最新のモデルを社内に入れた。世界トップ級の頭脳のはずだ。なのに「うちの優良顧客って誰?」「先月の解約は何件?」と聞くと、平然と見当はずれの数字を返してくる。経営の現場で、この手の落胆を一度は味わった方は多いはずだ。
サンフランシスコで開かれたDatabricksの年次イベント「Data + AI Summit 2026」の基調講演は、まさにこの違和感の話から始まった。来場3万人超、スポンサー240社超。共同創業者兼CEOのAli Ghodsi氏は、その理由をひと言で切り分けた。AIはもう十分に賢い。足りないのは賢さではない。社内の文脈、つまりコンテキストだ、と。
この記事では、その「賢いのに使えない」という現象を、Summitで示された具体的な数字とともに分解していく。なぜ最新AIが“自社のデータ”でつまずくのか。問題はモデルの能力ではない、という話だ。
AIは賢い。でも“自社のこと”は知らない
まず、性能の話と社内の話を分けて考えたい。
Databricksは基調講演で、かなり強気な見立てを示した。Ghodsi氏いわく「AGI(汎用人工知能)はすでに実現した」。根拠として挙げたのが、難関ベンチマークでの正答率だ。専門家でも歯が立たないとされる超難問——Humanity's Last Exam級と呼ばれる、約2,500問規模の問題群——で、AIが半数以上に正答できるようになった。さらに将来像として、100体規模のAIエージェントが互いに連携して働く世界まで描いてみせた。
つまり、知能そのものはもう壁ではない、という立場である。
ところが、その同じAIに「自分の会社のこと」を尋ねると、途端に頼りなくなる。世界の難問は解けるのに、目の前の自社データはさっぱり。この落差こそが、Summit全体を貫く問題提起だった。残っている壁は、頭の良さではない。社内の文脈をどれだけAIに渡せるか。そこにある。
今のエージェントの限界——遅い・高い・当たらない
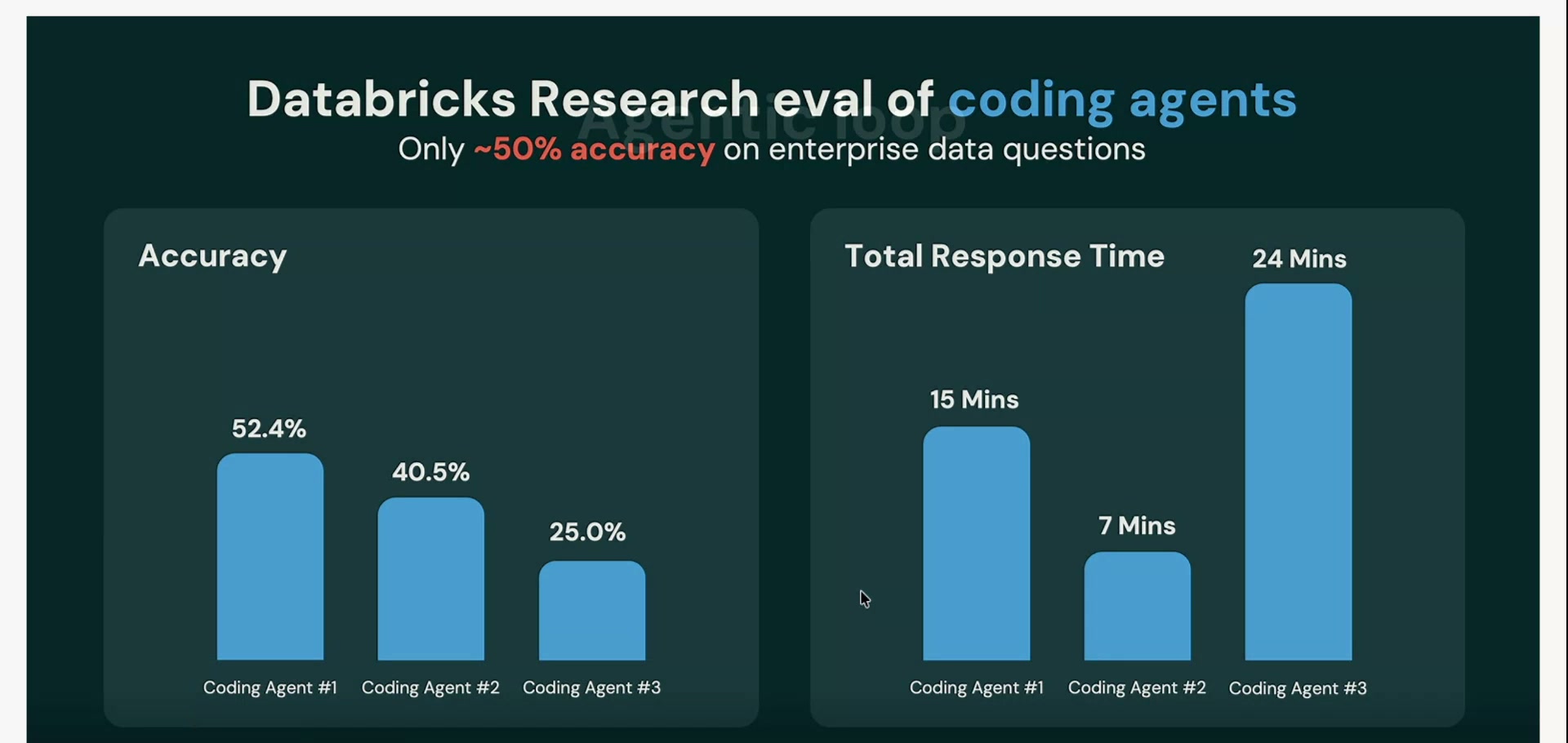
では、社内データにつなげたAIエージェントは、実際どのくらい使えるのか。Databricksは、この問いを正面から測りにいった。質問はすべて、社内で本当に飛び交うような業務上の問いだ。そして示されたのが、エージェントが社内データを扱うときに必ずぶつかる三つの壁だった。

