最新モデルを導入した。なのに、社内のことを尋ねると、的外れな答えが返ってくる。心当たりのある経営者は少なくないはずです。
来場3万人を超えたData + AI Summit 2026。その基調講演で繰り返し語られたのは、「AIはもう十分賢い。足りないのは賢さじゃなくて、社内の文脈だ」という一言でした。
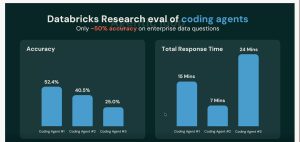
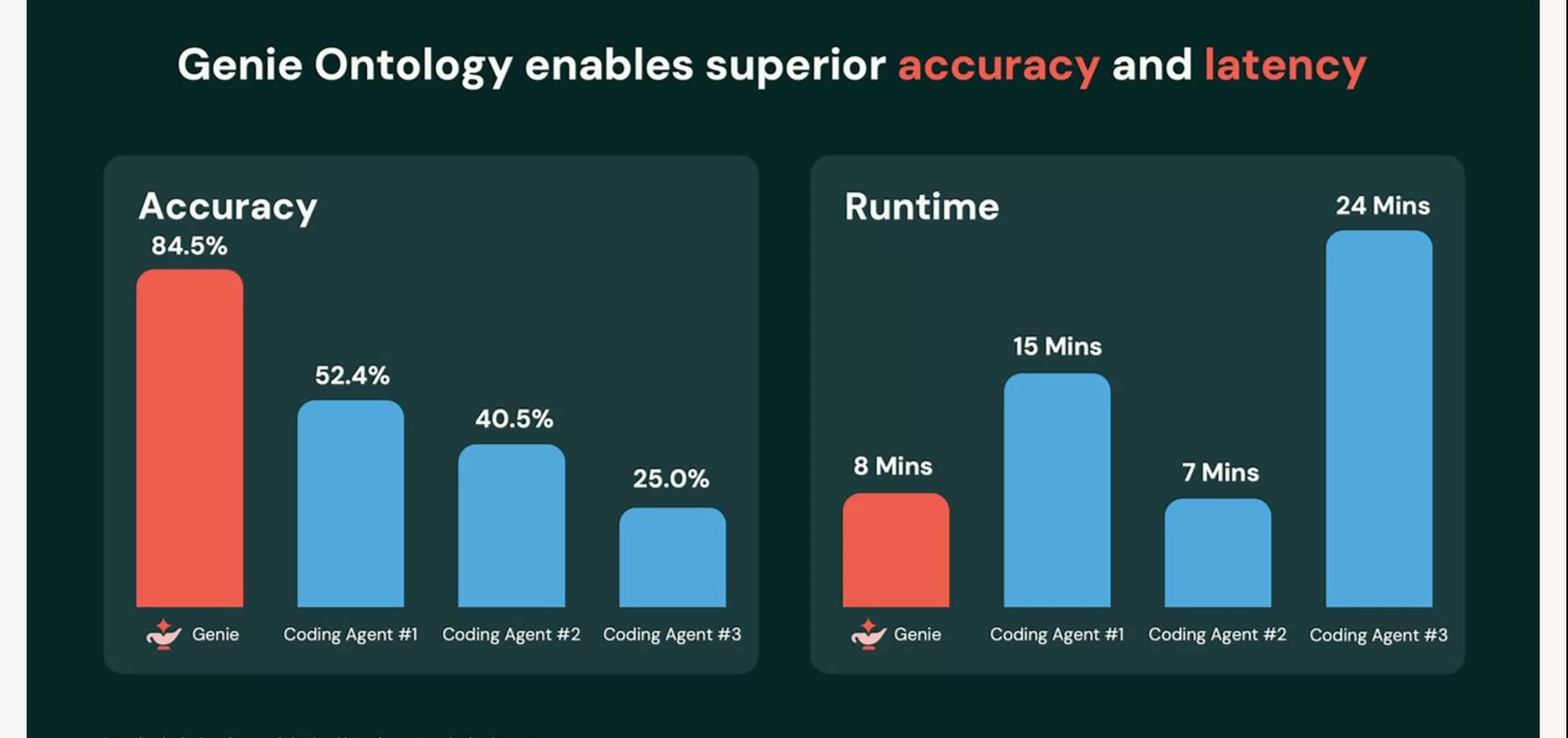
では、社内データについての質問に、AIエージェントはどこまで正しく答えられるのか。基調講演で示された評価では、3つのコーディングエージェントの正答率は、最も良くて52.4%。残りは40.5%、25.0%。コインを投げるのと大差ない、と言われても仕方のない数字です。しかも答えを出すまでに10〜15分かかり、その間ずっとトークン(AIが文章を処理する際の単位で、使うほど料金がかさむ)を食い続ける。
なぜこうなるか。エージェントが「社内の地図」を持っていないからです。質問のたびに、どこにどんなデータがあるかをその場で探し回る。これでは遅いし、外れる。
ならば、発想を逆にする。探させるのをやめて、先に地図を渡してしまえばいい。その地図がGenie Ontologyです。
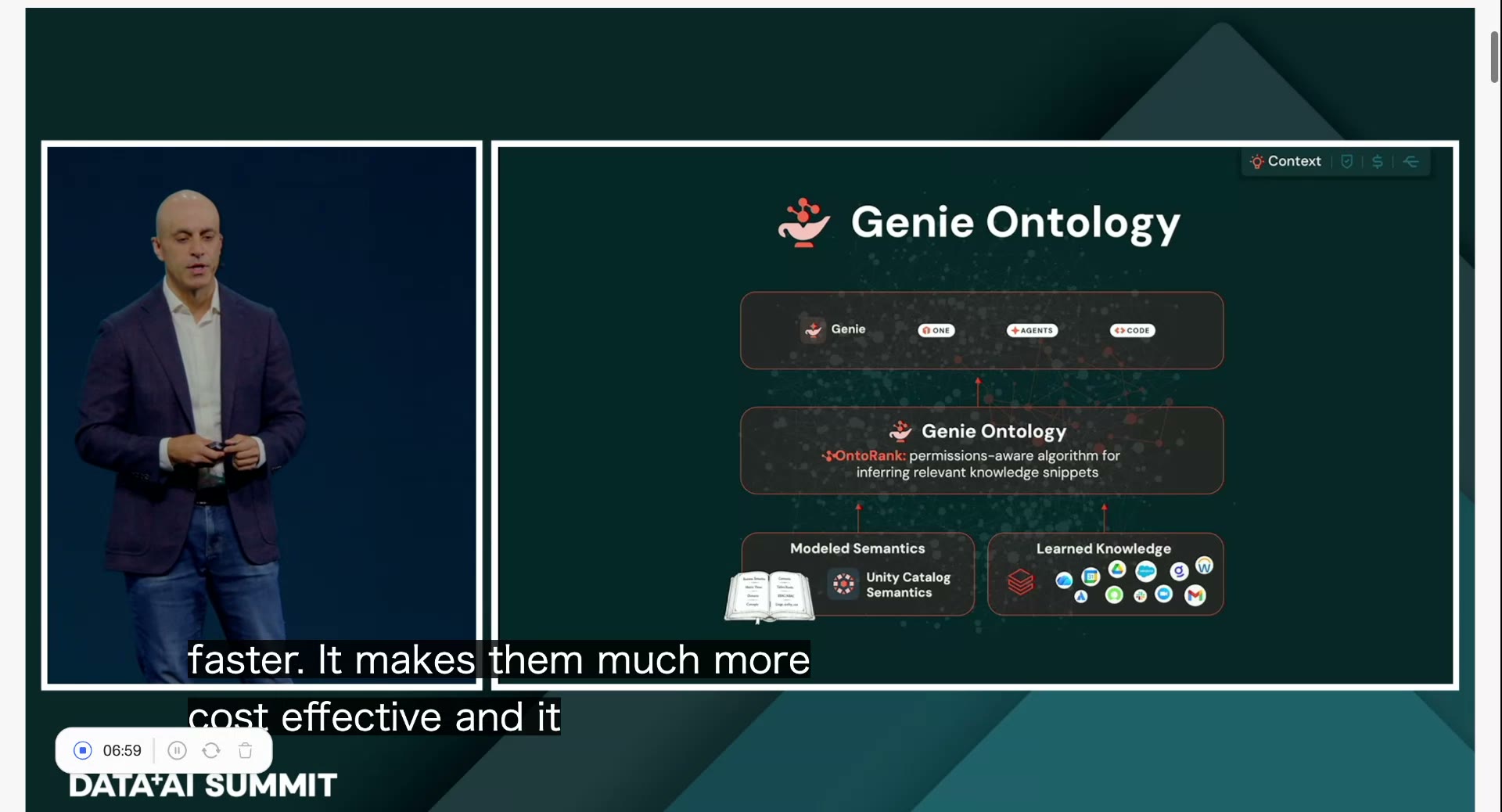
そもそもオントロジーとは何か
