
Vertex AIで表形式データの機械学習モデルを作成する際に、「回帰/分類」と「予測」を選択することができます。しかし、機械学習において回帰と予測はほとんど同義として扱われることが多いです。ここでいう回帰と予測の違いは「時系列の分析をする際には予測を利用する。その際には回帰は利用できない」ところにあります。
目次
予測したいデータと同一行の特微量を使う回帰
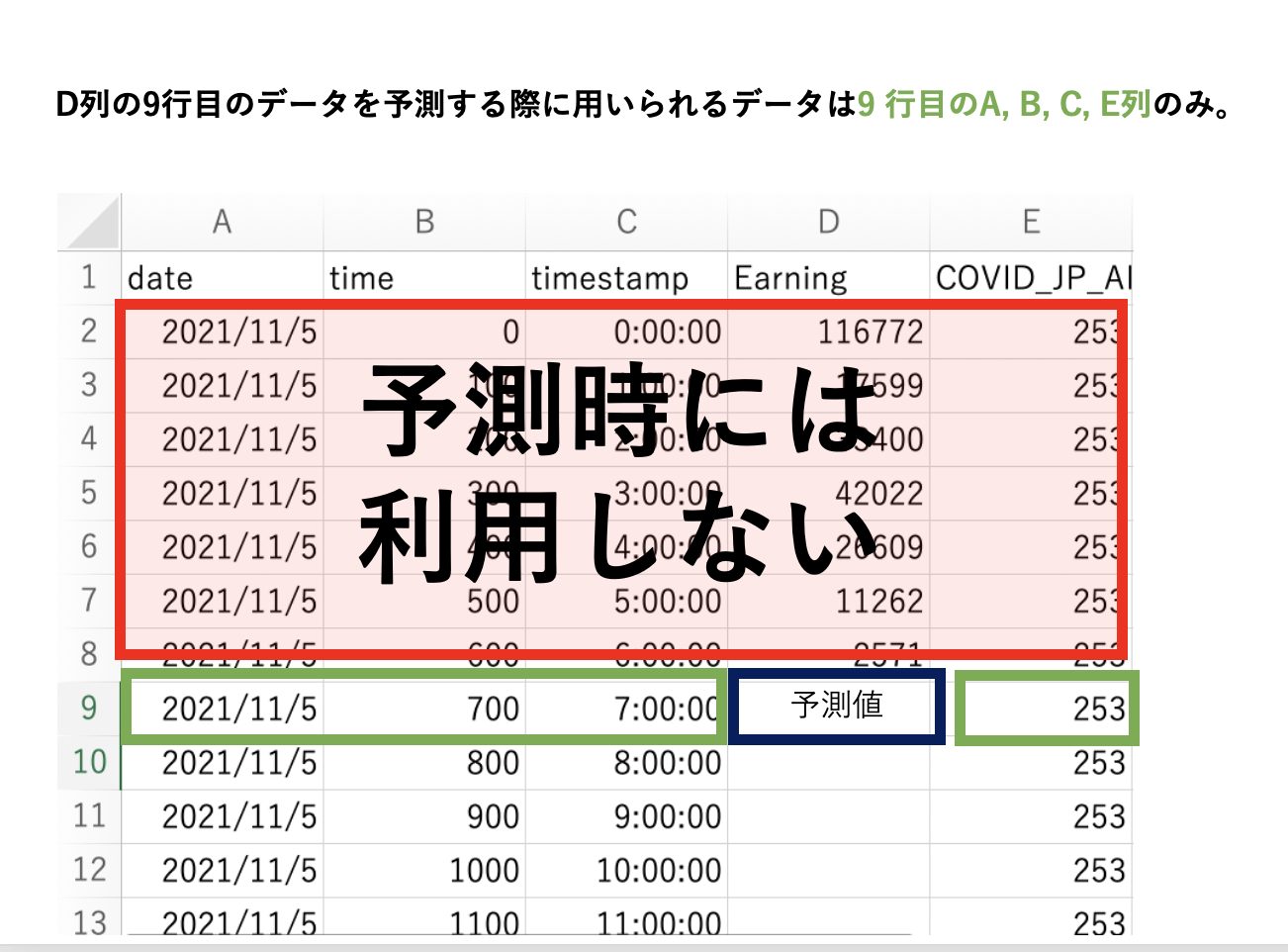 vertexAIのautoMLにおける回帰とは、予測したい列(ターゲット列)のデータを、同一行の特徴量のみから予測します。
上記の図でいえば、D列を予測したいときには9行目の「2021/11/5」「700」「7:00:00」「253」という特微量のみから予測するということです。
特微量:分析データの特徴を表した数値であり、予測の手掛かりとなります。
重要なのは、Vertex AIでは同一行の特徴量のみから回帰予測するという点です。
実際に予測する際に用いる未来の特徴量が、実際の特徴量と乖離しやすい特徴量でモデリングする場合は回帰を使うことは避けたほうがいいです。
つまり、過去データを用いて過去のターゲット列の予測する際には、予測する際の特徴量=実際の現実値となるので、2つの値に乖離はありません。なのでこの場合は回帰分析で精度が出ます。
しかし、実際の業務で未来のデータを用いて未来のターゲット列を予測する際には、予測する際の特徴量は予測値ですので、その特徴量の予測値と現実値との違いが大きかった場合は精度は出ません。つまり、精度が低くなるリスクが大きいということになります。
実際の予測業務を行わなければ特微量の予測値が現実の予測値と乖離しているかどうかがわからないため、業務を行うまで気づきにくいということが問題点です。
