Databricksのカンファレンスで行われた、同社のマーケティングアナリティクスチーム自身が登壇したセッション「From Dashboards to Decisioning: How We Rebuilt Marketing」を聴いてきました。100枚規模のTableauダッシュボードを抱えながら「基本的な問いにすら答えられない」状態から、レイクハウスとAIエージェントを軸にデータ基盤を作り直し、レポート作成を1週間から30分に縮めるまでの道のりが、課題と打ち手のペアで率直に語られた内容です。
ダッシュボードを増やすのではなく、意思決定そのものを速くする——タイトルの「Dashboards to Decisioning」がそのまま設計思想になっていました。マーケティング部門に限らず、データ活用の現場で起きがちなつまずきと、その乗り越え方として参考になる点が多かったので、要点をまとめます。
「100枚のダッシュボード」では、基本的な問いに答えられなかった
スタート地点は、よくある「成長したがゆえの混乱」でした。30以上のテーブルをジョインして作った巨大なマーケティングテーブル、100枚近いダッシュボード、そして分析依頼が来るたびに15〜20枚のスライドをスクラッチで作り、アナリスト1人が1週間かけて仕上げる——そんな状態です。
データの取り込みはツールごとにサイロ化し、新しい要件が来るたびにハードコーディングで対応していました。結果として、CRM・Web解析・マーケティングオートメーション・広告・ノートブック・ダッシュボードがバラバラに散らばり、Slackには「なぜダッシュボードが遅いのか」「どの数値が正しいのか」「なぜ数字が合わないのか」という問い合わせが絶えなかったといいます。
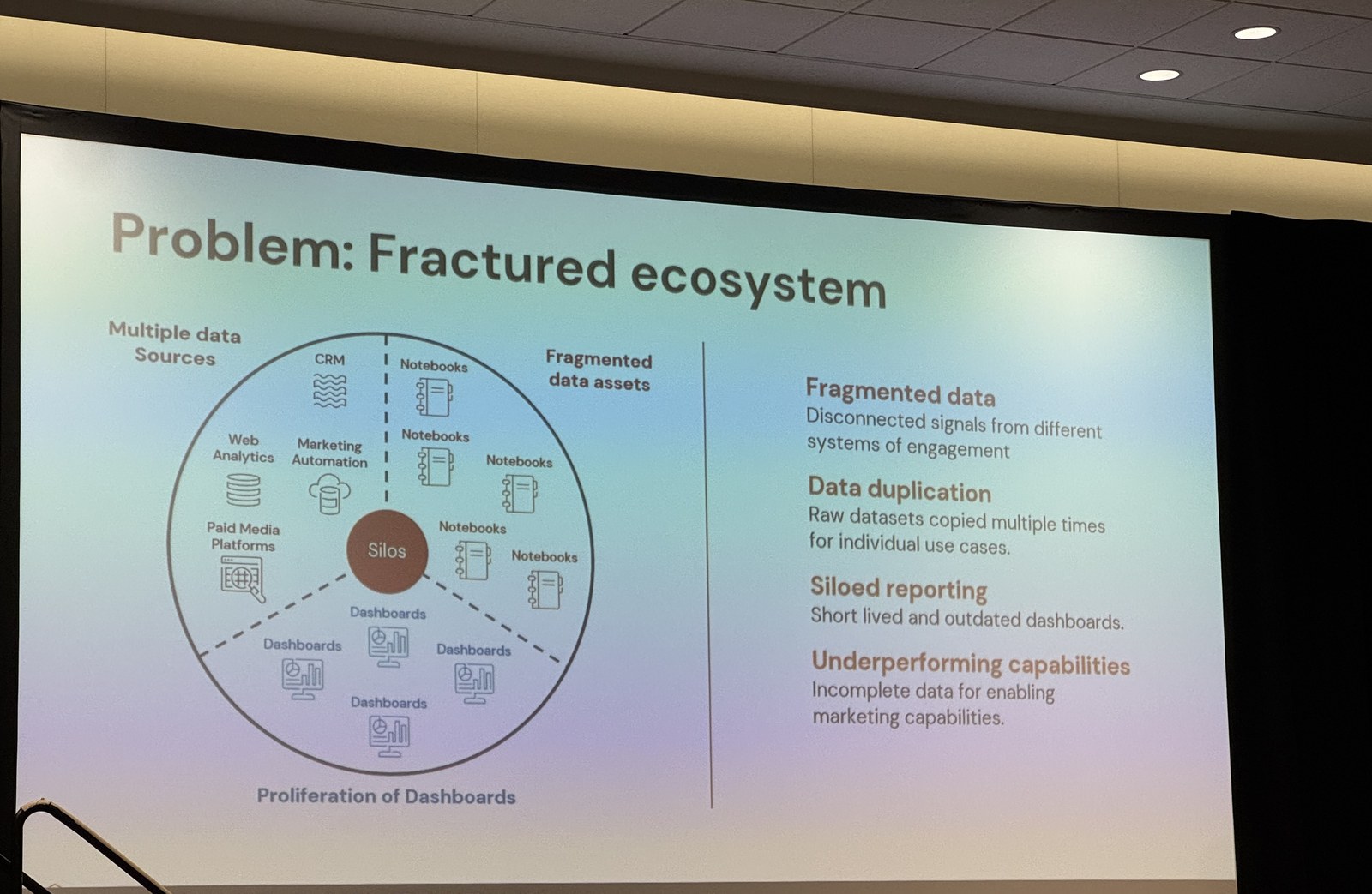
同じKPIなのに、ダッシュボードごとに違う数字
象徴的だったのが「ひとつの指標に、3つの定義」という問題です。同じ「Active Pipeline(活動中の商談)」を見ているはずなのに、ダッシュボードAでは4,200万ドル、Bでは5,800万ドル、Cでは5,100万ドル。アナリストごとにビジネスロジックの実装が微妙に違い、定義が静かにずれていく——いわゆるMetric Drift(メトリクスのドリフト)が起きていました。
「どれが正しいのか」に答えられないダッシュボードは、いくら数を増やしても信頼されません。チームはここで、表示を直すのではなく、指標の定義そのものを一箇所で管理する方向に舵を切ります。