オントロジーという言葉、聞き慣れない方が多いはずです。ざっくり言えば「意味の地図」。ある領域の概念・用語・ルールと、それらの関係を、AIが読める形に整理したものです。
たとえば、あなたの会社で「優良顧客」と言ったとき、それは何を指しますか。年間の取引額が一定以上の相手か、継続年数が長い相手か、それとも利益率で測るのか。あるいは「解約」を数えるとき、どの時点をもって解約とみなすのか。月末か、契約終了日か、最後の利用日か。
こうした取り決めは、社内の人間にとっては当たり前すぎて、わざわざ口にしません。けれどAIはそれを知りません。「優良顧客の数を出して」と頼んでも、何をもって優良とするかが定義されていなければ、見当違いの数字を返してくる。
オントロジーは、この暗黙の常識を書き出して、AIに渡せる形にする作業です。これがあると、AIは言葉の表面ではなく「意味」で動けるようになる。
Genie Ontologyの仕組み——社内に散らばる断片を集める
Genie Ontologyがやっているのは、社内のデータ資産と、「その領域に詳しい人(エキスパート)」を結ぶ知識グラフを、バックグラウンドで継続的に作り続けることです。一度作って終わり、ではない。裏で動き続けて、地図を更新していく。
材料はどこから集めるか。Databricksは3つの経路を挙げました。
一つ目は、ワークスペースの資産。社内に置かれたノートブック、ダッシュボード、パイプラインなどです。
二つ目は、パートナー連携。SharePointのような社外ツールに置かれた情報も取り込めます。
