
Data + AI Summit 2026。Databricks のシニアソリューションアーキテクト Pavithra Rao 氏のセッション 「From MLOps to AgentOps」 は、ひとつの実話から始まった。デモで感心させるエージェントと、本番で頼れるエージェントの間には、深い谷がある。その谷を、組織はどう埋めるのか。
本稿では、その谷の正体(MLOps→LLMOps→AgentOpsの断絶)と、信頼できる自律エージェントを出荷するための4つの意思決定——アーキテクチャ・評価・ガバナンス・昇格——を、デモとともに追う。
「チャットボットは別の法人格です」——ある航空会社が敗れた日
祖母を亡くした男性が、航空会社のサイトでフライトを予約しようとした。AIアシスタントに「忌引きの払い戻しポリシーはあるか」と尋ねると、エージェントは自信たっぷりに「まず全額払って、90日以内に払い戻しを申請すればよい」と答えた。だが実際に申請すると、航空会社は「そんなポリシーは存在しない」と突っぱねる。裁判で航空会社は、「チャットボットは別個の法人格であり、当社は責任を負わない」とまで主張した。
結末はご存じの通り。2024年2月、審判所は Air Canada に払い戻しの履行を命じた。教訓は重い。自社のサイトに置いたエージェントの応答を、チーム全体で裏書きできないなら、その状態で本番に出してはいけない。失う代償は、お金だけではない。信頼とブランドだ。

学んできたルールが、なぜエージェントに通じないのか
機械学習をこの業界で扱ってきて12〜13年。私たちはMLを十分に“しつけ”てきたはずだ。なのに、なぜエージェントはルールを破るのか。Pavithra 氏は、運用の進化を3つの波で説明した。
MLOps(2010年代)は、ドリフト監視・オブザーバビリティの規律をくれた。ひとつの入力にひとつの出力が返る、決定論的な世界だ。LLMOps(2020年代前半)でも、言語モデルとプロンプトの単一呼び出しなら、出力の幅はまだ見通せた。ところが AgentOps(2024年以降)は、これらのルールを根こそぎ壊す。エージェントは「多数のツールを持つLLM」であり、その挙動は予測できない。ドリフトをどう監視するか、性能をどう追うか——MLOpsで学んだ手法は、そのままでは効かない。

エージェントは「モデル」ではなく「動くシステム」だ
なぜ予測できないのか。エージェントは単なるモデルではないからだ。Pavithra 氏は、LLM + プロンプト、RAG(検索拡張生成)、ツール呼び出しエージェント、マルチエージェントという4つのパターンを、複雑度の階段として並べた。Q&Aから文書検索、タスク自動化、複雑なワークフローへ——上がるほど、自律性とともに不確実性が増す。
エージェントを人体にたとえるなら、LLMは「脳」で推論を担う。だが実際に行動するのは、コンテキスト・メモリ・ツールという「体の各部」だ。だからオプス(運用)の対象は、LLM単体ではなくハーネス全体になる。LLMの挙動だけ眺めて「よし本番へ」とはいかない。
この性質から、エージェントは3つの前提を壊す。同じ入力でも出力が変わる(だから一度きりの文字列一致テストではなく、複数回テストする)。文脈に依存する(3ステップ上流のツールやMCP(外部ツール接続の標準規格)を差し替えると、振る舞いが変わる)。そして最大の難所——「良い」は主観的で、何が良いかは現場の専門家(SME)が定義するしかない。評価をエージェント運用の中心に据えなければならない理由が、ここにある。

