はじめに
エージェントの機能としてユーザーの要求に応じてコードの実行が出来れば、エージェントの分析範囲が広がります。
今回はユーザーの入力に応じて動的なPythonコードの生成および実行を実現します。
想定シナリオ
事前準備:
今回は他ブログで構築した、Walmartのデータを使用してPDFレポートを作成するアプリを使用します。現在のアプリではデータを取得して、可視化する機能がありましたが、LLMと対話して、Pythonコードの実行する機能はありません。
今回はこのアプリの対して既存の機能を取りやめ、Pythonコードの実行・結果の可視化までを実現します。
アーキテクチャ:
今回の機能の実装におけるアーキテクチャは以下になります。
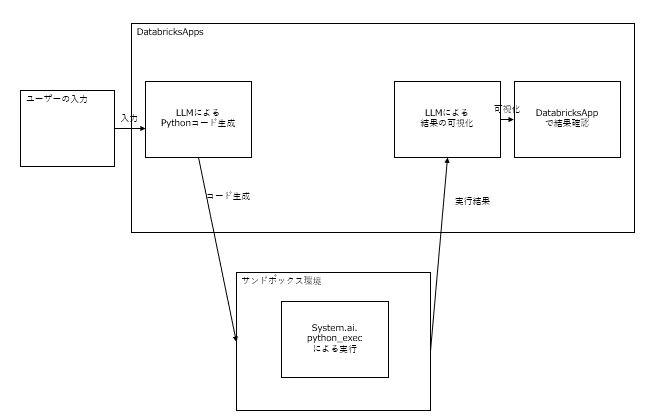
現状の挙動確認
まずは、現在のアプリの挙動を確認します。アプリを起動すると以下のような画面になります。
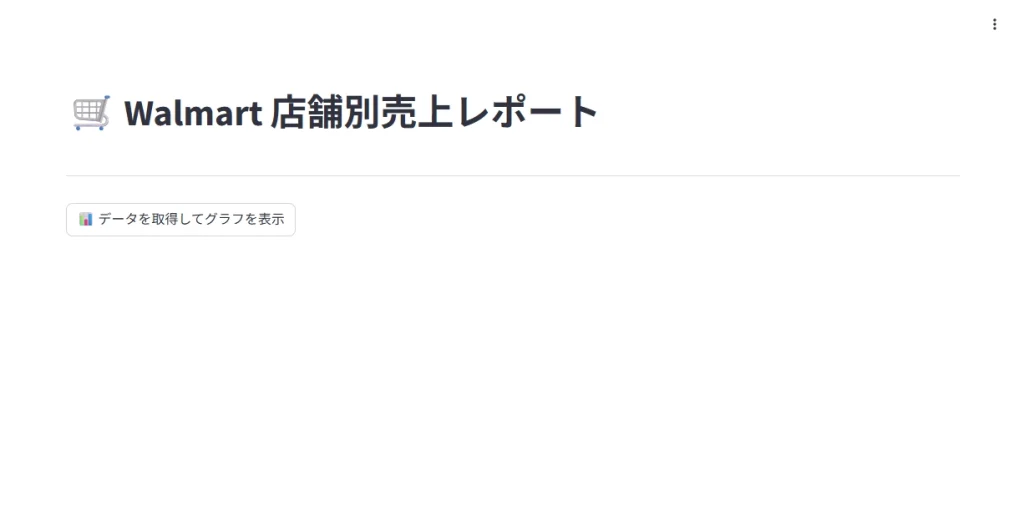
ここでグラフを表示ボタンを押すと、
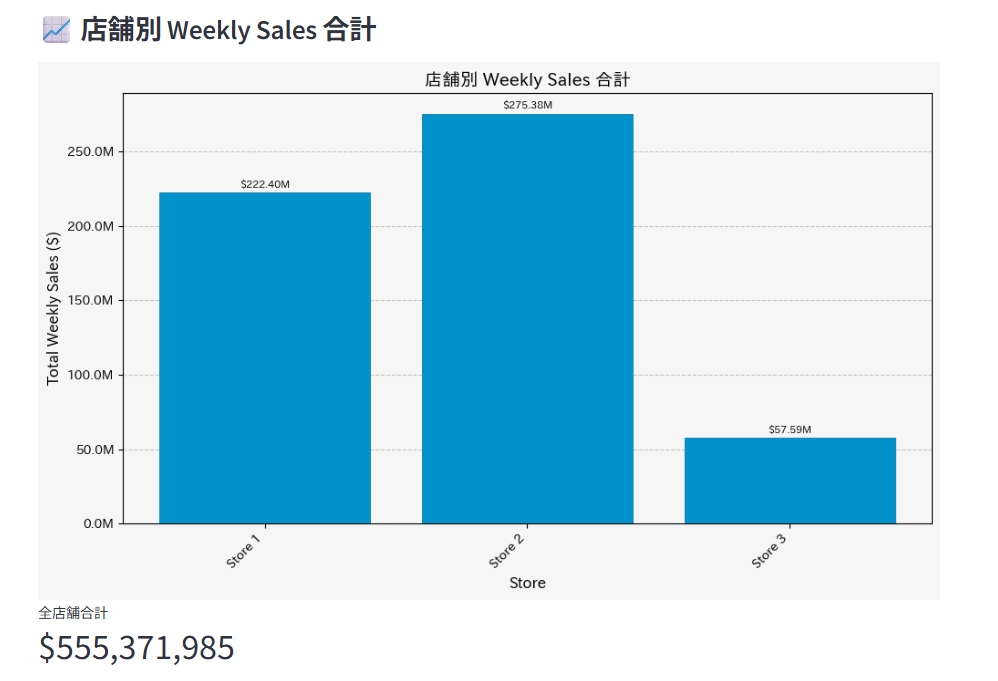
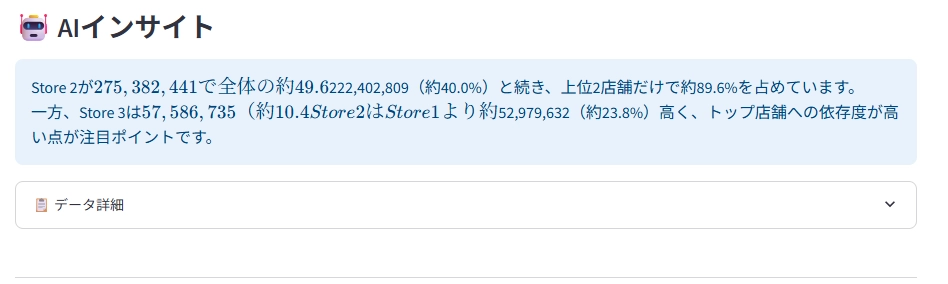
Databricks上のデータを取得し、グラフと合計金額を算出してくれます。さらに、AIが取得したデータに基づいて簡単なインサイトを出力してくれています。
今回はこのアプリを変更し、Pythonコードの動的生成・可視化までを行う機能を実装します。
参考:
https://blog.since2020.jp/data_analysis/databricks_streamlit
https://blog.since2020.jp/data_analysis/databricks-apps_llm
https://blog.since2020.jp/ai/databricks-apps_vegalite
System.ai.python_execとは
system.ai.python_exec は、Databricks が提供する組み込みの Unity Catalog 関数ベースのツールで、AIエージェントから Python コードを動的に実行するためのものです。
今回は、LLMによって動的にPythonコードを生成してもらい、実行はSystem.ai.python_execで行います。
実装
本アプリのコードを一部紹介します。
下記はユーザーの入力に対してLLMによりPythonコードを作成する関数です。
ユーザーの質問に加えて、Pythonコード実行時にデータを取得できるようにデータのスキーマやサンプルデータを入力に含めています。
def generate_python_code(question: str, schema_str: str, records: list[dict]) -> str:
"""
分析用Pythonコードを生成する。
LLMにはサンプル5行のみ渡してコードを生成させ、