三つ目は、Unity Catalog。Databricksがデータやモデルを一元管理する仕組みで、ここに蓄えられた来歴(リネージ=そのデータがどこから来てどう加工されたかの履歴)や用語の定義を使います。
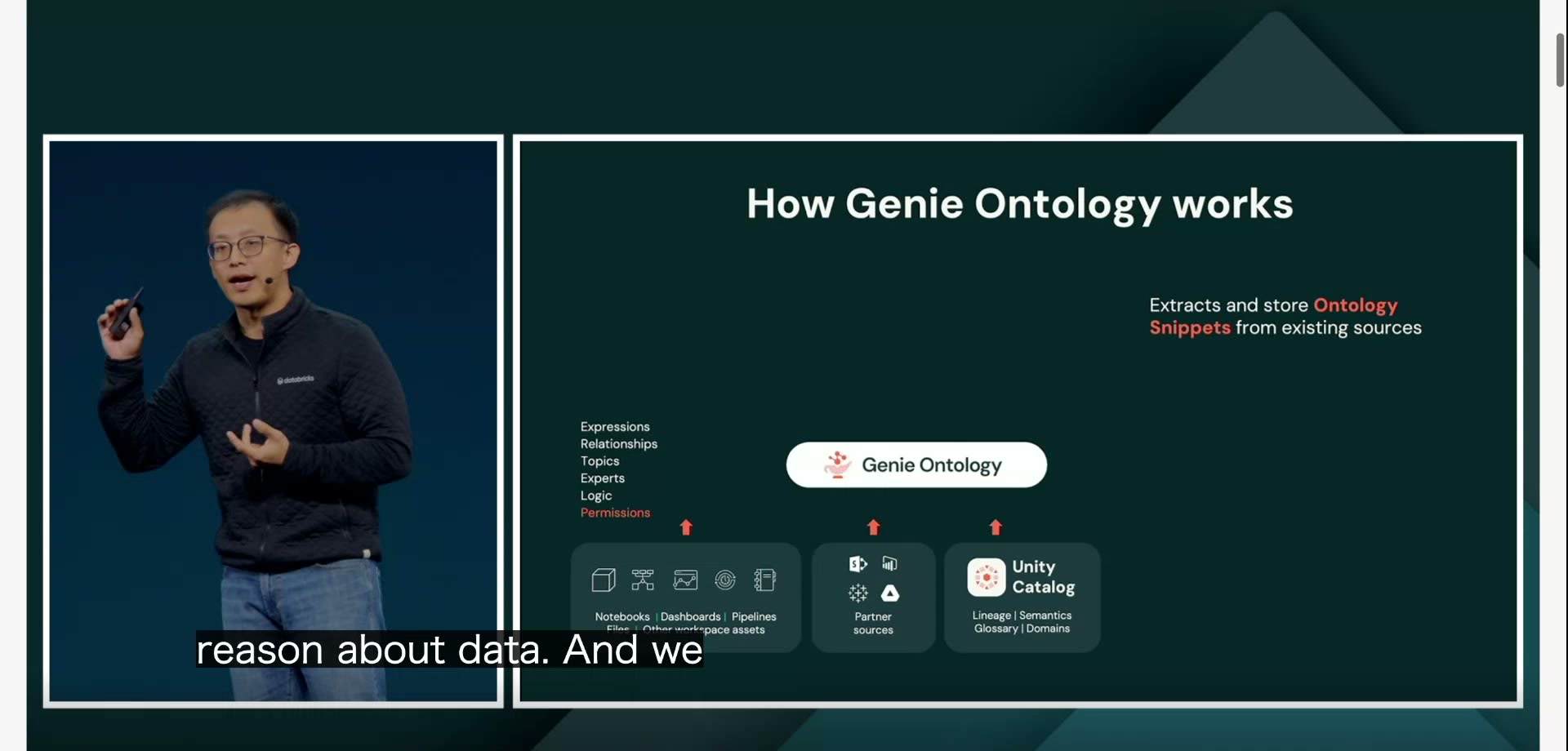
これら3経路から、Databricksは「オントロジー断片(Ontology Snippets)」と呼ぶ細かい意味の単位を抜き出していきます。式(計算ロジック)、用語どうしの関係、トピック、誰が詳しいか、そしてアクセス権限まで。バラバラに散らばっていた社内の知識を、ひとつの地図に編み込んでいくわけです。
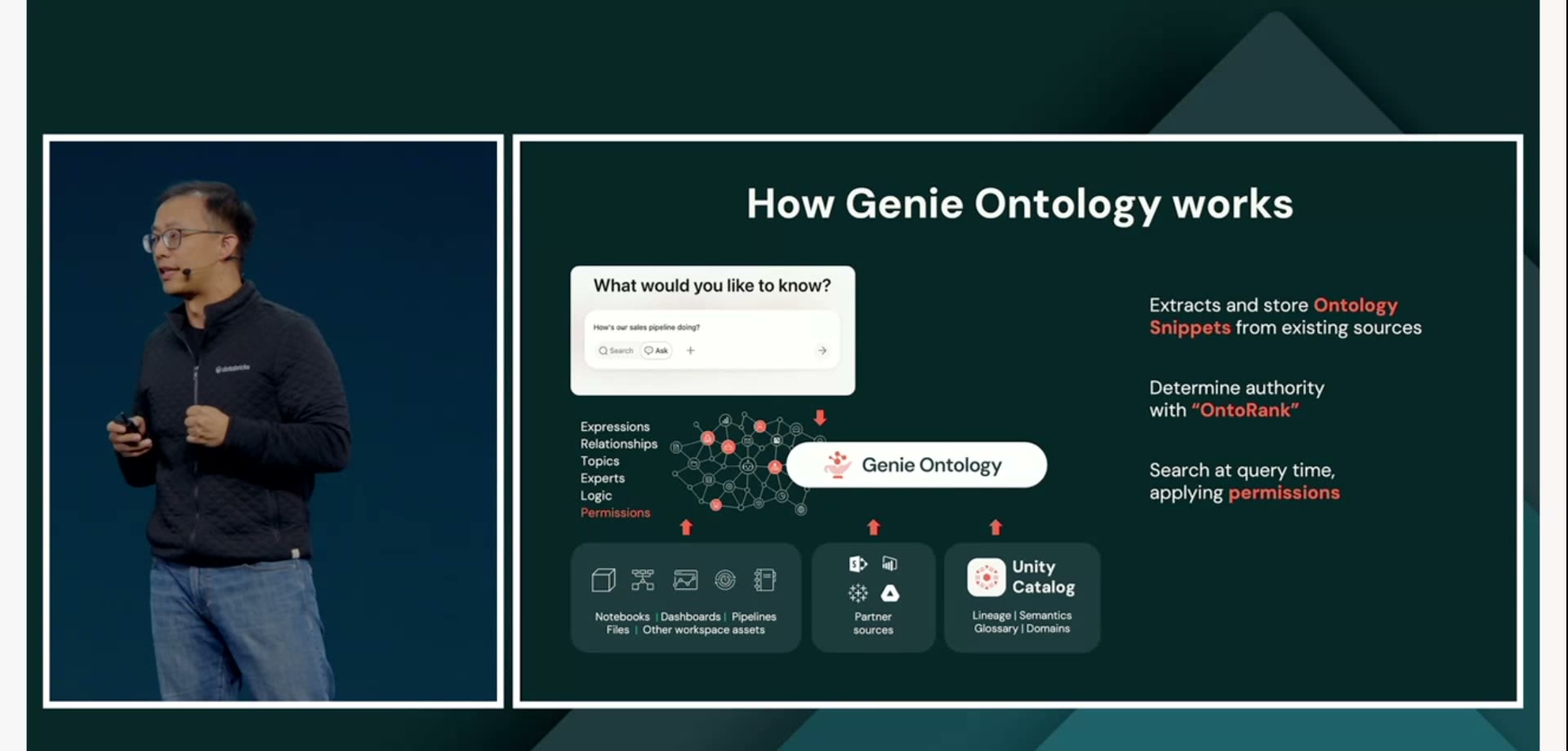
重要度を測る「OntoRank」
ここで問題になるのが、集めた断片の「信頼度」です。社内には古い定義も、間違った資料も、誰も使っていないテーブルも残っています。全部を同じ重みで扱えば、地図はかえって役に立たない。
そこでDatabricksが用意したのがOntoRankという仕組みです。WebのPageRank——Googleが「どのページが信頼できるか」をリンクの張られ方から判断した、あの考え方——の、企業データ版にあたる発想だと説明されました。どの情報が信頼できるか、どの定義が広く参照されているかを見て、重み付けをする。
