はじめに
時系列データには、普通のテーブルにはない「順序」という情報があります。この順序をうまく使うと、予測モデルの精度アップに役立つ特徴量を作ることができます。
時系列データとは何か?
時系列データとは、日時などの時間の情報がついたテーブルのことです。1つ1つのレコードが、ある時点と結びついています。
時間の単位はデータによって異なり、日単位のこともあれば分単位のこともあります。レコードの間隔も様々で、毎日きれいに並んでいる等間隔のものもあれば、日付が飛んでいるものもあります。たとえばクレジットカードの利用履歴を考えてみます。利用した日ごとに、お店の名前と金額が記録されているとします。この場合、時間の単位は「日」で、使った日にしか記録が残らないので、間隔は飛び飛びになります。
時間の情報が直接なくても、順番に意味がある項目があれば時系列データとして扱えます。たとえば、ある店舗の来店履歴に「累積来店回数」が入っているとします。この1回目・2回目…という数字は来店した順番そのものなので、時系列データと考えられます。
さらに、順番を表す項目すらなくても、レコードの並び自体に順番の意味があれば時系列データです。たとえば、買い物のたびに下へ1行ずつ追加されていくテーブルがそうです。「ぱっと見では分からないけど、よく見ると時系列データだった」ということもあるので、注意して見てみてください。
時系列データでは、このレコードの順番を活かして、次の3つの特徴量を作れます。
- ラグ特徴量
- ウィンドウ特徴量
- 累積特徴量
ここから順番に説明していきます。
ラグ特徴量
ラグ特徴量は、ある列の値を1つ前の時点へずらして作る特徴量です。「1つ前」だけでなく、2つ前や3つ前へずらすこともできますし、逆に後ろ(未来側)へずらすこともできます。数値の列なら、ずらした値と元の値の差を取って「差分」を特徴量にすることもできます。
サンプルデータを作って見ていきます。
例1:1行ずらす
日単位の天気データで考えます。やることはシンプルで、「天気」の列を1日分ずらすだけです。これで「前日の天気」という特徴量ができます。
ずらすときに気をつけたいことが2つあります。
1つ目は、欠損が出ることです。1日ずらすと先頭の1行が空になります。2日ずらせば1行目と2行目が空きます。空いたままにするか、何かで埋めるかは、その都度決めてください。
2つ目は、データが上から時間順に並んでいる前提で処理される点です。並び順がバラバラだと正しくずれないので、先に並べ替えておく必要があります。並んでいないときは df = df.sort_values("date") のようにソートしてください。
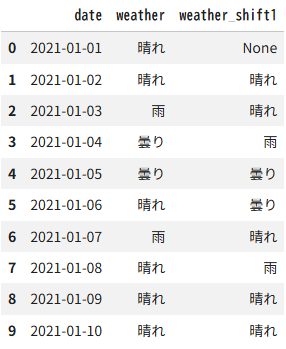
df1 = pd.DataFrame({"date":pd.date_range("2021-01-01","2021-01-10"),
"weather":["晴れ","晴れ","雨","曇り","曇り","晴れ","雨",
"晴れ","晴れ","晴れ"],})
df1["weather_shift1"] = df1["weather"].shift(1)
df1出力結果
例2:IDごとに1行ずらす
会員IDごとに、購入日と購入金額が入ったテーブルを考えます。会員IDごとに1行ずらして、「前回いくら使ったか(前回購入金額)」という特徴量を作ります。今回は会員IDごとにずらすので、各IDの先頭1行が欠損します。
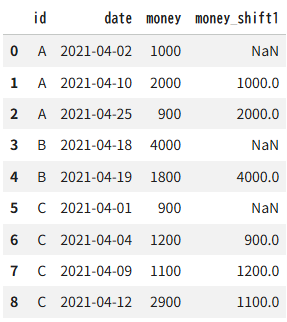
df2 = pd.DataFrame({"id":["A"]*3 + ["B"]*2 + ["C"]*4,
"date":["2021-04-02","2021-04-10","2021-04-25",
"2021-04-18","2021-04-19",
"2021-04-01","2021-04-04","2021-04-09",
"2021-04-12",],
"money":[1000,2000,900,4000,1800,900,1200,1100,2900],})
df2["date"] = pd.to_datetime(df2["date"], format="%Y-%m-%d")
df2["money_shift1"] = df2.groupby("id")["money"].shift(1)
df2出力結果
ウィンドウ特徴量
ウィンドウ特徴量は、ざっくり言うと「移動平均」のことです。ただ、計算するのは平均だけとは限りません。標準偏差や最大値、最小値を使うこともあります。この記事では、それらをまとめてウィンドウ特徴量と呼んでいます。
