAPIを使用してデータを作成しているわけですから、そのデータがどうすれば使えるようになるのかはしっかりと吟味していかなくてはなりません。
例えば、NLAPIで出てきた「重要度」という値は、その文のなかの単語の重要度を表しているのでそのままではエンゲージメント率について説明する値にはなりません。なので、ツイートのエンゲージメント率を重要度に応じて単語に分配するということが必要になります。これをすればその単語がエンゲージメント率をどれくらい保有しているかがわかります。
このようにデータが使えるのか使えないのか、どうやったら使えるようになるのかはよく考える必要があります。