実際の画面では、その規模が示されました。45万を超える断片(450,185)、2,305の資産、63のドメイン(業務領域)、733人のエキスパート。これだけの知識が、ひとつの地図の上に整理されている。

数字を見せる、というのは単なる自慢ではありません。「これだけの社内知識が構造化された」という事実が、次の精度の話につながってきます。
なぜ効くのか——速くて、外れにくくて、漏れない
地図を先に持っていると、何が変わるか。
まず速い。質問のたびに探し回る必要がない。ライブ検索(その場で逐次データを探す方式)の10〜15分に対し、事前に地図があれば、必要な場所へまっすぐ向かえます。
そして外れにくい。意味の定義が地図に書いてあるので、「優良顧客」が何を指すかを毎回手探りしなくていい。
同じ評価で並べると、効き目がはっきりする。社内データの質問に対し、Genie(Genie One)の正答率は、実データ28問の社内ベンチで84.5%。先ほどのコーディングエージェント3種(52.4% / 40.5% / 25.0%)を大きく引き離しました。しかも所要時間は8分。最良だったエージェント(#1)の15分に対して約2倍の速さです。
もうひとつ大事なのが「漏れない」こと。権限はUnity Catalogで踏まえます。つまり、その人が見てよいデータの範囲を、検索の時点できちんと適用する。地図があるからといって、誰でも何でも見られるわけではない。見えてはいけない情報は、答えにも出てこない。