「ウィンドウ」は、その行自身を含めて何個分のデータを使うかを表します。幅を3にすると、自分の行・1つ前・2つ前の合わせて3個分が計算の対象になります。つまりウィンドウ幅3の移動平均なら、この3個の値の平均が特徴量になります。具体的な作り方を例で見ていきます。
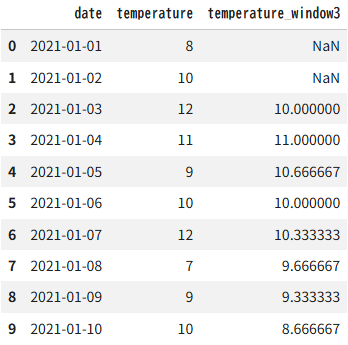
例1:ウィンドウ幅3日
df3 = pd.DataFrame({"date":pd.date_range("2021-01-01","2021-01-10"),
"temperature":[8,10,12,11,9,10,12,7,9,10],})
df3["temperature_window3"] = df3["temperature"].rolling(window=3).mean()
df3出力結果
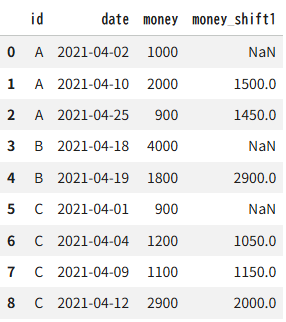
例2:IDごとのウィンドウ
ラグ特徴量の例2と同じテーブルを使います。ここでは会員IDごとにウィンドウ幅を2にして、直近2回の購入金額の平均を特徴量にします。
df4 = pd.DataFrame({"id":["A"]*3 + ["B"]*2 + ["C"]*4,
"date":["2021-04-02","2021-04-10","2021-04-25",
"2021-04-18","2021-04-19",
"2021-04-01","2021-04-04","2021-04-09",
"2021-04-12",],
"money":[1000,2000,900,4000,1800,900,1200,1100,2900],})
df4["date"] = pd.to_datetime(df4["date"], format="%Y-%m-%d")
df4["money_shift1"] = df4.groupby("id")["money"].transform(lambda x: x.rolling(window=2).mean())
df4出力結果
累積特徴量
累積特徴量は、過去の値を足し合わせていった数値を特徴量にしたものです。
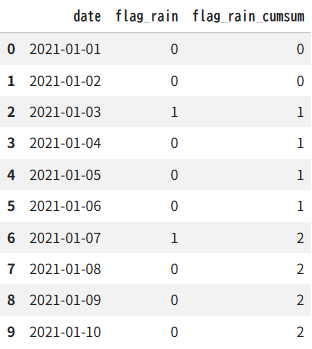
例1:累積の合計
雨が降った日に「1」を立てた、日単位のテーブルで考えます。「これまでに何日雨が降ったか」を特徴量にしたいときは、雨フラグの数字を順番に足していきます。この足し合わせは cumsum で計算できます。
df5 = pd.DataFrame({"date":pd.date_range("2021-01-01","2021-01-10"),
"flag_rain":[0,0,1,0,0,0,1,0,0,0],})
df5["flag_rain_cumsum"] = df5["flag_rain"].cumsum()
df5出力結果
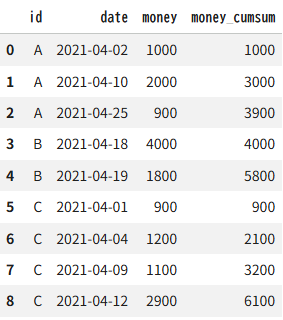
例2:IDごとの累積
会員IDごとに、購入金額を順番に足し合わせていきます。IDごとに cumsum を使いたいので、groupby と組み合わせます
df6 = pd.DataFrame({"id":["A"]*3 + ["B"]*2 + ["C"]*4,
"date":["2021-04-02","2021-04-10","2021-04-25",
"2021-04-18","2021-04-19",
"2021-04-01","2021-04-04","2021-04-09",
"2021-04-12",],
"money":[1000,2000,900,4000,1800,900,1200,1100,2900],})
df6["date"] = pd.to_datetime(df6["date"], format="%Y-%m-%d")
df6["money_cumsum"] = df6.groupby("id")["money"].cumsum()
df6出力結果
まとめ
この記事では、時系列データの特徴量エンジニアリングの基本として、ラグ特徴量・ウィンドウ特徴量・累積特徴量の3つを紹介しました。
これらの特徴量は予測精度を上げてくれることが多いですが、いつでも効くとは限りません。場合によっては、逆に精度を下げてしまうこともあります。大事なのは「なぜこの特徴量が予測に効きそうなのか」を自分の言葉で説明できるかどうかです。
実際のデータでは、ここで紹介した形をそのまま使うだけでなく、少し変えてみたり、組み合わせてみたり、効かなそうなものは思い切って外したりしながら、試していくことになります。予測したい対象とにらめっこしながら、自分なりの特徴量を見つけてみてください。
参考:Kaggleで磨く機械学習の実践力 諸橋政幸