
生成AIという言葉を耳にする機会は増えましたが、「なぜ文章や画像を自然に生成できるのか」「本当に理解して考えているのか」を正しく説明できる人は多くありません。
生成AIは、人間のように意味を理解して思考しているわけではなく、大量のデータをもとに 次に来る情報を確率的に予測する仕組み によって成り立っています。
本記事では、生成AIの基本的な仕組み、AI技術の歴史、自然言語処理、Transformer、大規模言語モデル(LLM)までを整理しながら、
「なぜ生成AIはそれらしく振る舞えるのか」「なぜ間違いが起こるのか」をわかりやすく解説します。
生成AIを正しく理解し、安心して活用するための基礎知識として、ぜひ最後までご覧ください。
生成AIとは何か?基本的な仕組みをわかりやすく解説
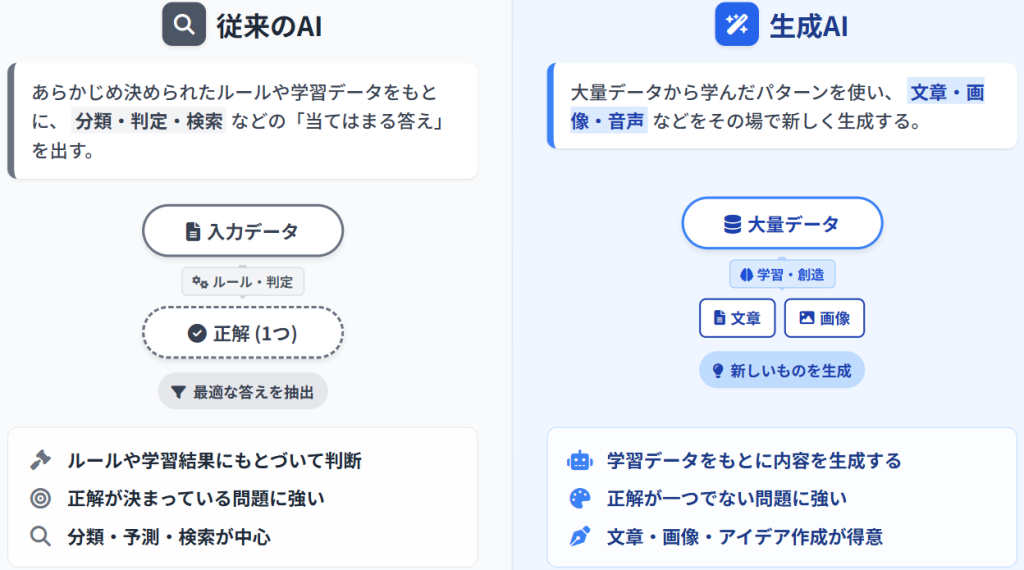
生成AIとは、大量のデータをもとに「次に来る情報を確率的に予測しながら、新しいコンテンツを生成する仕組みを持つAI」です。
従来のAIは、あらかじめ決められたルールや過去のデータを使って「正解を探す」「該当する情報を提示する」ことが中心でした。一方、生成AIは、学習したデータのパターンをもとに、その場の文脈に合った“それらしい答え”を一から組み立てて出力します。
この点が、生成AIが「文章を書く」「画像を描く」「音声を作る」といった、人間の創作に近い振る舞いをできる理由です。
生成AIの仕組みをさらに噛み砕くと、次のように考えることができます。
人が文章を書くとき、「次はどんな言葉を続ければ自然か」を無意識に考えています。生成AIも同じように、入力された指示(プロンプト)や直前の文脈をもとに、次に続く単語や要素として最も確率が高いものを選び続けています。
この「予測 → 選択」を高速かつ大規模に繰り返すことで、自然な文章や画像が完成します。
生成AIの仕組みは、事実を検索したり、意図を人間のように理解したりするものではありません。あくまで、過去に学習した膨大なデータから、文脈上もっとも自然に見える結果を確率的に導き出しているに過ぎません。
それでも、人間にとって違和感の少ない出力ができるのは、学習データの量と計算処理の精度が圧倒的に高いためです。
AIの種類一覧【2026年最新】生成AIの種類の使い分けと比較表
AIエージェントとは?生成AIとの違い・仕組み・できることをわかりやすく解説
生成AIの仕組みを理解するためのAI技術の歴史
生成AIの仕組みを正しく理解するには、AIがどのような歴史をたどって進化してきたのかを知ることが欠かせません。