そしてこの地図は、いまある資産の上に重ねられます。すでに社内でビジネス用語集を整備しているなら、それを土台にできる。ゼロから作り直す話ではありません。
押さえどころ
基調講演を追っていると、新しいモデルや派手な機能に目が行きがちです。けれどGenie Ontologyが突きつけているのは、もっと地味で、もっと本質的な問いです。
「AIに渡すべき自社の知識を、ちゃんと書き出せているか」
賢いモデルを選ぶことよりも、社内に散らばった暗黙の常識——優良顧客とは何か、解約をどう数えるか、どの数字が信頼できるか——を構造化して、AIが読める形にすること。Databricksが45万の断片やOntoRankという仕組みで見せたのは、まさにこの「地図づくり」を会社の中でどう回すか、という話でした。
モデルは1ヶ月で入れ替わります。けれど、いちど整えた社内知識の地図は、新しいモデルが来ても使い続けられる。どちらに投資すべきか。答えは出ている。
関連:生成AIに「自社の文脈」を渡すサービス「Ontology Boost」
Genie Ontologyが示した「社内の知識を地図にしてAIに渡す」という発想——
これは、私たちSiNCEが提供を開始したサービス 「Ontology Boost」 がまさに取り組む領域です。生成AI(ChatGPT・Claude・Geminiなど)が、御社固有の用語・KPI・業務ルールに沿って”根拠のある”回答を返せるよう、知識基盤(オントロジー)の構築・接続・運用までを一貫支援します。