結果は、3つのエージェントで正答率が52.4%、40.5%、25.0%。並べてみると、その低さがいっそう際立つ。
これは別物のチープなツールを試した数字ではない。最前線のデータエージェントに、Databricksのデータ問い合わせ機能をつないで本気で評価した結果である。それでも最良で52.4%。一番下に至っては25.0%、つまり4回に1回しか当たらない。社内データに関する質問で、最良でも約半分。これはほぼコイン投げと変わらない。経営判断の土台にこの精度のまま乗せるのは、率直に言って怖い。
問題は精度だけではなかった。時間も食う。デモでは、一つの問いに答えを出すまで15分以上かかった。社内データを延々と探し回るからだ。Summitの言葉を借りれば「ライブ検索」、必要な情報をその場その場で逐次探しにいく方式で、これに10〜15分。会議中にさっと確かめたい、という使い方には到底間に合わない。

そしてコストもかさむ。探し回るたびにトークン(AIの処理量に応じてかかる従量課金の単位)を消費する。デモで映ったエージェントは、AIが一度に抱えられる入力枠(コンテキスト)を96%まで使い切っていた。深く正確に調べさせようとするほど、料金メーターが回り続ける。遅い・高い・当たらない。この三つが同時に起きるのが、現状のエージェントの素の姿だ。
なぜ“探させる”と失敗するのか
数字の背景には、構造的な理由がある。
今のエージェントは、社内の地図を持っていない。だから質問のたびに、ゼロから当たりをつけて社内を探索する。どのテーブルに売上があるのか、「優良顧客」を社内ではどう定義しているのか、解約はいつの時点でカウントするのか。そうした“社内の常識”を知らないまま、手探りで歩き回る。Summitのスライドは、この様子を「あてどなく探し回るから品質が落ちる」と言い切っていた。
そして、その探索の様子そのものが画面に映し出された。

ログを追うと、エージェントはテーブルを探しては当たりをつけ、クエリを投げ、つまずいては書き直すことを延々と繰り返している。地図を持たずに毎回ゼロから道を探すのだから、当然、時間もトークンもかさむ。しかも、そうやって苦労して深く探させたところで、正答率は半分どまりだ。
ここに、現状のジレンマが見える。精度を上げようと丁寧に探させれば、コストと時間が跳ね上がる。コストと時間を抑えようと探索を浅くすれば、精度がさらに落ちる。「探させる」という方式に立っているかぎり、このトレードオフからは抜け出せない。
では、文脈はどう渡すのか
ここまでをまとめると、問題はAIの賢さではなかった。社内の文脈、すなわちコンテキストをAIが持っていないこと。そして、その文脈を「その都度探させる」やり方が、遅さ・高さ・不正確さを生んでいたこと。
ならば発想を逆にすればいい。探させるのをやめて、先に渡してしまう。
社内の概念・用語・ルールと、その関係性を、AIが読める形であらかじめ整理しておく。Summitでこの「意味の地図」にあたるものとして提示されたのが、オントロジーという考え方だ。耳慣れない言葉だが、中身は難しくない。「自社では何をどう呼び、どう数え、何と何がつながっているか」を書き出した、AIのための辞書のようなものと捉えてもらえばいい。
地図を先に手渡されたAIは、探し回らずに済む。だから速く、安く、正確になる。これがDatabricksの答えだった。その具体的な仕組み「Genie Ontology」がどう動くのかは、次の記事で詳しく見ていく。
押さえどころ
社内でAI活用が進まないとき、つい「もっと賢いモデルに替えれば」と考えがちだ。だがSummitの数字が突きつけたのは、その方向では半分しか当たらない、という現実だった。最前線のエージェントを使っても、社内データの問いには52.4%。原因はモデルではなく、自社の文脈を渡せていないことにある。
問うべきは、こうだ。自社の「優良顧客とは」「解約の数え方」「主要KPIの定義」は、人の頭の中や散らばった資料にあるだけではないか。それをAIが読める形に整理できているか。モデル選びの前に、渡すべき地図が自社にあるかどうか。出発点はそこにある。
関連:生成AIに「自社の文脈」を渡すサービス「Ontology Boost」
では、その“地図”をどう用意するか——。これは、私たちSiNCEが提供を開始したサービス 「Ontology Boost」 がまさに取り組む領域です。生成AI(ChatGPT・Claude・Geminiなど)が、御社固有の用語・KPI・業務ルールに沿って"根拠のある"回答を返せるよう、知識基盤(オントロジー)の構築・接続・運用までを一貫支援します。