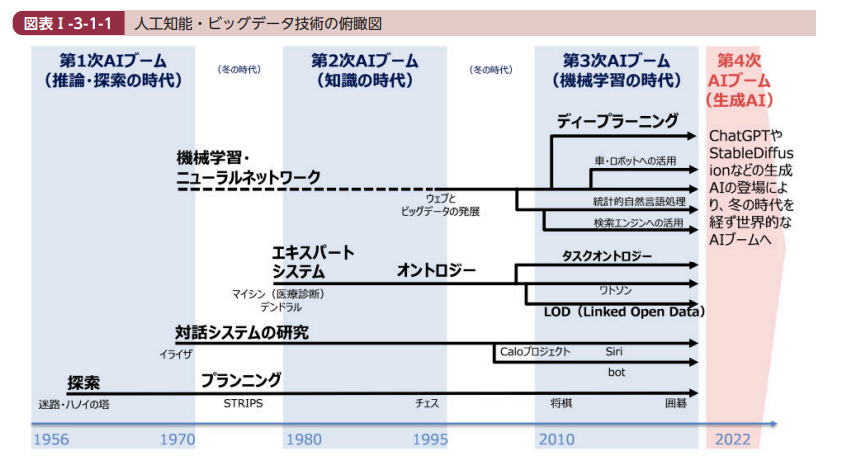
生成AIは突如として登場した技術ではなく、70年以上にわたる人工知能研究の延長線上に生まれた存在です。
第1次AIブーム|推論・探索が中心だった時代(1950年代〜1960年代)
人工知能(AI)という言葉は、1956年に開催されたダートマス会議で提唱されました。
この時代のAIは、「推論」や「探索」といった論理的処理を中心に、人間の思考を記号として扱う仕組みでした。
ただし、当時のコンピュータ性能やデータ量には限界があり、迷路やパズルのような簡単な問題しか扱えず、実社会での活用は難しかったため、やがて研究は停滞します(いわゆるAIの冬の時代)。
第2次AIブーム|知識を教え込むAIの時代(1980年代〜1990年代)
1980年代になると、専門家の知識をルールとして組み込む「エキスパートシステム」が登場し、第2次AIブームが起こります。
しかし、この仕組みでは 人間がすべての知識を手作業で定義する必要があり、
複雑で変化の多い現実世界を扱うには限界がありました。
結果として、AIは再び実用化の壁に直面し、研究は停滞期に入ります
第3次AIブーム|機械学習・ディープラーニングの登場(2000年代〜)
2000年代以降、インターネットの普及により大量のデータが利用可能になり、
計算能力の向上とともに 機械学習、特にディープラーニング が急速に発展しました。
この時代のAIは、
- 画像認識
- 音声認識
- 自然言語処理
といった分野で実用レベルに到達し、社会に広く浸透していきます。
ただし、この段階のAIは「認識」には強い一方で、文章を生成する・文脈を深く理解することはまだ得意ではありませんでした
第4次AIブーム|生成AIの登場と仕組みの転換(2022年〜)
こうした流れの中で、ディープラーニングを基盤にしつつ、Transformer や 大規模言語モデル(LLM) が登場したことで状況が一変します。
出典:AIsmiley|大規模言語モデル(LLM)とは?仕組み・種類・活用サービス・課題をわかりやすく解説
2022年に対話型AIであるChatGPTが公開されると、自然な文章生成や対話が誰でも簡単に使える形で広まり、現在は 第4次AIブーム(生成AIの時代) に入ったと位置付けられています
【2026年最新】LLM比較表・性能ランキング!LLM比較サイト一覧
生成AIの仕組みの本質は、
- 大量データによる事前学習
- 文脈全体を考慮した確率予測
- 多様なタスクに転用できる基盤モデル
にあります。
