Databricks Data + AI Summit 2026 で行われた Infosys 協賛セッション 「Delivering Industry-scale AI on Databricks」 のレポートです。テーマは、AIを概念実証(PoC)から「エンタープライズ規模」へ広げるには何が必要か。登壇者は、その答えを ユニファイドデータ(統合データ)・スケーラブルなML・自律エージェント という3本柱に整理し、いずれも Databricks 上で実装する構成として示しました。
セッションを貫くメッセージは明快です。「AIのスケーリングはゴール(目的地)ではなく、旅(ジャーニー)である」。本稿では、登壇スライドに沿って要点をまとめます。
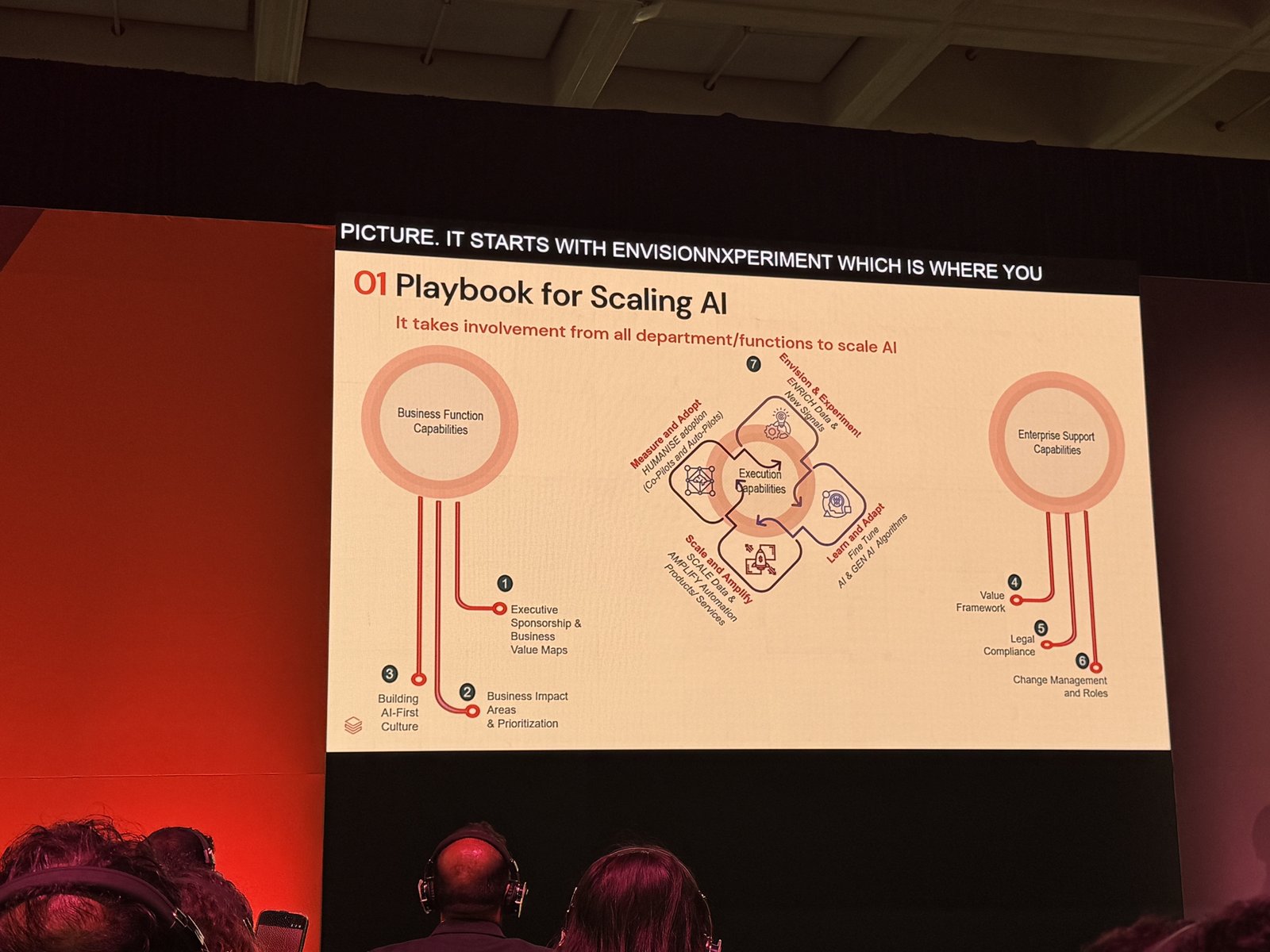
全部門を巻き込む「AIスケーリングのプレイブック」
冒頭で示されたのは、AIをスケールさせるには IT部門だけでなく、すべての部門・機能の関与が必要 だという前提でした。スライドでは、組織の能力を大きく2つの軸で整理しています。
- ビジネス機能側の能力:経営層のスポンサーシップとビジネス価値マップ、インパクト領域の特定と優先順位づけ、そして「AIファースト」な文化の醸成
- 全社支援側の能力:価値評価のフレームワーク、法務・コンプライアンス、変更管理と役割定義
これらが、中央の エグゼクティブ能力(PoCの実行 → 学習とアダプト) を取り囲む形で配置され、着手からおよそ90日でPoCを回し始める流れとして描かれていました。
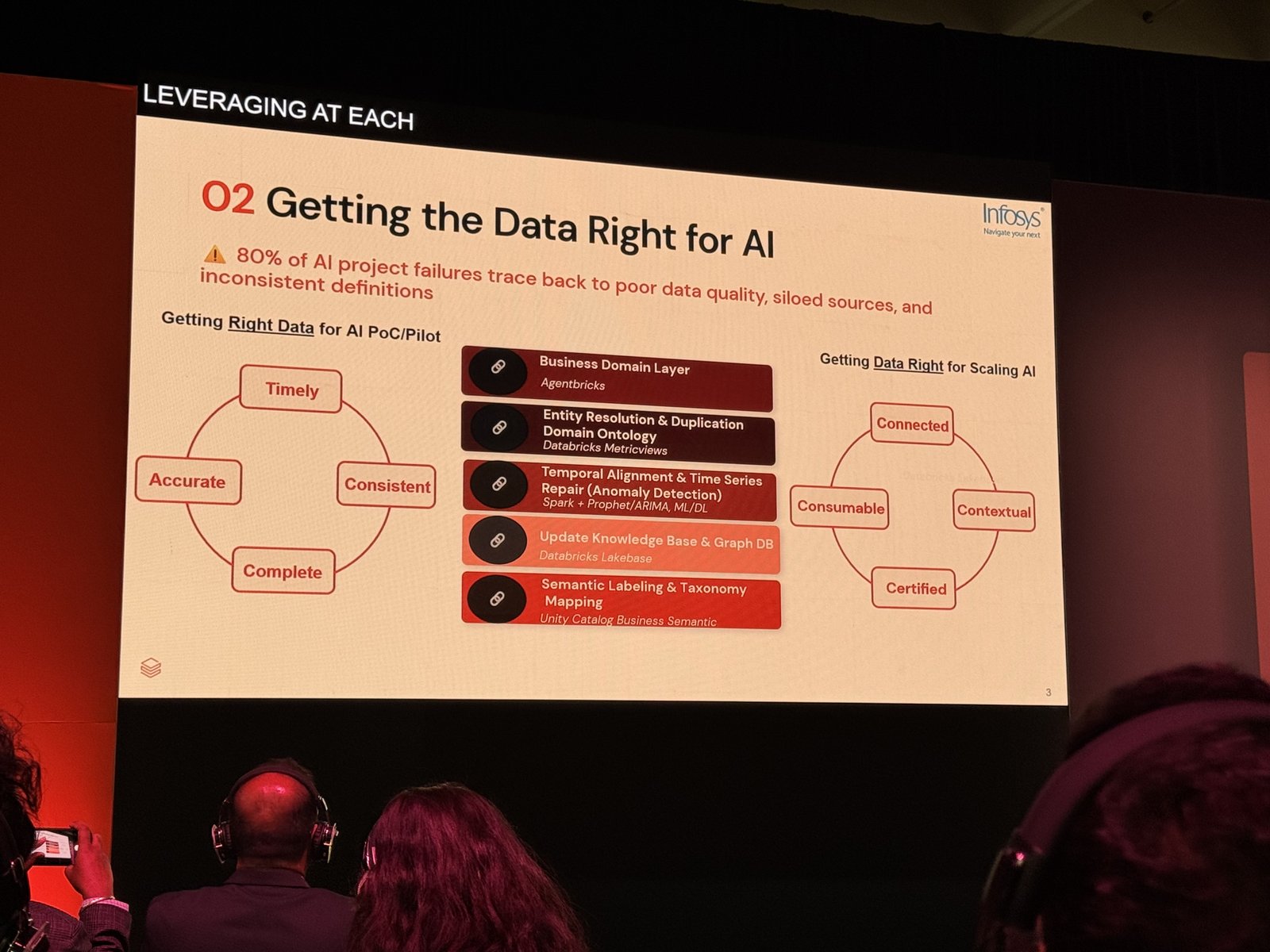
データを正しくする ― AIプロジェクト失敗の8割はデータに起因する
次のテーマはデータです。スライドは 「AIプロジェクトの失敗の80%は、データ品質の低さ・サイロ化したデータソース・定義の不整合に起因する」 と指摘しました。
ここで重要なのは、PoC段階とスケール段階で「正しいデータ」の意味が変わるという整理です。