生成後に全データをコード先頭に埋め込んで返す。
"""
sample_records = records[:5]
sample_json = json.dumps(sample_records, ensure_ascii=False, cls=_JsonEncoder)
all_data_json = json.dumps(records, ensure_ascii=False, cls=_JsonEncoder)
messages = [
{
"role": "system",
"content": (
"あなたはPythonコードの専門家です。"
"指定された条件に従い、実行可能なPythonコードのみを返してください。"
"説明文やコードブロック記号は不要です。"
)
},
{
"role": "user",
"content": (
f"【ユーザーの質問】\n{question}\n\n"
f"【データスキーマ】\n{schema_str}\n\n"
f"【サンプルデータ(5行)】\n{sample_json}\n\n"
f"【出力要件】\n"
f"- コードの先頭は必ず以下の2行で始めること(この2行はそのまま出力し、データは後で差し替える):\n"
f" import json\n"
f" data = json.loads('__DATA_PLACEHOLDER__')\n"
f"- dataはlist of dictであり、各dictのキーはスキーマの列名に対応する\n"
f"- ユーザーの質問に基づいてdataを分析・集計すること\n"
f"- 分析結果をPython dictとして result 変数に格納すること\n"
f"- 複数レコードの集計・ランキング・時系列などの結果は result = {{\"records\": [{{\"列名\": 値, ...}}, ...]}} の形式にすること\n"
f"- 単一の数値・要約の場合は result = {{\"ラベル\": 値}} の形式で構わない\n"
f"- 最後に print(json.dumps(result, ensure_ascii=False)) を実行すること\n"
f"- import は自由に使って良い(pandas, numpy等。ただしsparkは使用不可)\n"
f"- Pythonコードのみを返すこと(説明文・コードブロック記号不要)"
)
}
]
raw = query_serving_endpoint(messages, max_tokens=2000)
code = raw.strip().strip("```python").strip("```").strip()
# __DATA_PLACEHOLDER__ を全データのJSONで置換
escaped_json = all_data_json.replace("\\", "\\\\").replace("'", "\\'")
code = code.replace("'__DATA_PLACEHOLDER__'", f"'{escaped_json}'")