これにより、従来のAIでは難しかった「文章・画像・音声を生成する」という振る舞いが可能になりました。
生成AIの仕組みの土台となる自然言語処理とは
生成AIの仕組みを理解するうえで、避けて通れないのが自然言語処理(NLP:Natural Language Processing)です。
自然言語処理とは、人間が日常的に使っている言葉(自然言語)を、コンピュータで扱える形に変換し、処理するための技術分野を指します。
ここで重要なのは、自然言語処理が「言葉の意味を人間のように理解する技術」ではないという点です。
生成AIの仕組みにおける自然言語処理は、言葉を“意味”として理解するのではなく、“データとして扱う”ことを出発点にしています。
言葉を「理解」するのではなく「並び方」を学ぶ
人間は文章を読むとき、無意識のうちに意味や意図を理解しています。しかし、コンピュータにとって言葉は、最初は単なる文字や記号の集まりにすぎません。
そこで自然言語処理では、
- 単語を細かい単位(トークン)に分け
- どの言葉の後に、どの言葉が続きやすいか
- 文全体の中で、言葉同士がどのような関係を持っているか
といった 「言葉の使われ方のパターン」 を大量のデータから学習させます。
以下は、自然言語処理に使われる形態素解析の仕組みです。

言語モデリングとは何か
言語モデリングとは、「ある言葉が与えられたとき、次にどの言葉が続く確率が高いか」をモデル化する考え方です。
例えば、
「私は今日、会社に___」
という文章があった場合、人は自然に
「行きました」「行きます」「向かいました」
といった言葉を思い浮かべます。
生成AIの仕組みもこれと同じで、次に来る可能性が高い言葉を確率的に予測することで文章を組み立てています。
この予測を一度だけでなく、単語ごとに連続して行うことで、長く自然な文章が生成されるのです。
生成AIの仕組みを変えたTransformerとは何か
Transformer(トランスフォーマー)とは、2017年にGoogleの研究者によって発表された機械学習モデルで、現在の生成AIの中核を担う仕組みです。
ChatGPTやBERTといった代表的な生成AIは、いずれもこのTransformerをベースに作られています。
Transformerが登場した最大の意義は、文章全体を一度に見渡しながら処理できる仕組みを実現した点にあります。
これにより、生成AIは長い文章でも文脈を保ったまま、自然な出力ができるようになりました。
Transformer以前の仕組みが抱えていた課題