- PoC/パイロット段階の「Right Data」:適時性(Timely)・一貫性(Consistent)・網羅性(Complete)・正確性(Accurate)
- スケール段階の「Data Right」:接続されている(Connected)・文脈を持つ(Contextual)・認証済み(Certified)・利用可能(Consumable)
つまりスケール局面では、データが単にきれいであること以上に、他のシステムとつながり、文脈の中で使える状態かが問われます。スライドでは、この「Data Right」をスケールで実現するための構成要素が、Databricksの機能とともに具体的に挙げられていました。
- ビジネスドメインレイヤー:Agent Bricks
- エンティティ解決・重複排除/ドメインオントロジー:Databricks Metric Views
- 時系列のアライメントと修復(異常検知):Spark + Prophet/ARIMA、ML/DL
- ナレッジベース・グラフDBの更新:Databricks Lakebase
- セマンティックラベリングとタクソノミーマッピング:Unity Catalog のビジネスセマンティクス
モデルを「規模」で運用する ― 1つの良いモデルより数千のモデルを統治する
3つ目はモデルの運用です。スライドは 「本当の難所は、優れたモデルを1つ作ることではない。数千のモデルを効率的に学習・比較・デプロイ・ガバナンスすることだ」 と述べます。
PoC段階のモデル構築と、PoC後のスケール段階とで、必要なケイパビリティが次のように対比されていました。
- PoC/パイロット段階:データクレンジング(Databricks)、特徴量エンジニアリング(Unity Catalog)、モデル実験(AutoML)、チューニング最適化(MLflow)
- PoC後のスケール段階:実験の一元管理(Databricks + MLflow)、チューニング最適化(AutoML + MLflow)、分散学習によるスケール(Spark + Distributed Compute)、MLOps基盤(MLflow + Model Serving + Workflows)、ガバナンスとリネージの強化(Unity Catalog + Monitoring Workflow)