以上のことから、回帰分析ではモデリングに使う特徴量は時系列的な予測値ではなく条件値にすべきです。
以下、回帰分析を使用を判断する際の例です。
OKな特徴量の例:出店数、価格、商圏人口数、座席数などを使って売上の変化を予測
不適切な例:売上、平均客数、平均滞在時間などの特徴量を使って、明日以降の売上を予測
売上、平均客数、平均滞在時間などの特微量が予測値となってしまうため精度が出ないリスクが大きいです。
ただしこんな場合はOK:時系列を含まない場合
vertexAIのautoMLにおける回帰とは、予測したい列(ターゲット列)のデータを、同一行の特徴量のみから予測します。
上記の図でいえば、D列を予測したいときには9行目の「2021/11/5」「700」「7:00:00」「253」という特微量のみから予測するということです。
特微量:分析データの特徴を表した数値であり、予測の手掛かりとなります。
重要なのは、Vertex AIでは同一行の特徴量のみから回帰予測するという点です。
実際に予測する際に用いる未来の特徴量が、実際の特徴量と乖離しやすい特徴量でモデリングする場合は回帰を使うことは避けたほうがいいです。
つまり、過去データを用いて過去のターゲット列の予測する際には、予測する際の特徴量=実際の現実値となるので、2つの値に乖離はありません。なのでこの場合は回帰分析で精度が出ます。
しかし、実際の業務で未来のデータを用いて未来のターゲット列を予測する際には、予測する際の特徴量は予測値ですので、その特徴量の予測値と現実値との違いが大きかった場合は精度は出ません。つまり、精度が低くなるリスクが大きいということになります。
実際の予測業務を行わなければ特微量の予測値が現実の予測値と乖離しているかどうかがわからないため、業務を行うまで気づきにくいということが問題点です。
