
1. 世界モデルとは
概要
世界モデル(World Model)とは、外界から得られる観測データをもとに、環境がどのように動くかを学習によって獲得するモデルです。
人間が「ボールを投げたら放物線を描く」「火に触れると熱くなる」という法則を経験から学ぶように、エージェントも観測データから「環境がどう動くか」を内部に取り込みます。この内部モデルを使うことで、実際に試すことなく「この行動をしたら次はどうなるか」を予測・シミュレーションできるようになります。
通常の強化学習との違い
通常の強化学習は、環境をブラックボックスとして扱い、実際に行動した結果(報酬)だけをもとに「どう行動すべきか」を直接学習します。
一方、世界モデルは環境の動き方そのものを学習します。すなわち、環境の動きをまず学習し、学習された環境の動きからシミュレーションなどを通じて、強化学習などへ応用していきます。
エージェントの行動を直接学習するのが通常の強化学習なのに対して、環境の動きを学習するのが世界モデルです。
| 通常の強化学習 | 世界モデル | |
|---|---|---|
| 環境の扱い | ブラックボックス | 動き方を学習する |
| 学習対象 | 行動そのもの | 環境の変化のパターン |
| 活用方法 | 試行錯誤で改善 | シミュレーションで計画・学習 |
今回実装する内容
本記事では、世界モデルのコアである「環境の再現」にしぼったシンプルな実装を行います。
CartPoleという棒を倒さないようにカートを動かすシンプルなゲームを環境として使用します。この環境は本来、物理エンジンが「状態 × 行動 → 次の状態」を計算しています。今回はこの物理エンジンをニューラルネットワークで模倣することを目指します。
実装は以下の4ステップで進めます。
- データ収集: CartPoleでランダムに行動し、
状態・行動・次の状態のデータを集める - 世界モデルの学習:
状態 × 行動 → 次の状態を予測するニューラルネットワークを学習する(=CartPoleの物理エンジンを模倣する) - シミュレーション: 学習した世界モデル上でランダムな行動を与え続け、実環境を一切使わずに軌跡を生成する
- 可視化: 生成した軌跡をグラフで可視化し、世界モデルが環境をどれだけ再現できているかを確認する
2. 準備
動作環境
| バージョン | |
|---|---|
| Python | 3.10以上 |
| torch | 2.0.0以上 |
| gymnasium | 1.0.0以上 |
| numpy | 1.24.0以上 |
| matplotlib | 3.7.0以上 |
| japanize-matplotlib | 最新版 |
ライブラリのインストール
以下のコマンドで必要なライブラリをインストールします。
pip install -r requirements.txt
pip install japanize-matplotlib
requirements.txt の内容は以下の通りです。
torch>=2.0.0
gymnasium>=1.0.0
numpy>=1.24.0
matplotlib>=3.7.0
ディレクトリ構成
world_model/
├── requirements.txt # 必要なライブラリ
├── world_model.py # 世界モデルの定義・学習・シミュレーション
└── main.py # 実行スクリプト(データ収集〜可視化まで)
📌 本記事のコードは以下のリポジトリで公開しています。
使用環境:CartPole-v1
今回使用する CartPole-v1 は、OpenAI Gym(gymnasium)が提供するシンプルな制御タスクです。
カートの上に立てた棒が倒れないようにカートを左右に動かすという問題で、状態と行動は以下のように定義されています。
CartPoleの様子は以下の通りです。
参考:https://qiita.com/k8o/items/c8b92640b36b2ef21dbf
状態(4次元)
| 変数 | 説明 |
|---|---|
| カートの位置 | カートのx座標 |
| カートの速度 | カートの移動速度 |
| 棒の角度 | 棒が垂直からどれだけ傾いているか |
| 棒の角速度 | 棒の傾きの変化速度 |
行動(2値)
| 値 | 説明 |
|---|---|
| 0 | カートを左に動かす |
| 1 | カートを右に動かす |
世界モデルはこの 状態 × 行動 → 次の状態 という変化のパターンを学習します。
学習データと予測対象
CartPoleでランダムに行動すると、1ステップごとに以下の1セットが得られます。
(状態, 行動, 次の状態)
例:
状態 = [0.02, 0.01, -0.03, 0.04] # 現在のカートの位置・速度・棒の角度・角速度
行動 = 1 # 右に動かす
次の状態 = [0.02, 0.21, -0.03, -0.27] # 行動後のカートの位置・速度・棒の角度・角速度
これを200エピソード分(約4800セット)集めたものが学習データです。
世界モデルはこのデータを使って、状態 × 行動 を入力として 次の状態 を予測するように学習します。予測と実際の次の状態のズレ(MSE)が小さくなるようにパラメータを更新していきます。正解ラベルは人間が用意するのではなく、環境が自動的に提供してくれます。
3. 実装
実装は world_model.py(世界モデルの定義・学習・シミュレーション)と main.py(実行スクリプト)の2ファイルで構成されています。
world_model.py
世界モデルの定義(WorldModelクラス)
状態(4次元) × 行動(1次元) を入力として 次の状態(4次元) を予測する3層のニューラルネットワークです。
class WorldModel(nn.Module):
def __init__(self, state_dim=4, action_dim=1, hidden_dim=64):
super().__init__()
self.net = nn.Sequential(
nn.Linear(state_dim + action_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, state_dim),
)
def forward(self, state, action):
action = action.float().unsqueeze(-1) if action.dim() == 1 else action.float()
x = torch.cat([state, action], dim=-1)