PoCで通用した手作業の積み上げを、企業が自前で継続運用できる体制へ引き上げることがポイントだと強調されました。

エージェンティックOpsの基盤 ― 観測・評価・人間参加
エージェントの運用(Agentic Ops)については、「オフラインのテストとライブ本番のギャップを、継続的・リアルタイムなエージェント観測と自動評価で埋めることが、非決定的なエージェント・ワークフローを最適化するうえで必須」 という位置づけで、3つの柱が示されました。
- エージェント可観測性(Observability):多段のトラジェクトリを端から端まで記録し入出力を自動取得する詳細ロギング/OpenTelemetry標準のインジェスト(サーバーレスUnity Catalog連携)/自然言語でトレースを問い合わせ、エージェントの挙動を視覚的にデバッグするAI支援デバッグ
- 評価フレームワーク(Evaluation):ファインチューニング済みLLMが推論とツール実行を採点する「Agent-as-a-Judge」/LLMと決定論的メトリクスを組み合わせるカスタムスコアラー/合成対話ツリーを生成する本番前ストレステスト(シミュレーション)
- ヒューマン・イン・ザ・ループ:SME(業務有識者)が使いやすいレビューアプリ/修正を評価データセットに還流させ判定精度を高めるデータセット精緻化/オフラインとオンラインで同一スコアを保ち、精度ドリフトを継続追跡する品質統合

Databricksで描く「エージェンティック・ファースト」の設計図
ここまでの要素を束ねた全体アーキテクチャが 「エージェンティック・ファーストの設計図」 として提示されました。標語は 「意図的に進化させよ ― ゼロから作り直すな。ソフトウェアは行動の推進力を持つが、主導する主権は人間が握り続ける」。
レイヤー構成は上から次の通りです。
- Humans(人間):最終的な裁定者・オーケストレーター・エスカレーション先としての主権的監督
- Experience(AX):Genie、Apps
