今回は、データの可視化からレポートのPDF保存まで行うwebアプリを構築していきます。Databricks上でデプロイまでを行うことで、データ連携を容易に行うことが出来、データ活用の幅を広げることが出来ます。
はじめに
今回は、データの可視化からレポートのPDF保存まで行うwebアプリを構築していきます。Databricks上でデプロイまでを行うことで、データ連携を容易に行うことが出来、データ活用の幅を広げることが出来ます。
環境構築
まずは、Databricks上にデプロイするための準備を行っていきます。
詳細は以下のブログに記載されています。主な手順は
1,Databricksのコンピュートからアプリを作成
2,ユーザー認証の設定
3,必要ファイル(app.py, app.yaml, requirements.txt)の準備及びデプロイ
です。
環境が作成出来れば、app.py以下に必要なコードを記載することでwebアプリを構築することが出来ます。
参考:
https://blog.since2020.jp/bi/databricks-apps-deployment/
使用データ
今回使用するデータはKaggleの「Walmart Dataset」です。
このデータセットは米国の大手小売業者であるWalmartの売上データを含む、2010年2月5日から2012年11月1日までの時系列データセットです。各店舗ごとに売り上げが記載されています。
このデータを使用して各店舗ごとの売上の合計高を棒グラフで表示し、レポートを作成していきます。
参考:
https://www.kaggle.com/datasets/yasserh/walmart-dataset
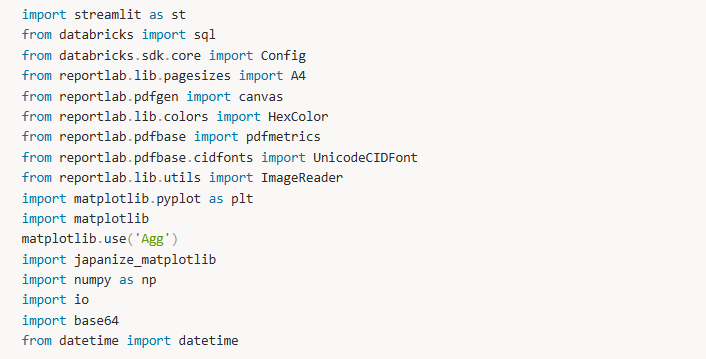
コードの記載






コードの解説
上記のコードでは5つの機能を関数として定義し、UI上で呼び出して使用しています。Databricksとの接続を行う関数以外の4つの関数とUIについて解説していきます。
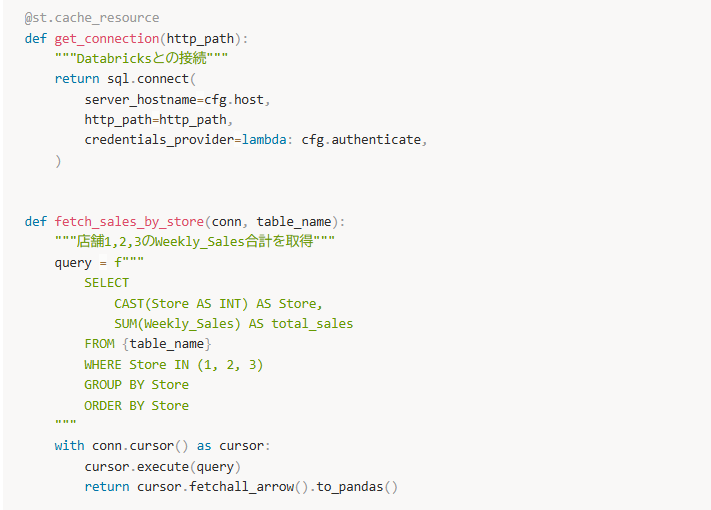
fetch_sales_by_store役割:
Databricksに接続し、店舗1,2,3それぞれのWeekly_Salesの合計を取得してPandas DataFrameとして返す関数です。記載しているqueryをcursor.execute()でDatabricks上に投げ、返ってきた結果をto_pandas()でPandas形式に変換しています。