3つの役割で、レイクハウスを土台から作り直す
再構築は一夜では起きません。チームは「データアーキテクチャ」「データエンジニアリング」「インサイト&ビジュアライゼーション」という3つの役割で構成する統一アナリティクスチームを編成し、土台から積み上げ直しました。

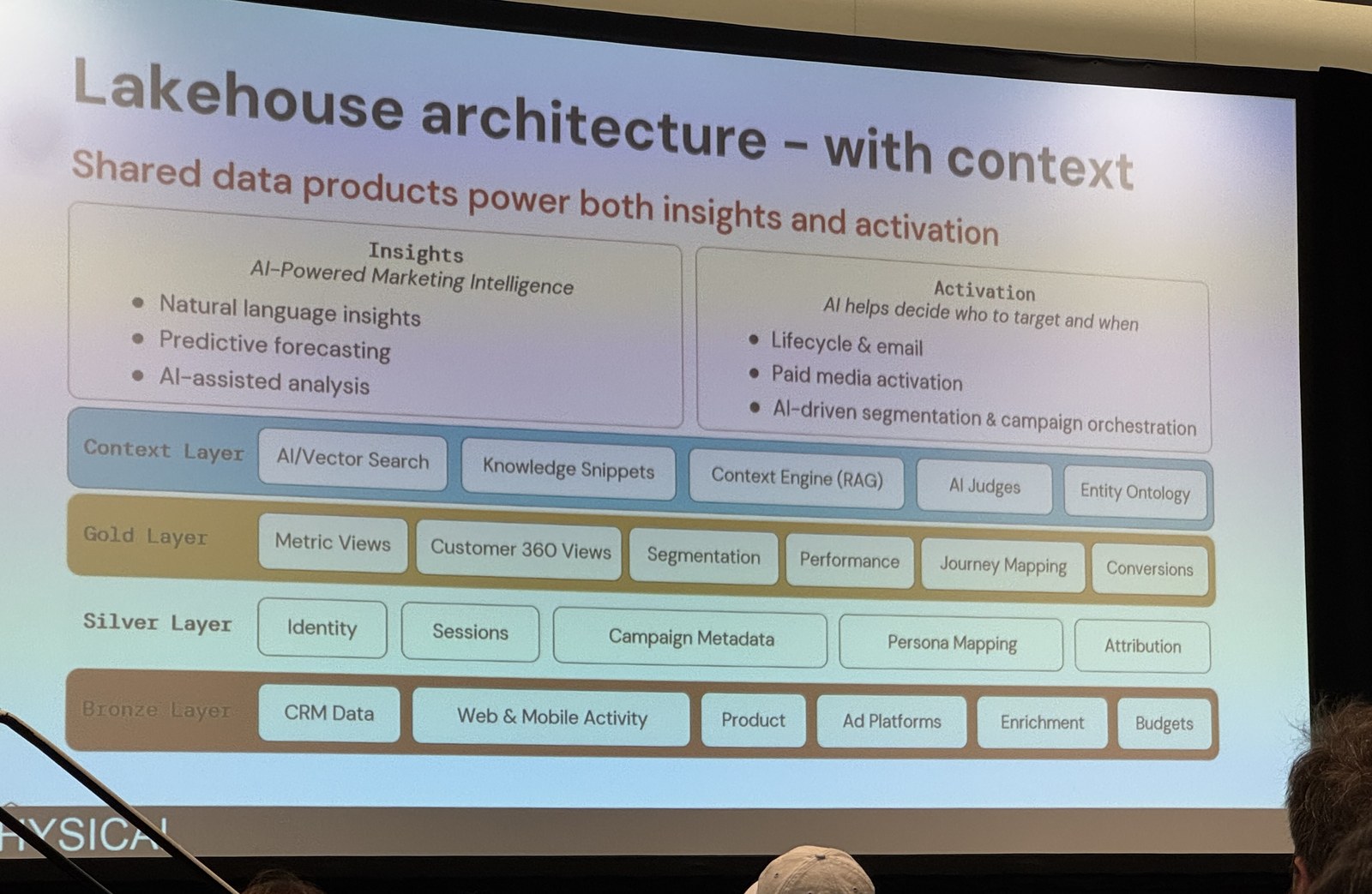
土台にはMedallionアーキテクチャを採用。Bronze・Silver・Goldの各レイヤーを整え、ゴールドレイヤーにクリーンなデータファウンデーションを置き、その上にレポート用テーブルを構築します。そして冒頭のMetric Drift対策の核になったのが、Business Semantic Layer(Metric Views)です。「Greenfield MQL」や「Active Type 1 Pipeline」といった複雑なビジネスロジックを、Unity Catalog上のメトリクスビューに集約し、ガバナンスの効いた定義として一元管理する。これにより、どのダッシュボードから見ても数字が一致するようになりました。
さらにこの構成は、AI活用を見据えてGold層の上にContext Layer(文脈レイヤー)を重ねている点が特徴的でした。Vector Searchやナレッジスニペット、RAGを担うContext Engine、出力を評価するAI Judges、エンティティのオントロジーといった要素を載せ、AIがビジネス用語を正しく理解できる土台を用意しています。モジュラーな構成にしたことで、変更も以前より速く反映できるようになったとのことです。
自然言語でデータに尋ねる:Marketing Lens と Genie
土台が整ったところで、表側のダッシュボードもTableauからDatabricksのAI/BIおよびDatabricks Appsへ移行します。出来上がったのが「Marketing Lens」というアプリで、CMOビュー、Demand Gen、Brand、Summitなど、トピックごとに専用タブを持たせた構成です。
ここにGenie(AI/BI)を埋め込み、ユーザーが自然言語でアドホックに分析できるようにしました。Genieの効きどころは、ただのテキスト→SQL変換ではない点にあります。GenieがUnity Catalogのセマンティクスレイヤーを参照するため、「正しいパイプライン」のようなビジネス用語の意味を自動的に理解し、誰が聞いても一貫した回答を返す。定義の一元管理が、そのままAIの回答品質に効いてくる構造です。