return self.net(x)
入力層では状態(4次元)と行動(1次元)を結合して5次元のベクトルとし、隠れ層2層を経て次の状態(4次元)を出力します。
データ収集(collect_data関数)
CartPoleでランダムに行動し、(状態, 行動, 次の状態) のセットを収集します。
def collect_data(env, num_episodes=200):
states, actions, next_states = [], [], []
for _ in range(num_episodes):
state, _ = env.reset()
done = False
while not done:
action = env.action_space.sample()
next_state, _, terminated, truncated, _ = env.step(action)
done = terminated or truncated
states.append(state)
actions.append(action)
next_states.append(next_state)
state = next_state
return (
torch.tensor(states, dtype=torch.float32),
torch.tensor(actions, dtype=torch.float32),
torch.tensor(next_states, dtype=torch.float32),
)
env.action_space.sample() でランダムに行動を選び、env.step() で実際に環境を1ステップ進めます。200エピソード分繰り返すことで約4800セットのデータを集めます。
世界モデルの学習(train関数)
収集したデータを使って世界モデルを学習します。損失関数には予測と実際の次の状態のズレを表すMSEを使用します。
def train(model, states, actions, next_states, epochs=100, batch_size=256, lr=1e-3):
optimizer = optim.Adam(model.parameters(), lr=lr)
criterion = nn.MSELoss()
dataset = TensorDataset(states, actions, next_states)
loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
loss_history = []
for epoch in range(epochs):
total_loss = 0.0
for s, a, ns in loader:
pred = model(s, a)
loss = criterion(pred, ns)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(loader)
loss_history.append(avg_loss)
return loss_history
シミュレーション(simulate関数)
学習した世界モデルだけを使って軌跡を生成します。実環境には一切触れません。
def simulate(model, initial_state, num_steps=200):
model.eval()
trajectory = [initial_state]
state = torch.tensor(initial_state, dtype=torch.float32).unsqueeze(0)
with torch.no_grad():
for _ in range(num_steps):
action = torch.randint(0, 2, (1,)).float()
next_state = model(state, action)
trajectory.append(next_state.squeeze(0).numpy())
state = next_state
return trajectory
初期状態を与えると、ランダムな行動を200ステップ与え続けながら世界モデルが次の状態を予測し続けます。この予測の連鎖が「シミュレーション上の軌跡」になります。
main.py
4つのステップを順番に実行するスクリプトです。
def main():
# Step 1: データ収集
env = gym.make("CartPole-v1")
states, actions, next_states = collect_data(env, num_episodes=200)
# Step 2: 世界モデルの学習
model = WorldModel(state_dim=4, action_dim=1, hidden_dim=64)
loss_history = train(model, states, actions, next_states, epochs=100)
# Step 3: シミュレーション
initial_state, _ = env.reset(seed=42)
trajectory = simulate(model, initial_state, num_steps=200)
trajectory = np.array(trajectory)
# Step 4: 可視化(グラフをsimulation_result.pngに保存)
...
実行方法
python3 main.py
4. 結果
このシミュレーションで何をしているか
「同じ初期状態・同じ行動列」を世界モデルと実環境の両方に与えて、軌跡がどれだけ一致するかを確認しています。
同じ初期状態
同じ行動列
↓ ↓
世界モデル 実環境(本物)
で予測し続ける で実際に動かす
↓ ↓
軌跡A 軌跡B
↓
軌跡Aと軌跡Bが近ければ世界モデルの精度が高い
期待する動きとしては、ランダムな行動を与え続けると棒が傾いてゲームオーバーになります。世界モデルがCartPoleの物理を正しく学習できていれば、実環境とほぼ同じタイミング・同じ角度で棒が傾いていくはずです。
なお今回はより長い区間で比較できるよう、100個のランダムな行動列を試した中で最も長く続いたもの(70ステップ)を採用しています。
実行結果
Step 1: データ収集
収集データ数: 4660 サンプル
Step 2: 世界モデルの学習
Epoch 10 / 100 Loss: 0.000761
Epoch 20 / 100 Loss: 0.000236
...