- Cognition plane(認知):Genie、Agent Bricks、MLflow
- Control plane(制御):Unity Catalog、AI/Agentic Gateway(セマンティックルーター、ガバナンスエンジン、Tool/MCPアダプタ、可観測性プレーン)
- Data plane(データ):Lakehouse、Lakebase(データファブリック(DaaP)、イベント/マルチモーダル、オントロジー/KG、エージェントメモリ、可観測性)
- Foundation(基盤):エッジ〜クラウドの連続体、既存API・マイクロサービス、プロトコルとして MCP・A2A・UCP/AP2
さらに、これらを縦断する2本のレールが置かれていました。
- ガバナンス&ガードレール:Cedar/OPAポリシー、サイドカーによる事前チェック、ゼロトラストID、改ざん防止監査、FinOps上限
- エージェンティック可観測性(Lakewatch):トレースレベルの可視化、推論チェーン、「エージェントがエージェントを監視する」仕組み、セマンティックドリフト警告、自動ロールバック

ケーススタディ:サプライチェーンを動かす6つのエージェント
具体例として、サプライチェーン領域で稼働する6つのエージェント(Agentic AI Studio)と、その効果指標が紹介されました。
- 需要センシング・エージェント:POS・SNSトレンド・天候・イベントを監視し90日需要予測をリアルタイム更新。乖離がしきい値を超えるとアラート → MAPE 22%改善
- 在庫最適化エージェント:動的な安全在庫の算出、補充発注、需要予測に基づく拠点間の在庫再配置 → 在庫 30%削減
- 調達エージェント:サプライヤー評価、API経由のスポット購買交渉、混乱時の代替調達、契約コンプライアンスの逸脱検知 → コスト 15%削減
- 物流・ルーティング・エージェント:キャリア選定の最適化、混乱時の再ルーティング、運賃交渉、ラストマイル配送順序の調整 → 定時率 18%改善