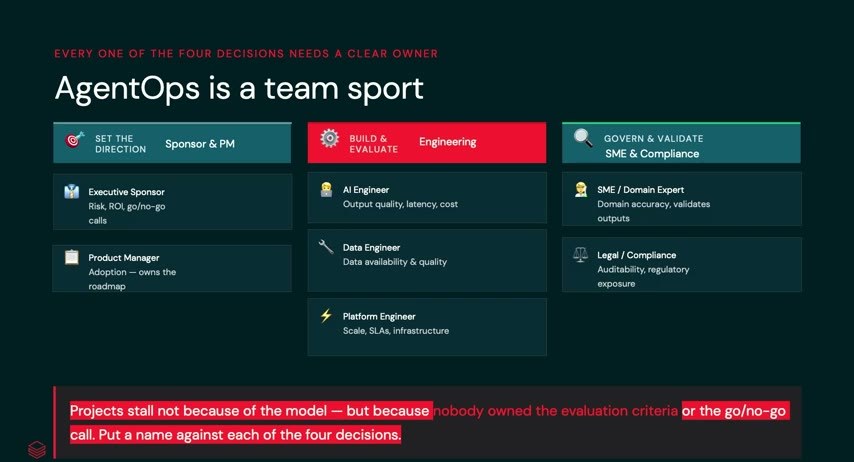
AgentOpsはチームスポーツ——コードを書く前に集まる人々
技術の前に、人がいる。Pavithra 氏は、複数のエンタープライズ顧客と作ったブループリントとして、本番リリースの部屋に必要な顔ぶれを挙げた。要件を握るプロダクトマネージャー、リスクとROI(投資対効果)を見るスポンサー(経営層)、もちろんエンジニア、そして規制業界(あるいは顧客データに触れる時点で)必須となるSMEとコンプライアンスチーム。責任は大きくスポンサー&PM/エンジニアリング/SME&コンプライアンスの3領域に分かれ、評価基準とgo/no-goの所有者を明確にしておく。
肝心なのは、コードを1行書く前に全員を揃え、合意を取ること。Air Canadaの一件は、技術ではなく「誰も応答を裏書きできなかった」という体制の問題でもあった。
まずマネージドから始める——アーキテクチャの“段”を選ぶ
ここから、4つの意思決定だ。最初はアーキテクチャの段(tier)を選ぶこと。
よくある失敗は、いきなり右端の「コードファースト」から始めてしまうこと。だが何を作るべきかが定まらないうちは、それは重い。Pavithra 氏の推奨は、まずマネージドからだ。Knowledge Assistant や Agent Bricks のような既製の部品で、低コスト・短時間に立ち上げる。UIでスーパーバイザーエージェントと小さなエージェントを組み合わせれば、すぐにテストを始められる。
ただし、これは一方通行の扉ではない。掛かるものが大きくなり、本当にカスタムが要るとなれば、LangGraph・トレース・ツール呼び出し・チェーンを自前で組むコードファーストへダイヤルを回せばよい。マネージドからコードファーストへ、段は連続している。