1週間かかったレポートを、毎週月曜に自動配信:Genie Code
「アナリストが1週間かけて作る成果物」だった定例レポートは、Genie Codeで自動化されました。流れはシンプルです。
- まず自然言語で、DatabricksのカラーパレットやGoogle Docのテンプレートを指定し、ブランドに沿った体裁を指示する
- ガバナンスされたゴールドテーブルから、地域ごとのKPI(pipeline、MQL、NNN、U2など)を引き出す。診断は「組み立てる」のではなく「生成される」
- 完成したレポートは、毎週月曜に地域ごと自動生成され、各地域リードのinboxにGoogle Docとして届く
以前は1週間かかっていた作業が、毎週月曜の朝には4地域すべてのリードの手元に揃っている。四半期レポートのデッキ作成でも、Genieから得たインサイトを組み込んで活用しているそうです。

データに「文脈」を与えるAIエージェント
分析がスケールしなかったもうひとつの理由は「文脈の欠如」でした。「誰に届いたのか」「何に反応したのか」「この結果は良いのか悪いのか」——こうした問いに毎回手作業で文脈を補っていたのです。そこでチームは、データにリッチなメタデータを付与する2つのエージェントを構築しました。
- Agent Atlas(誰に届いたか):職種・役職をLLMでペルソナに分類し、Web・キャンペーン・製品利用・イベントを横断したエンゲージメント信号を評価。関心度や反応確度で個人とアカウントを分類し、静的なセグメンテーションを動的なオーディエンス・インテリジェンスに置き換える
- Agent Tagatha(何に反応したか):動画・Web・PDF・ブログなど1万件超のアセットを要約・タグ付けし、ビジネス分類の変化に合わせて過去分も再タグ付け。アセット間の意味と関係を捉えるセマンティック埋め込みを作り、一貫したプログラム分類でパーソナライズを支える

加えて、スライド作成を担うAgent Decklyも紹介されていました。スライドテンプレートを読み込み、必要なテーブルやプレースホルダを自動で認識して、データを流し込んでデッキを埋めてくれるエージェントです。
月曜の朝、30分で終わる一日
これらが揃った「導入後の月曜の朝」が、Before/Afterを一枚で物語っていました。
- 8:00 メールを開く:自動レポートが「MQL/SALが前四半期比50%減」とフラグ
- 8:05 Marketing Lensを開く:Demand Funnelをクリックし、KPIで下落を確認、Deep Diveへ
- 8:10 AI/BIダッシュボードで、Unknown Disposition MQLの増加を把握
- 8:15 Genieに質問:「AMERでMQLフォローアップ量が最も少なかったチームは?」→ 即答
- 8:20 Agent Decklyでインサイト入りのデッキを生成
- 8:30 推奨アクションを添えて、デッキをXDRリードへ転送
ここまで約30分。旧来は「1週間+アナリストへのチケット」が必要だった一連の流れが、月曜の朝のうちに片づくようになりました。

学びと、これから
セッションの締めくくりに挙げられた学びは3点でした。
- 顧客データは、まず統合されていなければならない
- AIを効かせるには、文脈を備えたデータプロダクトが必要になる
- AIインターフェースが、眠っていたエンタープライズデータを解放する
そして今後の方向性として示されたのが、ステークホルダー向けのAIによるリアルタイム推奨の強化、自動診断テンプレートの拡充、そしてクローズドループ・アクティベーションでした。いまはまだループの中に人が介在していますが、将来的にはAIが自律的にアクションを実行し、人間は確認・承認に回る形を目指すといいます。さらに、顧客向けにも同様のデータファウンデーション(Customer Lake)を展開し、サイエンスチームをGenieの利用に巻き込んでいく構想も語られました。

ダッシュボードの枚数ではなく、意思決定までの距離を縮める。そのために、指標の定義を一元化し、データに文脈を持たせ、AIが扱える土台を整える——順番のあるこの積み上げ方こそが、このセッションのいちばんの示唆だったように思います。