Transformerが登場する以前、自然言語処理では、RNN(回帰型ニューラルネットワーク)やLSTM(長・短期記憶)といったモデルが主流でした。
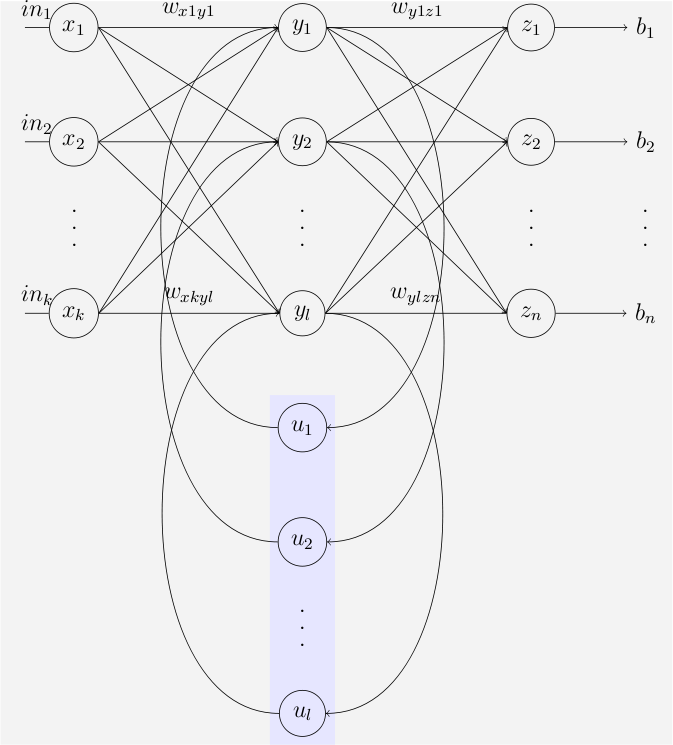
※エルマンネットワークとジョーダンネットワークは「単純回帰型ネットワーク(SRN)」としても知られています。(上記、Wikipediaによるエルマンネットワークとジョーダンネットワークに関する説明より抜粋)
これらのモデルは、
- 文を先頭から末尾まで 順番に処理する
- 過去の情報を「状態」として引き継ぐ
という仕組みを持っていました。
しかしこの方法には問題があり、文章が長くなるほど、前半の情報が後半で失われやすいという欠点がありました。
たとえば長文の翻訳や要約では、文の冒頭に出てきた主語や前提条件が、文末でうまく反映されないケースが多く見られたのです。
Transformerの最大の特徴|逐次処理をやめた
Transformerの画期的な点は、文章を「順番に」処理するのをやめたことです。
Transformerでは、文を構成するすべての単語(トークン)を同時に処理し、
それぞれの単語が
- 文中のどの単語と
- どれくらい強く関係しているか
を一気に計算します。
この仕組みによって、
- 文全体の文脈を常に考慮できる
- 長い文章でも意味のつながりを保てる
- 並列処理が可能になり、学習速度も大幅に向上する
という大きなメリットが生まれました。
「注意機構(アテンション)」が中核の仕組み
Transformerの中心にあるのが、注意機構(アテンション)です。
アテンションとは、「ある単語を見るときに、文中のどの単語に注目すべきか」を重み付けする仕組みです。
例えば翻訳の場合、
- 出力する単語が
- 入力文のどの単語に強く対応しているか
を学習し、必要な情報を直接参照できます。
この仕組みにより、遠く離れた単語同士の関係も正確に捉えられるようになりました。これが、Transformerが「文脈を理解しているように見える」理由の一つです。
エンコーダ・デコーダ構造を持つTransformer
Transformerは、基本的に、エンコーダ(理解する役割) とデコーダ(生成する役割)
の2つから構成されています。
トランスフォーマーニューラルネットワークアーキテクチャには、連携して最終出力を生成する複数のソフトウェアレイヤーがあります。
以下は、変換アーキテクチャの成分です。
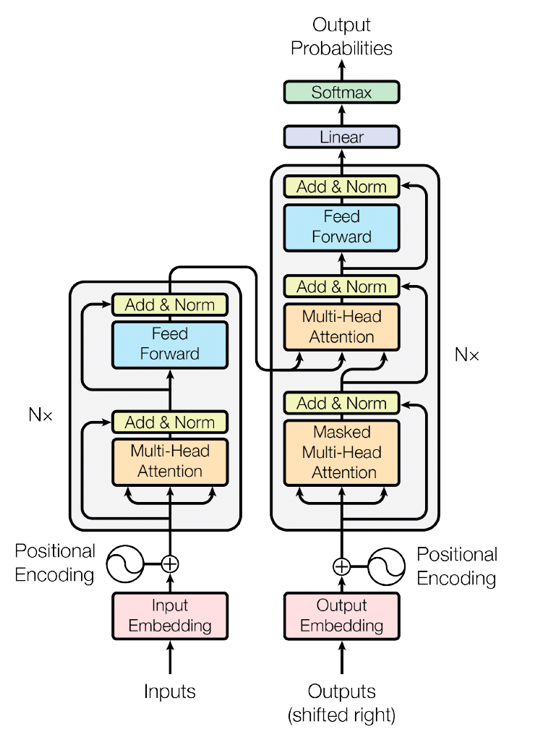
出典:AWS|人工知能におけるトランスフォーマーとは何ですか?