return code続いて、生成したPythonコードを実行する関数です。
先ほど作成したPythonコードをSystem.ai.python_exeを使用してSQL Warehouse経由で実行しています。
def execute_python_code(code: str) -> str:
"""
system.ai.python_exec を SQL Warehouse 経由で実行し、
print() の出力文字列を返す。
"""
# シングルクォートのエスケープ(SQLインジェクション対策)
escaped = code.replace("'", "\\'")
exec_sql = f"SELECT system.ai.python_exec('{escaped}')"
with get_sql_conn() as conn:
with conn.cursor() as cur:
cur.execute(exec_sql)
row = cur.fetchone()
if row:
return str(row[0])
return ""続いて、Pythonコードの可視化を行う関数です。
詳細は前回のブログに預けますが、可視化に際して「Vega-Lite」という仕様でグラフを記述します。こちらに関してもPythonコードの実行結果などを入力としてLLMにVega-Lite形式で動的に記載を依頼します。
def generate_vegalite_spec(question: str, records: list[dict]) -> dict | None:
"""
Vega-Lite仕様をLLMで生成し、data.valuesに全レコードを埋め込んで返す。
LLMにはサンプル5行と統計サマリのみを送信する。
失敗した場合は None を返す。
"""
col_meta = _infer_column_meta(records)
sample_json = json.dumps(records[:5], ensure_ascii=False, cls=_JsonEncoder)
total = len(records)
messages = [
{
"role": "system",
"content": (
"あなたはVega-Liteの専門家です。"
"与えられたデータ構造とユーザーの質問に基づいて、"
"適切なVega-Lite仕様(JSONオブジェクト)を生成してください。"
"仕様のみを返し、説明文やコードブロック記号は不要です。"
"data.values には \"__RECORDS_PLACEHOLDER__\" という文字列をそのまま指定してください。"
)
},
{
"role": "user",
"content": (
f"【ユーザーの質問】\n{question}\n\n"
f"【列情報と統計サマリ】\n{col_meta}\n\n"
f"【総レコード数】: {total} 件\n\n"