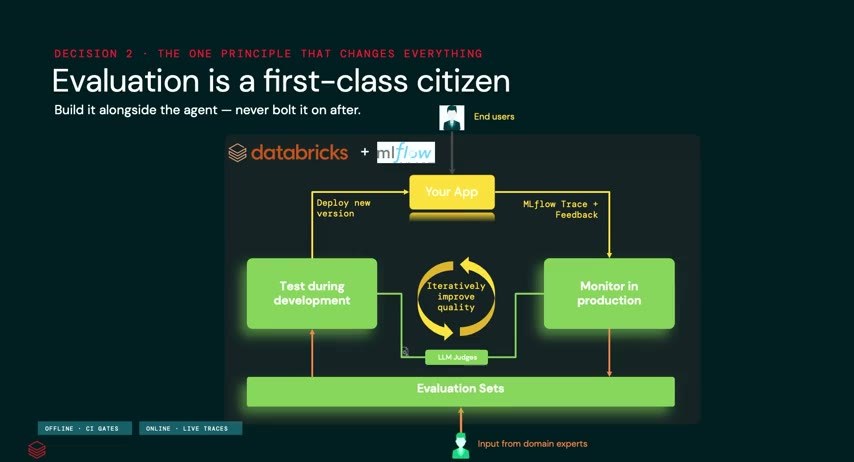
評価を“後付け”にしない——eval-gateという関所
そして、すべてを左右する決定——評価(eval)だ。Pavithra 氏が最も時間を割いたのがここだった。
MLflow のエージェントフレームワーク(オープンソース)、とりわけ MLflow 3.0+ は、開発ライフサイクル全体で評価を一級市民として扱う。評価は一度きりではなく、常時走る。MLflow のトレースとフィードバックを土台に、ジャッジ(採点者)が2種類働く。ひとつは LLMジャッジ——出力を自動で採点する、開発者が最低限すべき箱出しの仕組み。もうひとつは、本番に向けて入る SME(ドメイン専門家)ジャッジ——LLMジャッジの出力を、さらに人がレビューアプリで評価する。SMEの時間を初日から浪費せず、ベースラインを渡してから判断を仰ぐ設計だ。
本番では、入ってくる入力に対してLLMジャッジが常時走り、そのトレース出力が次の評価サイクルの入力になる。そして要となるのが eval-gate(評価の関所)。dev/staging/prod の間に統合テストの関所を置き、評価を通らないエージェントコードは、上位環境へ一切デプロイさせない。「評価は開発が終わってから付け足すものではなく、最初から一級市民として扱え」——これが本セッション最大の持ち帰りだ。
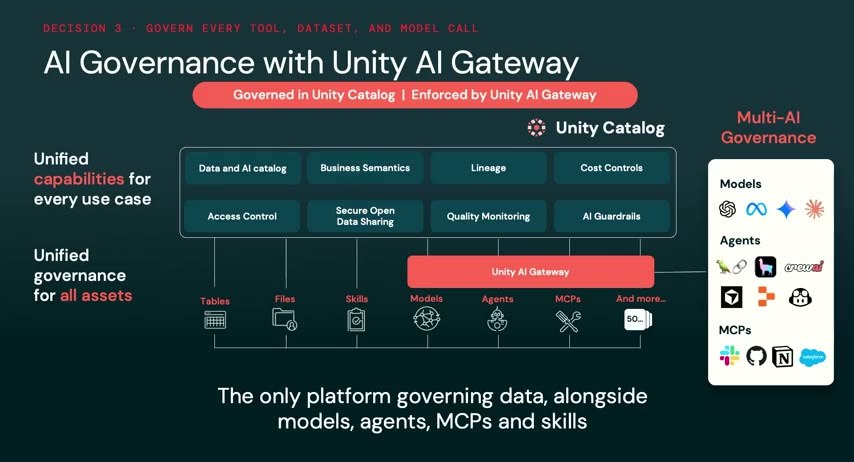
「なぜそう答えたか」を辿る——Unity AI Gatewayによるガバナンス
3つ目はガバナンスだ。Air Canada のチームは、エージェントがなぜあの応答をしたのかを辿れなかった。だがガバナンスのフレームワーク、とりわけ Unity Catalog があれば話は違った。ツール呼び出し、アクセスしたデータ、評価のされ方——すべてがトレースとして残り、出力を入力までさかのぼれる。
Databricks はここで Unity AI Gateway(ベータ)を打ち出した。ガバナンスの対象は、もはやモデルだけではない。エージェント・MCP・スキル・外部モデルプロバイダーまでがUnity Catalogの傘下に入る。データ&AIカタログ、ビジネスセマンティクス、リネージ、コスト制御、アクセス制御、セキュアなデータ共有、品質モニタリング、AIガードレール——これらの上にゲートウェイが座り、テーブル・ファイル・スキル・モデル・エージェント・MCPを横断して統制する。MLflowとも密に連携する。
エージェントを「コードのように」本番へ昇格させる
4つ目は昇格(promotion)だ。本番投入は、誰かが「今夜は誰もシステムを触らないから」と一気にやる作業ではない。基本のSDLC(ソフトウェア開発ライフサイクル)に従う。
そして肝は、エージェント単体ではなく“コード”を昇格させ、そのコードからエージェントをデプロイすること。Declarative Automation Bundles(DABs)の宣言的なバンドルで、DEV→STAGING→PROD を eval-gate でつなぐ。下位環境で加えた変更は本番に触れず、評価を経て初めて上がる。複数ワークスペース・複数アカウント・複数カタログといった現実的な構成にも、この型は効く。

ループが回り出す——DatabricksのAgentOps
4つの意思決定——ビルド/評価/ガバナンス/昇格——は、ばらばらの作業ではなく、ひとつのループになる。新しいユースケースから、動くプロトタイプを作り(ビルド)、人間のテスターとSMEで試し、品質問題と再現手順を洗い出し(評価)、コードを直してテストし、ステークホルダーの承認を得て(ガバナンス)、本番へリリースして監視する(昇格)。本番のライブ監視は、そのまま下位環境の評価へフィードバックされる。
つまり AgentOps は、DevOps(開発と運用を統合する手法)の原則——フロー、フィードバック、継続的学習——をエージェント向けに作り直したものだ。一度セットアップすれば、ループは回り続ける。

押さえどころ
20分に凝縮された主張は、最後の一枚に集約されていた。本番で信頼できるエージェントは、より大きなモデルからは生まれない。規律から生まれる。
- まずマネージドで素早く立ち上げ、必要に応じてコードファーストへ。段は連続していて、後から回せる。
- 評価を一級市民にする。LLMジャッジで自動化し、SMEで仕上げ、eval-gateを通らないコードは上位環境へ出さない。
- Unity Catalog/Unity AI Gatewayで、モデルもエージェントもMCPもスキルも統制し、応答を入力まで辿れるようにする。
- エージェントはコードのように昇格させる(DABsでDEV→STAGING→PROD)。
- 全体は フロー・フィードバック・継続的学習 のループ。一度組めば回り続ける。
なお登壇者はこの内容をまとめた書籍 「Big Book of Agent Ops」 の共著者で、同書はサミット後、8月ごろの公開を予定しているという。デモで光るエージェントではなく、本番で背負えるエージェントへ。その差は、スキップしない規律にある。