左の灰色の部分が、エンコーダで、右側がデコーダです。Udemyメディアでも同じように紹介されています。
- エンコーダは、入力された文章全体を読み取り、単語同士の関係性を反映した「特徴表現」を作る
- デコーダは、その特徴表現をもとに、次に来る単語を一つずつ生成していく
この構造によって、翻訳・要約・質問応答・文章生成といった多くのタスクが
同じ仕組みで処理できるようになりました。
なぜTransformerが生成AIの標準になったのか
Transformerが生成AIの基盤として広く採用された理由は、次の3点に集約できます。
- 文全体を同時に扱えるため、文脈理解に強い
- 並列処理が可能で、大規模データの学習に向いている
- 事前学習+ファインチューニングに適している
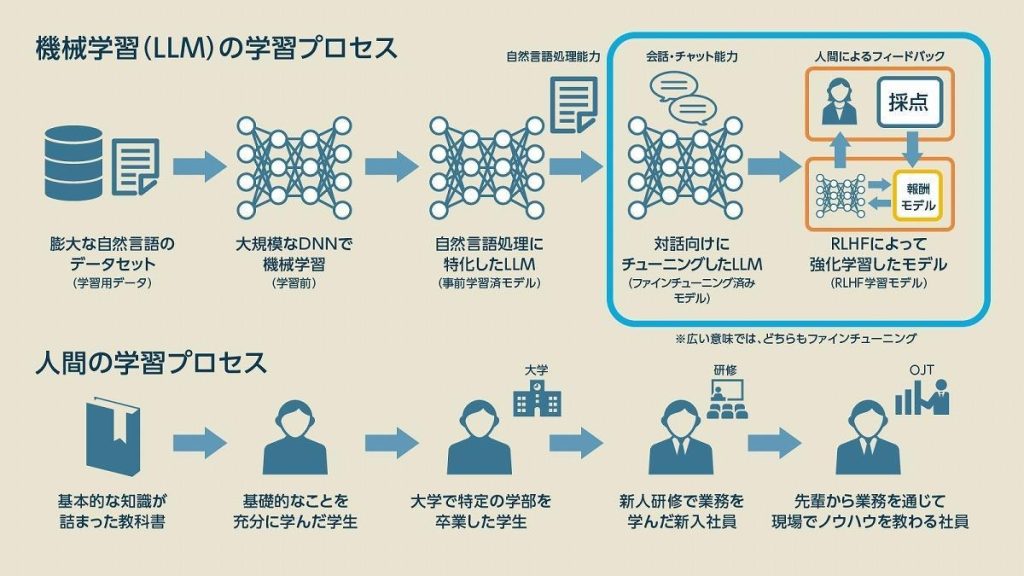
出典:ビジネス+IT|RLHF(人間による評価を利用した強化学習)とは?ファインチューニングとの違いも解説
この特性が、GPTやBERTのような 大規模言語モデル(LLM) の登場を可能にし、現在の生成AIブームにつながっています。
AIエージェントフレームワークとは?【2026年】人気のフレームワークを比較
MCPとは?生成AI・AIエージェントの連携に必要な共通プロトコルをわかりやすく解説
生成AIの仕組みを3ステップでわかりやすく解説
生成AIの仕組みは、一見すると複雑に思えますが、全体の流れはとてもシンプルです。
本質的には、「学習する → 予測する → 精度を高める」という3つの流れで成り立っています。
ここでは、文章を生成するケースを例に、生成AIがどのように動いているのかを順番に見ていきましょう。
①生成AIが大量のデータを学習する仕組み
最初に必要なのは「学習」です。生成AIは、インターネット上の文章や書籍、記事など、膨大なテキストデータを使って学習します。