f"【サンプルデータ(先頭5行)】\n{sample_json}\n\n"
f"【要件】\n"
f"- data.values には \"__RECORDS_PLACEHOLDER__\" を指定すること(実データは後で差し替える)\n"
f"- mark, encoding は質問の内容に最適なものを選ぶこと\n"
f"- 軸ラベル・タイトルは日本語でも英語でも可\n"
f"- $schema は省略可\n"
f"- JSONのみを返すこと(説明文・コードブロック記号不要)"
)
}
]
try:
raw = query_serving_endpoint(messages, max_tokens=1500)
spec_str = raw.strip().strip("```json").strip("```").strip()
spec = json.loads(spec_str)
all_records_json = json.dumps(records, ensure_ascii=False, cls=_JsonEncoder)
spec_str_replaced = json.dumps(spec).replace(
'"__RECORDS_PLACEHOLDER__"', all_records_json
)
return json.loads(spec_str_replaced)
except Exception:
return Noneこれにより、ユーザーの入力からPythonコードの生成・実行・結果の可視化を実装することが出来ました。実際に作成したアプリを実行時してみます。
デモ
それでは、先ほど作成したアプリをデプロイし、動かしてみます。
まずは、アプリを起動します。
入力欄に分析をお願いしたい項目を入力します。
まずは、シンプルな分析を依頼してみます。
質問内容:
店舗1から3と店舗4から6と店舗7から9の売上の平均を棒グラフにして教えてください。
結果:
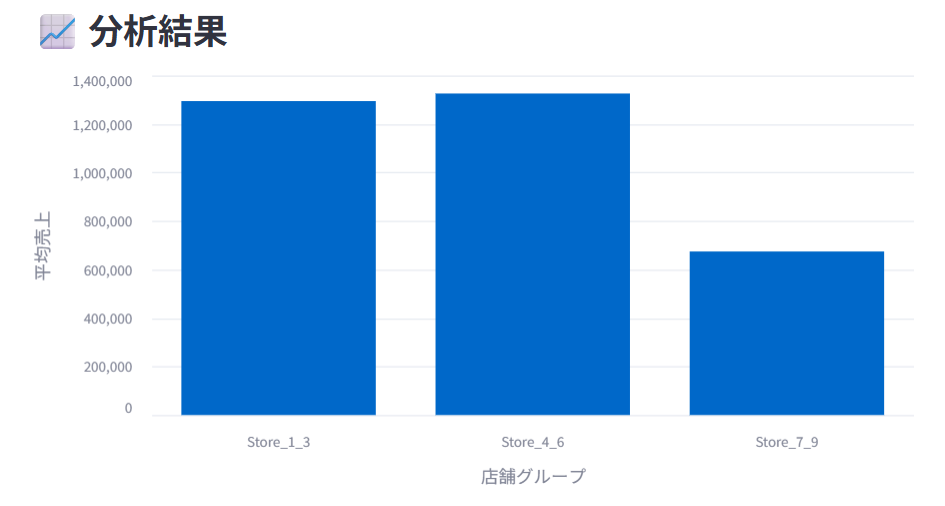
各店舗の売り上げを集計して返してくれています。
続いて、ある店舗の売上の時系列を確認してみます。
質問内容:
店舗1における売り上げを時系列の折れ線グラフで表示して。
結果:
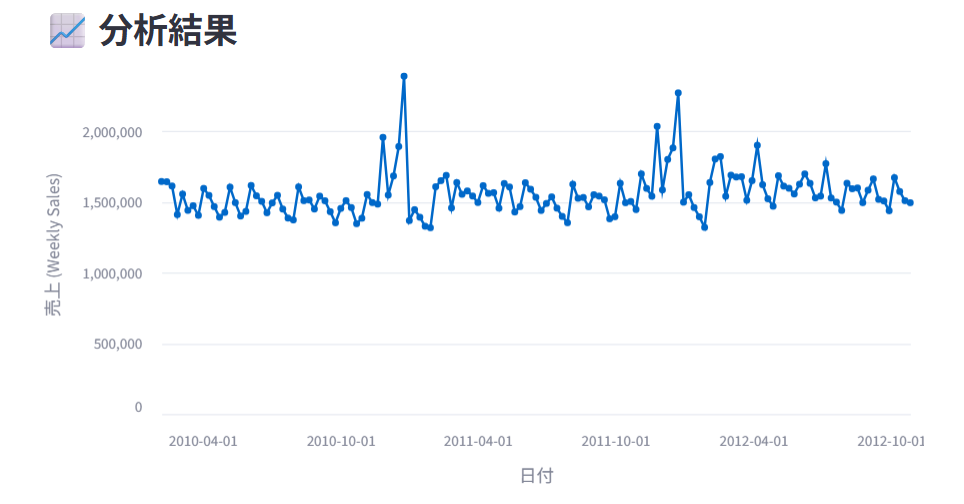
このように店舗1の売上を時系列で出力してくれました。
さらに時系列予測を依頼してみます。
質問内容:
店舗1における売り上げを1年間予測しての折れ線グラフで表示して。
結果:
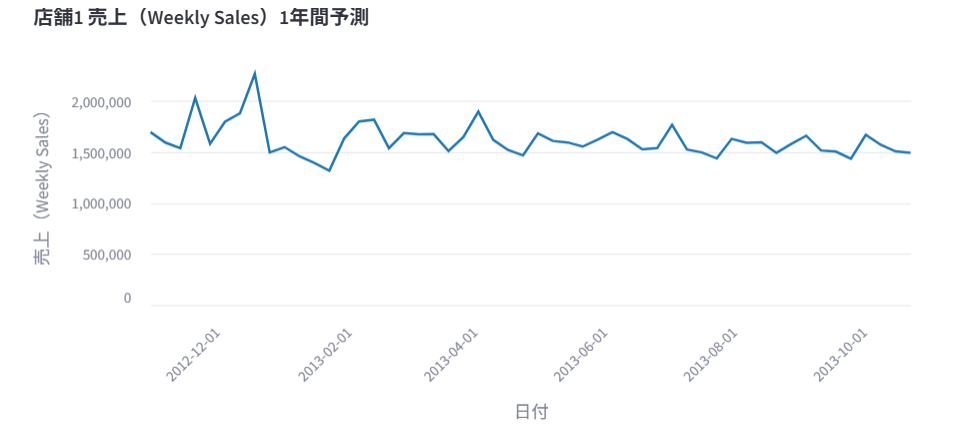
このように店舗1に関する予測売り上げを確認できました。
終わりに
今回はDatabricks Apps上で動的なコード生成を実現するために「System.ai.python_exec」を使用して実装しました。結果として、ユーザーの要求に対して動的にコードの生成・実行を実現できました。