- リスクインテリジェンス・エージェント:ニュース・地政学シグナル・サプライヤー財務・天候をスキャンしてリスクをスコア化・順位づけし、緩和策を提示 → リスク検知 60%高速化
- カスタマーエクスペリエンス・エージェント:遅延の事前通知、欠品時の代替提案、「注文はどこ?(WISMO)」対応、例外の人間へのエスカレーション → CSAT 42%向上

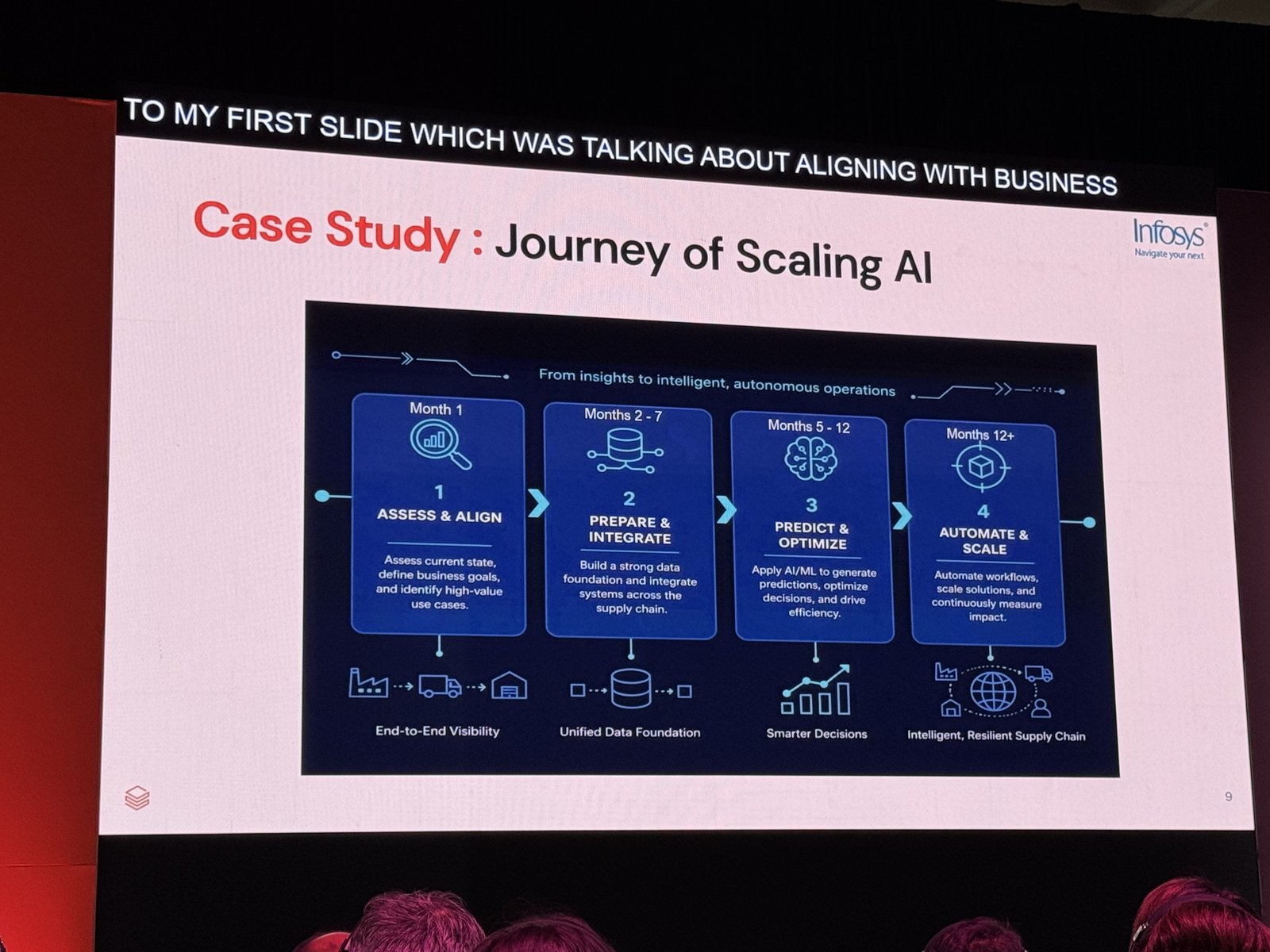
ケーススタディ:AIスケーリングの「旅」(12ヶ月のロードマップ)
最後に、同じくサプライチェーンを題材に、インサイトから自律オペレーションへ至る12ヶ月の段階的ロードマップが示されました。
- 1ヶ月目 ― 評価とアライン:現状評価、ビジネスゴールの定義、高価値ユースケースの特定 → エンドツーエンドの可視化
- 2〜7ヶ月目 ― 準備と統合:強固なデータ基盤の構築と、サプライチェーン横断のシステム統合 → 統合データ基盤
- 5〜12ヶ月目 ― 予測と最適化:AI/MLによる予測生成・意思決定の最適化・効率化 → よりスマートな意思決定
- 12ヶ月目以降 ― 自動化とスケール:ワークフローの自動化、ソリューションのスケール、インパクトの継続計測 → インテリジェントで強靭なサプライチェーン
各フェーズが重なり合いながら進む点が、「これは一度きりのプロジェクトではなく旅である」という主張を裏づけていました。
まとめ ― 「データで始め、AIで勝ち、エージェントでスケールする」
セッションは、冒頭から繰り返されたメッセージで締めくくられました。「エンタープライズ全体へのAIのスケーリングは、目的地ではなく旅である」。
その旅を支えるのが、本稿で見てきた ユニファイドデータ・スケーラブルなML・自律エージェント の3本柱です。そして登壇者は、進め方の合言葉として 「Start with data. Win with AI. Scale with agents.(データで始め、AIで勝ち、エージェントでスケールする)」 を提示し、まずはビジネスとのアラインと価値フレームワークの整理から着手することを勧めて、質疑応答へと移りました。