この学習で行っているのは、文章を丸暗記することではありません。
- どの言葉のあとに
- どの言葉が続きやすいか
- どんな言葉の組み合わせが自然か
といった 言葉の使われ方の傾向やパターン を身につけています。
人が文章を書くときに、「この場面ならこの表現が自然だな」と感覚的に判断しているのと似ています。
生成AIはこの感覚を、大量のデータと計算によって再現しているのです。
②生成AIがプロンプトから答えを予測する仕組み
次に、ユーザーが入力した指示や質問、いわゆるプロンプトを受け取ります。
生成AIは、このプロンプトをそのまま理解しているわけではありません。
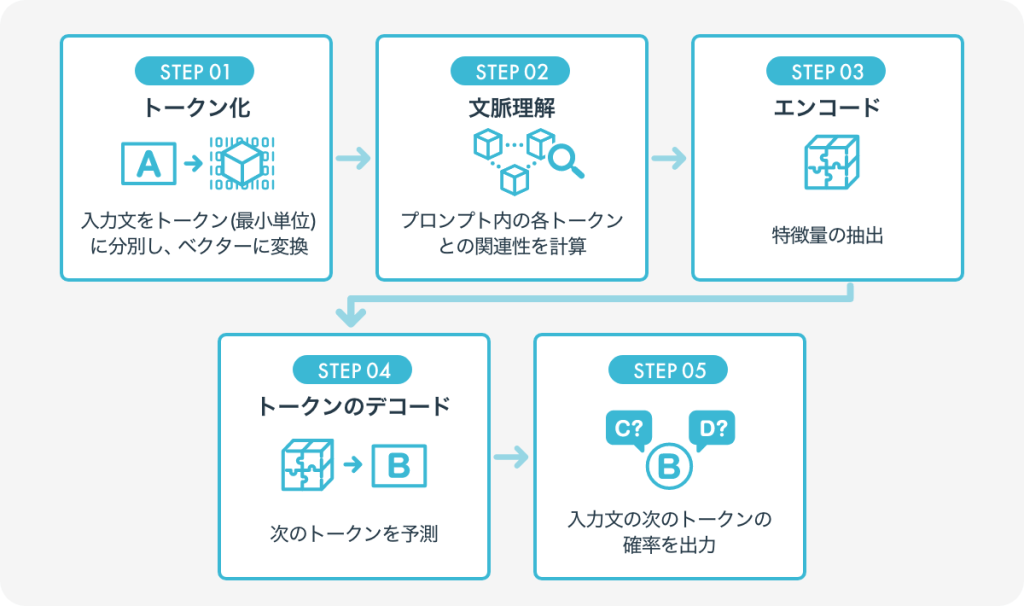
文章を細かい単位(トークン)に分解し、「次にどの単語が来る確率が高いか」を計算します。
例えば、「お客様へのお礼メールを作成してください」と入力された場合、生成AIは
- ビジネス文書の文脈
- 定型的な表現
- これまでに学習したメール文例
を参考にしながら、一語ずつ順番に予測して文章を組み立てていきます。
この処理を高速で繰り返すことで、人が書いたように自然な文章が完成します。
③生成AIの予測精度を高める仕組み
生成AIは、最初から完璧な答えを出せるわけではありません。そこで重要になるのが、精度を高めるための調整です。
具体的には、
- 追加データによる学習
- 誤った出力に対するフィードバック
- 出力のクセを整える調整
などが行われます。
この仕組みによって、
- 不自然な表現が減る
- 回答の一貫性が高まる
- 人にとって使いやすい出力になる
といった改善が積み重ねられていきます。
【事例あり】自動化AIツール比較20選・AIで自動化できる業務とは?2026年最新
生成AIの業務効率化事例12選【2026年】業種別・職種別にわかるAI業務効率化
生成AIの仕組み上、間違いが起こる理由とは?