Epoch 100 / 100 Loss: 0.000016
Step 3: 最長の行動列を探索
最長の行動列: 70 ステップ(100試行中)
Step 4: 世界モデルでシミュレーション
世界モデルのシミュレーション: 70 ステップ
アニメーションによる比較
実環境と世界モデルのシミュレーションをアニメーション(GIF)で視覚的に確認できます。左側が実環境の本物のレンダリング、右側が世界モデルが予測した状態を元に描画したシミュレーションです。同じ行動列を与えたときにカートの位置や棒の傾き方が連動している様子が確認できます。

また、以下のグラフが simulation_result.png として出力されます。
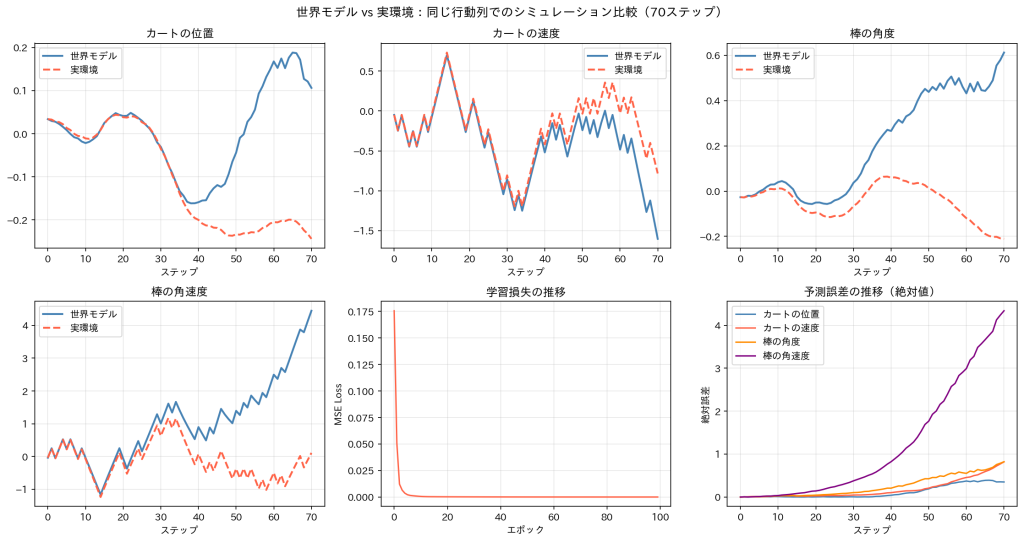
グラフの見方と考察
学習損失の推移(下段中)
学習開始直後から損失が急激に下がり、約20エポック以降はほぼ0に収束しています。世界モデルが次の状態の予測を正確に学習できたことを示しています。
カートの位置・速度・棒の角度(上段左・中・右)
序盤は世界モデル(青)と実環境(赤点線)がほぼ重なっており、高い精度で環境を再現できています。中盤以降になるとズレが広がっていきますが、棒が傾いていく大きな傾向は実環境と近い挙動を示しています。
棒の角速度(下段左)
4つの状態変数の中で最もズレが大きいのが棒の角速度です。序盤は一致していますが、後半にかけて世界モデルと実環境の乖離が大きくなっています。
予測誤差の推移(下段右)
序盤はほぼ0に近い誤差ですが、ステップが進むにつれて徐々に増加しています。特に棒の角速度の誤差が最も大きく、短期予測は高精度・長期になるほど誤差が蓄積するという世界モデルの典型的な特性が確認できます。
5. まとめ
本記事では、世界モデルの概念をシンプルな実装を通じて確認しました。
世界モデルとは、環境をブラックボックスとして扱う通常の強化学習とは異なり、「環境がどう動くか」そのものをデータから学習する枠組みです。今回は 状態 × 行動 → 次の状態 を予測するニューラルネットワークをCartPoleで学習し、実環境を使わずにシミュレーションできることを確認しました。
結果として、序盤は実環境とほぼ一致する高精度な予測ができる一方、ステップが進むにつれて誤差が蓄積していくという世界モデルの典型的な特性も観察できました。
環境を構築することで、実データの取得が難しい場面において、シミュレーションを行い、新たな強化学習への応用を行うことができます。