create_bar_chart_base64役割: 各店舗名と各店舗に対応する売上高を入力として受け取り、棒グラフとして描画し、base64エンコードされた画像文字列として返す関数です。Streamlit上でレポートはHTML形式で作成しますが、base64形式にすることで、レポート化する際にHTMLに直接埋め込んで表示できます。
create_bar_chart_buffer役割: 各店舗名と各店舗に対応する売上高を入力として受け取り、棒グラフとして描画し、BytesIOバッファとして返す関数です。PDF生成時に、バッファを使用することでレポートにグラフを含めることが出来ます。
generate_pdf役割:
各店舗名と各店舗に対応する売上高、バッファ化されたグラフを受け取り、A4サイズのPDFレポートを生成し、BytesIOバッファとして返す関数です。タイトル、日付、棒グラフ、合計金額、フッターを含むシンプルなレポートを作成します。
大まかな流れとしては
1,pdfキャンパスの初期化
2,背景色の設定
3,タイトルの描写
4,作成日の描写
5,グラフの埋め込み
6,合計売上の描写
7,フッターの描写
8,pdfの書き込みと返り値の設定
です。
UI部分役割: StreamlitアプリのメインUI部分です。ユーザーの操作(ボタンクリック)に応じてデータ取得・グラフ表示・PDF保存を行います。
大まかな処理の流れは以下です。
1,初期の画面の表示
2,レポートの作成
- Databricksに接続
- SQLクエリの実行およびデータの取得
- 棒グラフを作成 → base64変換 → HTML埋め込みで表示
- 全店舗合計金額を表示
3,データ詳細テーブルを表示
4,PDF保存ボタン表示
- グラフ作成
- PDF生成
- ダウンロード
です。
挙動の確認
それでは作成した、アプリケーションを実際に動かして挙動を確認してみましょう。
まずデプロイしたアプリを起動すると以下のようになります。

次に「データを取得してグラフを表示」ボタンを押すとデータ取得が始まり、しばらく時間がたつと以下のように可視化した内容が表示されます。
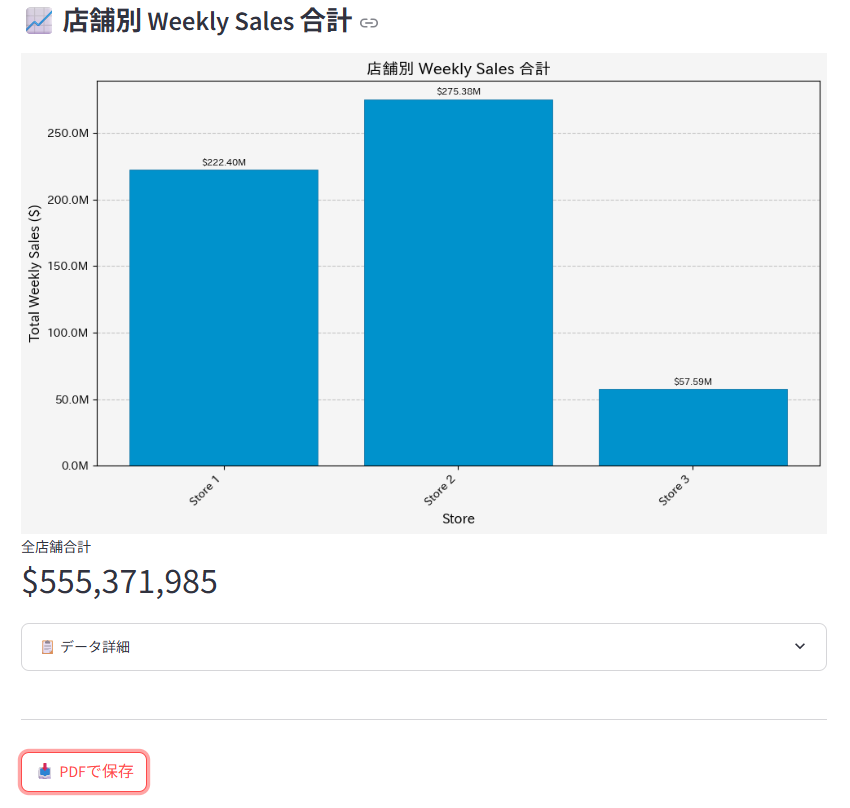
最後にPDFで保存ボタンを押すと以下のようなPDFが保存されます。
このように、データの取得→可視化→PDFの保存の流れをStreamlit上で構築することが出来ました。
終わりに
今回は、データの可視化からレポートのPDF保存まで行うwebアプリを構築しました。
今回の構成ではデータ取得から可視化のシンプルな形で作成しましたが、接続先のデータテーブルを増やしたり、LLMとAPIにより接続しインサイトを出すなど、応用が見込めます。
Databricksを使用し、データ活用をさらに飛躍させてみてください。