生成AIは非常に自然な文章を生成できる一方で、もっともらしい間違いを自信満々に出すことがある点(ハルシネーション)がよく指摘されます。
これは偶然でも欠陥でもなく、生成AIの仕組みそのものに由来する特性です。
生成AIがなぜ間違えるのかを理解するには、「生成AIは何をしていて、何をしていないのか」を整理する必要があります。
生成AIは「事実を調べている」わけではない
まず押さえておきたいのは、生成AIは検索エンジンのように事実を確認して回答しているわけではないという点です。
そのため、以下のような場合であっても、「それっぽい文脈」が成立すれば、違和感のない文章として生成されてしまうことがあります。
- 実在しない人物
- 架空の統計データ
- 存在しない出来事
確率で文章を作る仕組みが誤りを生む
生成AIは、次に来る単語を「正しいかどうか」ではなく、「確率的に自然かどうか」で選んでいます。
この仕組みでは、
- よくある表現
- 多くの文章で使われがちな言い回し
ほど選ばれやすくなります。一方で、正確だが珍しい情報や、文脈依存の細かい条件は、反映されにくい場合があります。
その結果、読みやすいが事実としては誤っている文章が生まれることがあります。これが「ハルシネーション(幻覚)」と呼ばれる現象です。
関連記事:RPAとAIの違いは?向いている業務・活用例・ツール選びと注意点
学習データに含まれる偏りや不足の影響
生成AIは、過去に存在したデータをもとに学習しています。
そのため、以下のような分野については、正確な出力ができないことがあります。
- 学習データが少ない分野
- 古い情報しか含まれていないテーマ
- 意見や立場が偏っている内容
特に、以下は生成AIの学習範囲外であることが多く、Web検索機能を使わない限り、推測による回答になりやすい点には注意が必要です。
- 最新のニュース
- 専門性が高い分野
- 社内ルールや独自情報
生成AIの仕組みから分かる得意なこと・苦手なこと
生成AIは万能な存在ではありません。しかし、仕組みを理解すると「何が得意で、何が苦手か」がはっきり見えてきます。
この章では、これまで解説してきた生成AIの仕組みを踏まえて、生成AIが力を発揮しやすい領域と、注意が必要な領域を整理します。
生成AIの仕組みが得意とすること
生成AIが得意なのは、過去の膨大なデータに基づいて、文脈に合ったアウトプットを素早く作ることです。
具体的には、次のような作業に向いています。
- 文章の作成や言い換え
- 要約や整理
- アイデア出しやたたき台の作成
- 翻訳や表現の調整
これらの作業は、「正解が一つに決まらない」ことが多く、自然さ・網羅性・スピードが重視されます。
生成AIは、「次に来る言葉を予測する」という仕組みを活かし、人が考えるよりも短時間で、一定品質のアウトプットを出すことができます。
そのため、「0から文章を考える、情報を整理して構造化する」といった、思考の初動を支援する役割に非常に向いています。
生成AIの仕組みが苦手とすること
一方で、生成AIの仕組み上、苦手なことも明確に存在します。代表的なのは、事実確認や正確性が求められる作業です。
生成AIは、
- データベースを検索して裏取りをする
- 情報の真偽を判断する
といった処理を行っていません。
あくまで、文脈上もっとも自然に見える文章を生成しているため、内容の正しさは保証されません。
そのため、以下のような用途では、人による確認や判断が不可欠です。
- 法律・医療・金融などの専門分野
- 最新ニュースや数値情報
- 社内ルールや契約条件の最終判断
生成AIの仕組みに関するよくある質問
生成AIの仕組みに関するよくある質問をまとめています。
- 生成AIは本当に「考えて」文章を作っているのですか?
-
生成AIは学習した大量のデータをもとに、文脈上もっとも自然に続く言葉を確率的に予測しながら文章を生成しています。そのため、理解しているように見えても、実際は統計的な予測の結果です。
- 生成AIと従来のAIは、仕組みとして何が違うのですか?
-
従来のAIは、決められたルールや既存データをもとに「正解を探す」ことが中心でした。一方、生成AIは大量のデータから学習したパターンを使い、その場の文脈に合った新しいコンテンツを生成する点が大きく異なります。
- 形態素解析やトークン化は、生成AIにとってなぜ重要なのですか?
-
生成AIは文章をそのまま理解するのではなく、形態素解析などを通じて単語や記号の単位(トークン)に分解して処理します。この分解があるからこそ、言葉の並び方や関係性をデータとして学習・予測できるようになります。