以上のことから、回帰分析ではモデリングに使う特徴量は時系列的な予測値ではなく条件値にすべきです。
以下、回帰分析を使用を判断する際の例です。
OKな特徴量の例:出店数、価格、商圏人口数、座席数などを使って売上の変化を予測
不適切な例:売上、平均客数、平均滞在時間などの特徴量を使って、明日以降の売上を予測
売上、平均客数、平均滞在時間などの特微量が予測値となってしまうため精度が出ないリスクが大きいです。
ただしこんな場合はOK:時系列を含まない場合
- 滞在時間が変化した際の売上がどうなるのかを予測
- コロナ陽性者数が変化した場合、売上がどうなるのかの予測
予測したいデータと同一行の特微量とそこまでの過去データを使う予測
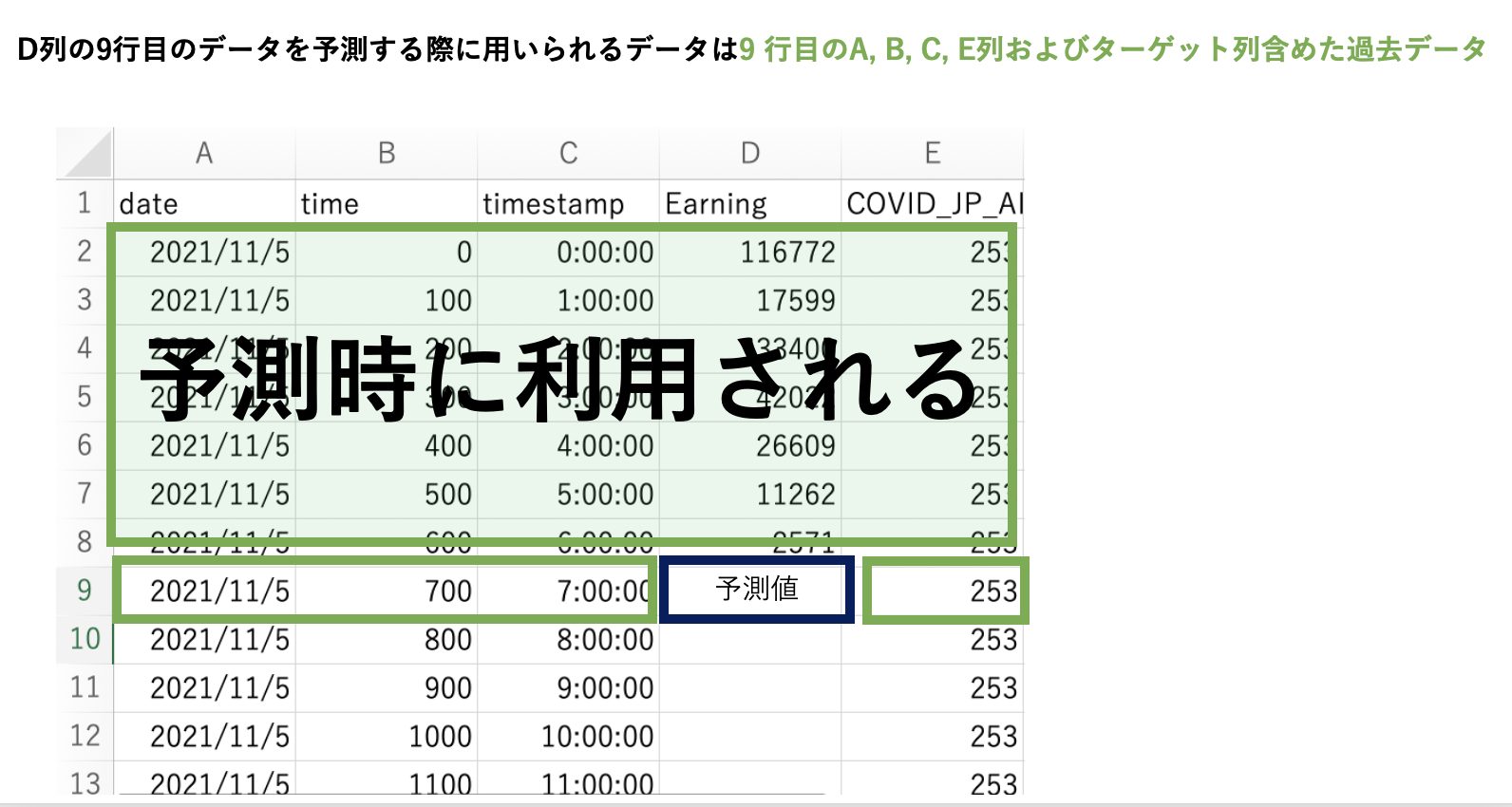 Vertex AIでのAutoMLにおける予測とは、予測したい列の特微量と過去データを用いて予測をします。
VertexAIのAutoMLでは主にARIMAモデルが用いられているるようですが、ディープラーニングを用いてモデル選択、チューニングしているようなので、中身はブラックブラックボックスとなっている。
トレーニングする際は、トレンドと周期性が区別つくようなデータセットが推奨されます。
Vertex AIでのAutoMLにおける予測とは、予測したい列の特微量と過去データを用いて予測をします。
VertexAIのAutoMLでは主にARIMAモデルが用いられているるようですが、ディープラーニングを用いてモデル選択、チューニングしているようなので、中身はブラックブラックボックスとなっている。
トレーニングする際は、トレンドと周期性が区別つくようなデータセットが推奨されます。









